






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
一句话总结
本文研究如何有效利用abstain learning来有效检测城市自动驾驶系统中经常遭遇的异常物体,其提出PEBAL:一个融合像素级别弃权学习abstention learning 和能量模型的异常/OOD检测系统,性能表现SOTA!代码已经开源!
PEBAL
Pixel-wise Energy-biased Abstention Learning for Anomaly Segmentation on Complex Urban Driving Scenes

单位:阿大 新加坡管理大学
论文:https://arxiv.org/abs/2111.12264
代码:https://github.com/tianyu0207/PEBAL
最近语义分割方法向我们展示了在复杂的城市驾驶场景中精准的像素级别预测, 但这些方法通常不能正确识别出偏离训练中的异常物体。解决这个问题对自动驾驶车辆的道路安全至关重要。比较典型的异常物体可以是道路中间的一块大石头或者是一个野生动物。这些物体因为没有在训练中见过吗,所以会被错误地预测为道路的一部分,从而导致潜在的致命的交通事故。
之前的论文通常依赖于分类不确定性或图像重建去解决城市驾驶道路的像素级别异常检测。但是我们发现这项方法都有各自的问题。比如基于不确定性的方法依据的是当样本接近分类决策边界时,就会出现分类不确定性,但是, 我们往往不能保证所有的异常现象都会接近分类边界。此外,接近分类边界的样本可能根本不是异常点,而只是一些比较难以区分的正常样本。因此,这些基于不确定性的方法可能检测到大量的假阳性和假阴性的样本。例如,这些方法有时会对树木或灌木丛进行错误分类从而错误的产生高不确定性。基于重构的方法通常会增加了一个额外的网络来进行重构。异常像素点则通过输入图像和重构图像的差异来判断。这种方法不仅依赖于对正常物体精确的语义分割而且他们还需要一个额外的重建网络。这使得网络很难训练,而且在实时自动驾驶系统中运行效率很低。此外,每当输入分布发生变化时,这种方法都需要重新训练,从而限制了它们在现实世界系统中的适用性。为了解决这些问题, 我们提出了一种有效的快速的像素级异常检测模型PEBAL。这种新型的模型除了学习正常物体们的语义分割以外的,还直接学习了一个异常像素类别。它是通过联合优化一个新的像素级别的异常弃权学习abstention learning(PAL)和一个像素级别的能量的模型(EBM)来识别异常像素点。最初的弃权学习(AL)是为了学习图像级别的异常类。这在像素级别的异常分割任务中受到了很大的挑战。这是因为最初的AL模型对所有像素的输入都一视同仁,用一个预先定义好的固定惩罚参数来规范异常分类。而在复杂的驾驶场景中,我们通常需要对不同的像素进行不同的惩罚。显然一个固定的惩罚参数是不适合的。例如,小(远)物体的像素点与大(近)物体的像素点都需要不同的惩罚参数。PEBAL旨在通过学习一个自适应的基于能量模型的动态惩罚参数。这样学习到的惩罚参数与EBM共同优化。此外,我们对学习的平稳性和稀疏性进行了限制,将局部和全局的依赖性首次纳入到像素级的异常检测之中。

主要贡献
-We propose the pixel-wise energy-biased abstention learning (PEBAL) that jointly optimises a novel pixel-wise anomaly abstention learning (PAL) and energy-based models (EBM) to learn adaptive pixel-level anomalies. PEBAL mutually reinforces PAL and EBM in detecting anomalies, enabling accurate segmentation of anomalous pixels without compromising the segmentation of inlier pixels。
-We introduce a new pixel-wise energy-biased penalty estimation, which can learn adaptive energy-based penalties to highly varying pixels in a complex driving scene, allowing a robust detection of small/distant and blurry anomalous objects。
-We further refine our PEBAL training, using a novel smoothness and sparsity regularisation on anomaly scores to consider the local and global dependencies of the pixels, enabling the reduction of false positive/negative anomaly predictions.

实验结果
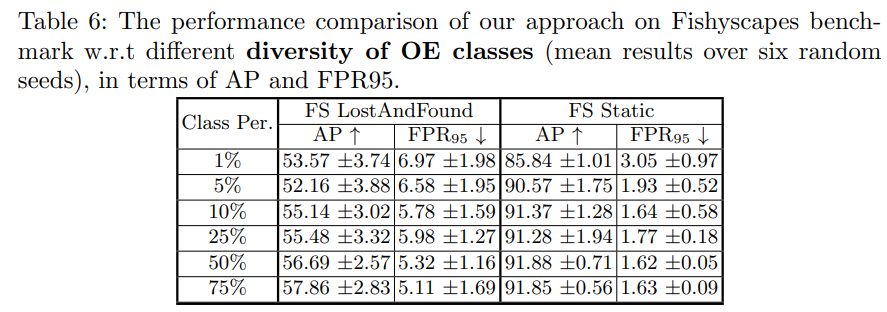
实验结果表明,我们的方法在多个异常分割数据集上明显优于其他网络,并在准确性和效率之间取得了良好的平衡。例如,在 Fishyscapes的公榜上,PEBAL在AP方面的准确度比其他不需要重新训练和添加额外网络的方法分别高10%-40% (LostAndFound)和40% to 50% (Static)。
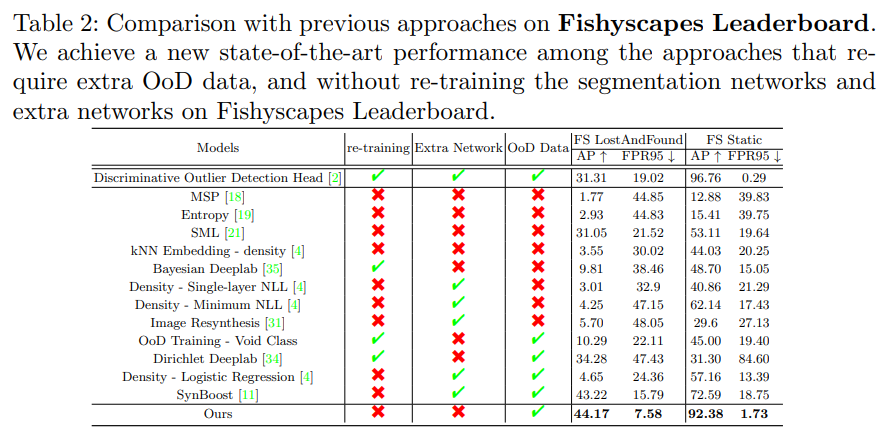

为了证明我们方法的通用性,我们也测试了利用Resnet101作为backbone的分割模型, 并同样取得了SOTA的结果。
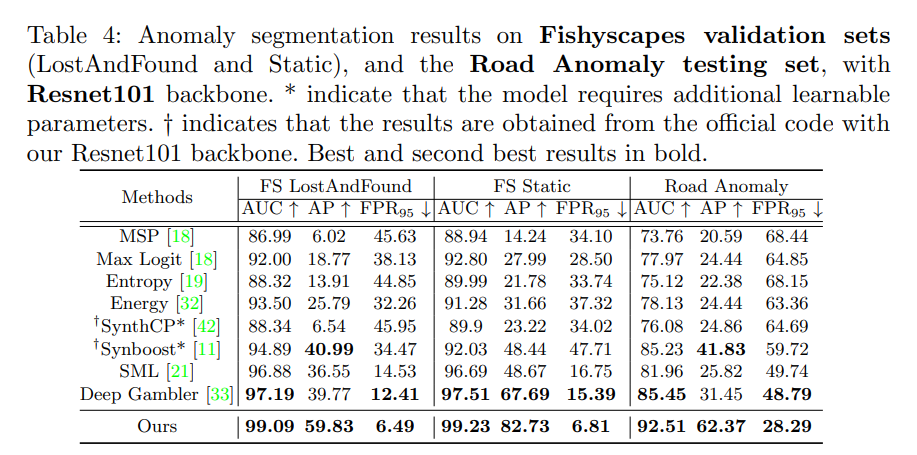
最后我们证明了我们的方法并不受限于outlier exposure (OE)的数量和种类限制, 在极少OE数量和类别的情况下我们也能表现SOTA。
点击进入—> CV 微信技术交流群
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看














 1366
1366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









