






论文链接:https://arxiv.org/pdf/2412.14475
MegaPairs: Massive Data Synthesis For Universal Multimodal Retrieval
1. 摘要
本论文针对多模态检索任务中训练数据稀缺的问题,提出了一种新型数据合成方法——MegaPairs。通过利用开源的视觉语言模型(VLMs)和大规模开放域图像,论文设计了一个数据合成流程,从海量图像中挖掘相关图像对,并借助多种相似性模型生成伪注释,构成一个包含 2600 多万实例的大规模合成数据集。实验结果表明,使用 MegaPairs 进行微调的多模态检索模型在多个 composed image retrieval (CIR) 基准上实现了零样本(zero-shot)下的最先进性能,并且在下游任务微调后仍保持显著优势。
2. 引言与背景
2.1 多模态检索的现状
- 多模态检索任务:旨在跨文本与图像两种模态满足用户信息需求,应用场景包括图像搜索、视觉问答(VQA)、检索增强生成(RAG)等。
- 预训练模型:现有模型如 CLIP、ALIGN 和 SigLIP 均依赖于图文匹配任务预训练,虽具备一定的检索能力,但在构成复杂检索查询(例如 composed image retrieval)和多模态文档检索任务上存在不足。
2.2 数据稀缺与指令调优
- 指令调优:在语言模型和多模态嵌入模型中,通过细化预训练模型来提升任务适应性。但大规模指令调优数据集往往由少数实验室私有,且数据量不足。
- 数据合成的必要性:为了解决数据规模、质量、和多样性不足的问题,论文提出利用开源图像语料与 VLMs 自动生成合成数据,进而构建一个大规模、异质性高的数据集——MegaPairs。
3. 方法论
论文的核心贡献在于提出了 MegaPairs 数据合成方法,以及基于此数据训练的多模态检索模型 MMRet。主要内容包括以下几个部分:
3.1 MegaPairs 数据合成
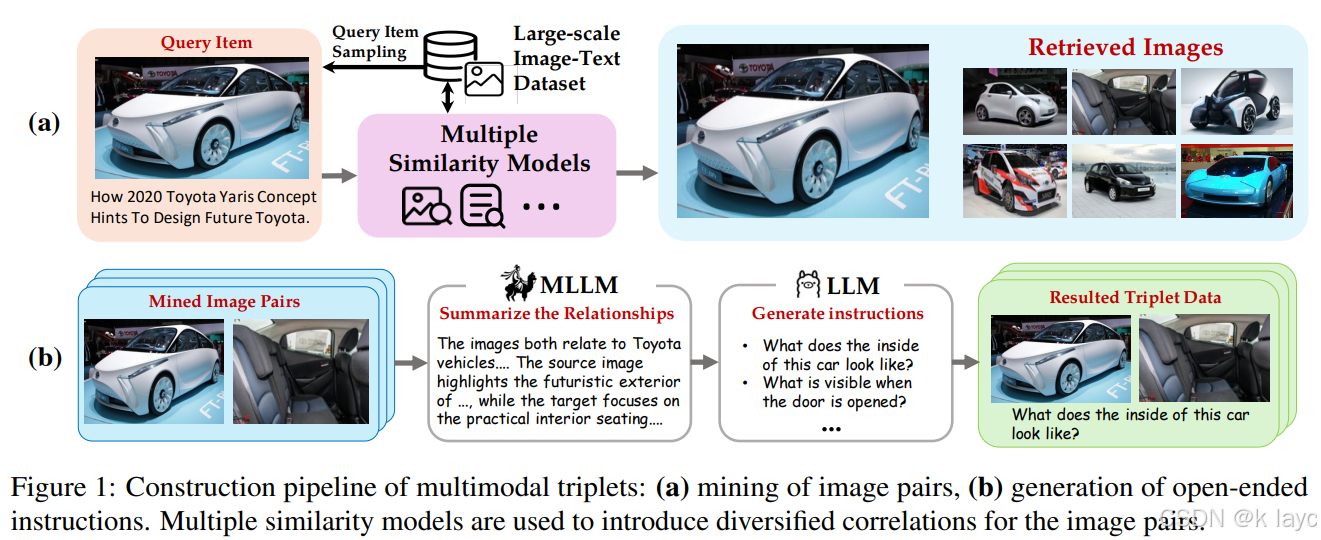
3.1.1 挖掘相关图像对
- 目标:从大规模开放域图像库中采样出具有多样性和相关性的图像对。
- 相似性模型:使用三种不同的相似性模型来捕捉异质性:
- 视觉语义相似性:使用 CLIP 的图像编码器衡量图像间的语义相关性。
- 视觉模式相似性:使用 DINO(或 DINOv2)编码器捕捉图像的视觉模式(例如纹理、色调)。
- 文本描述相似性:利用 CLIP 的文本编码器对图像对应的 caption 进行相似性计算。
- 采样策略:仅选择相似性得分处于 ( 0.8 , 0.96 ) (0.8, 0.96) (0.8,0.96) 区间的图像对,以避免弱关联和近重复的情况。
3.1.2 生成开放式指令
- 自动注释流程:
- 首先利用多模态大模型(MLLM)对每个图像对 ( I q , I t ) (I_q, I_t) (Iq,It) 生成详细描述 D i D_i Di,描述二者的共同点和差异。
- 随后,利用大语言模型(LLM)将描述 D i D_i Di 转换为开放式文本指令 T q → t T_{q \rightarrow t} Tq→t,该指令描述了如何从查询图像 I q I_q Iq 检索到目标图像 I t I_t It。
- 生成多样性:每个图像对至少生成三个不同的指令,同时引入硬负样本(hard negatives)以增加数据多样性。
3.1.3 数据规模与优势
- 数据规模:通过该流程生成了超过 26,235,105 个图像对及对应的指令。
- 优势:实验显示,仅使用 MegaPairs 的少量子集(例如 500K 个实例)便可使微调模型性能超越使用 36.7M 实例的其他方法(如 MagicLens),大大提高了数据效率和训练效果。
3.2 MMRet 模型
为验证 MegaPairs 数据的有效性,论文提出了多模态检索模型 MMRet,包括两种架构:CLIP-based MMRet 和 MLLM-based MMRet。
3.2.1 CLIP-based MMRet
- 双编码器架构:
- 图像编码器
Φ
I
\Phi_I
ΦI 用于计算图像嵌入:
e i = Φ I ( I ) e_i = \Phi_I(I) ei=ΦI(I) - 文本编码器
Φ
T
\Phi_T
ΦT 用于计算文本嵌入:
e t = Φ T ( T ) e_t = \Phi_T(T) et=ΦT(T)
- 图像编码器
Φ
I
\Phi_I
ΦI 用于计算图像嵌入:
- 融合策略:采用元素级加法融合图像与文本的嵌入,得到组合嵌入:
e i t = Φ I ( I ) + Φ T ( T ) e_{it} = \Phi_I(I) + \Phi_T(T) eit=ΦI(I)+ΦT(T)
3.2.2 MLLM-based MMRet
- 融合模型:将视觉编码器与语言模型直接融合,输入图像和文本后将其转换为交织的 token 序列。
- 任务特定提示:采用形如
⟨ i n s t r u c t ⟩ { t a s k _ i n s t } ⟨ q u e r y ⟩ { q t } { q i } [ E O S ] \langle instruct \rangle \; \{task\_inst\} \; \langle query \rangle \; \{qt\} \; \{qi\} \; [EOS] ⟨instruct⟩{task_inst}⟨query⟩{qt}{qi}[EOS]
的格式,将任务说明与查询内容结合,从而利用 [EOS] 标记的最后隐藏状态作为最终嵌入。
3.3 多模态对比学习
为了训练 MMRet 模型,论文采用了标准的 InfoNCE 损失函数,其公式为:
L
=
−
1
∣
Q
∣
∑
q
i
∈
Q
log
exp
(
e
q
i
⋅
e
c
i
+
/
τ
)
∑
c
j
∈
C
exp
(
e
q
i
⋅
e
c
j
/
τ
)
L = -\frac{1}{|Q|} \sum_{q_i \in Q} \log \frac{\exp(e_{q_i} \cdot e_{c^+_i} / \tau)}{\sum_{c_j \in C} \exp(e_{q_i} \cdot e_{c_j} / \tau)}
L=−∣Q∣1qi∈Q∑log∑cj∈Cexp(eqi⋅ecj/τ)exp(eqi⋅eci+/τ)
其中:
- Q Q Q 表示批次中所有查询样本;
- e q i e_{q_i} eqi 和 e c i + e_{c^+_i} eci+ 分别为查询样本和其正样本的嵌入;
- C C C 为批次中所有候选样本集合;
- τ \tau τ 为温度超参数。
4. 实验与结果
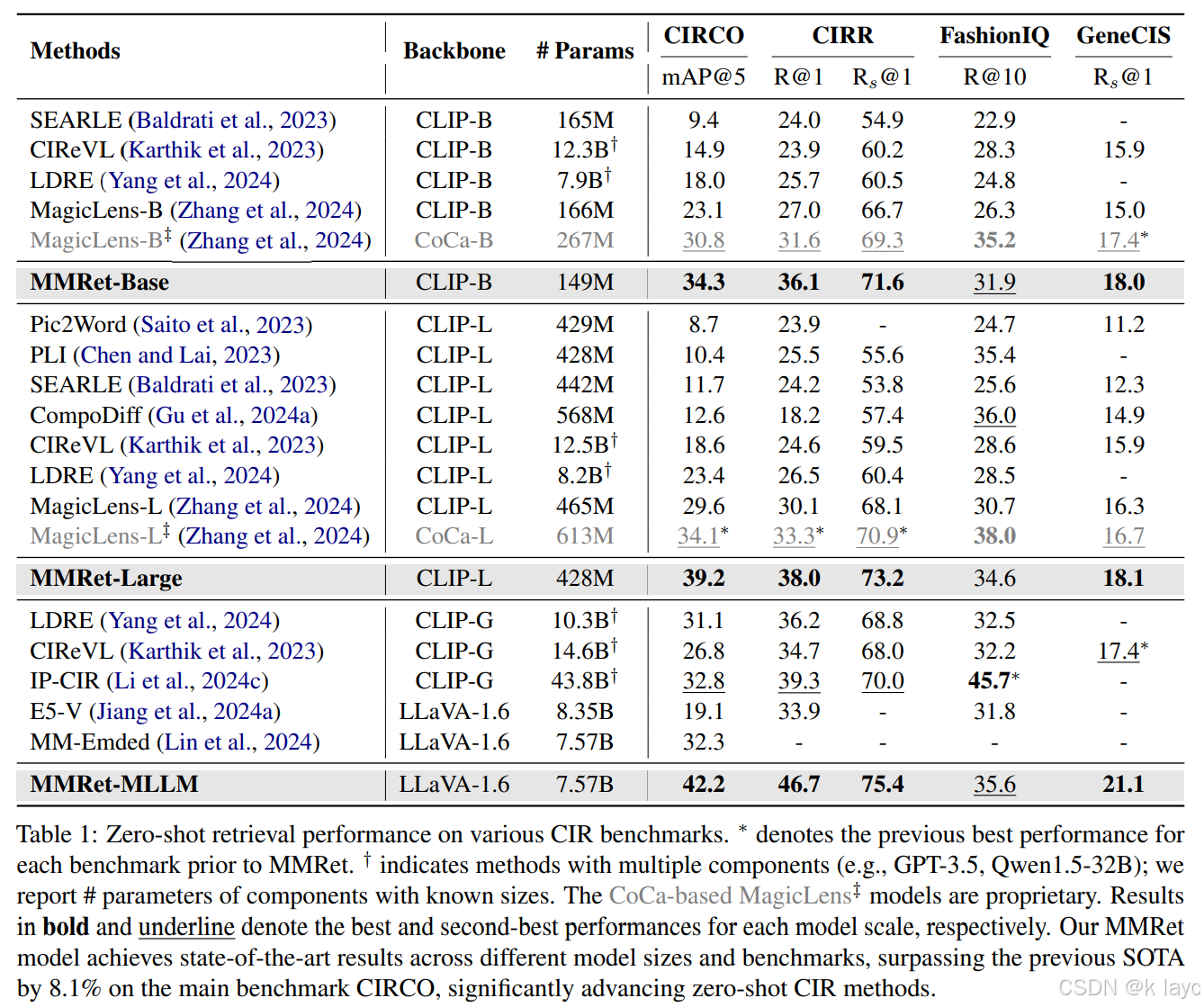
4.1 零样本(Zero-Shot)评估
- 评估基准:论文在四个 composed image retrieval (CIR) 基准上进行了零样本评估,分别为 CIRCO、CIRR、FashionIQ 和 GeneCIS。
- 主要发现:
- MMRet 模型在这些基准上均实现了最新的零样本性能,显著优于以往使用更大规模数据集训练的模型。
- 例如,在 CIRCO 基准上,MMRet-MLLM 模型的 mAP@5 达到了 42.2%,相比 MagicLens-L 提升了 8.1 个点。
4.2 下游任务评估(MMEB 基准)
- MMEB:一个包含 36 个数据集的庞大多模态嵌入评估基准,覆盖分类、视觉问答、检索和接地任务。
- 实验结果:
- 在监督微调(Supervised Fine-tuning)条件下,基于 MegaPairs 数据训练的 MMRet-MLLM 模型在总体 Precision@1 上达到了 64.1%,相较于 VLM2Vec(LLaVA-1.6 版本)提升了 9.1%。
- 模型在 IND(in-distribution)和 OOD(out-of-distribution)数据集上均表现出优异的泛化能力。
4.3 数据集质量与消融实验
4.3.1 数据规模与质量
- 性能随数据量提升:训练数据规模从 0.5M 到 26M 数据对,模型在各个基准上的性能均呈上升趋势,验证了 MegaPairs 的高质量和可扩展性。
- 对比:即使仅使用 MegaPairs 的 0.5M 数据,其性能已超过 MagicLens 使用的 36.7M 数据,显示出数据效率优势。
4.3.2 硬负样本的重要性
- 硬负样本策略:在构造图像对时,为每对正样本引入额外的硬负样本,有助于训练模型更准确地区分相关性。
- 实验结果:使用硬负样本策略训练的模型在所有基准上的表现均有明显提升。
4.3.3 数据对构造策略
- 多策略结合:论文比较了基于视觉、文本及两者结合的多种图像对构造策略,结果显示结合三种策略能获得最优性能,这说明异质性信息对于构建高质量数据集至关重要。
5. 结论
-
主要贡献:
- 提出 MegaPairs 数据合成方法,利用开源图像语料与多种相似性模型生成大规模、多样化的多模态检索数据。
- 基于 MegaPairs 训练的多模态检索模型 MMRet 在零样本和下游任务上均取得了最新最好的性能,显著优于现有数据集和方法。
- 数据合成策略不仅大幅提高了数据规模和质量,而且显著降低了数据获取成本,为未来多模态检索领域的研究提供了坚实基础。
-
未来方向:
- 探索更多图像对挖掘和负样本采样策略,以进一步提升数据集的多样性和质量。
- 扩展 MegaPairs 数据集到其他模态(如视频、3D 数据)以支持更广泛的多模态任务。
- 与最新的模型架构和训练方法结合,进一步提升多模态嵌入与检索系统的性能。
6. 总结
论文 MegaPairs: Massive Data Synthesis For Universal Multimodal Retrieval 通过提出一种基于开源图像语料与多模态模型联合构建大规模合成数据集的方法,解决了当前多模态检索任务中数据稀缺、质量不足和多样性有限的问题。实验表明,利用 MegaPairs 训练的 MMRet 模型在零样本和监督微调条件下均能实现最先进的检索性能,展示了数据合成方法在通用多模态检索中的巨大潜力。该工作为未来进一步发展更高效、低成本的多模态检索系统奠定了基础。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









