






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
在CVer微信公众号后台回复:动作捕捉,可以下载本论文pdf、代码和数据集,学起来!
转载自:新智元 | 编辑:LRS 好困
【导读】想要快速制作角色动画,但是没有动捕设备?快来试试SMPLer-X!
人体全身姿态与体型估计(EHPS, Expressive Human Pose and Shape estimation)虽然目前已经取得了非常大研究进展,但当下最先进的方法仍然受限于有限的训练数据集。
最近,来自南洋理工大学S-Lab、商汤科技、上海人工智能实验室、东京大学和IDEA研究院的研究人员首次提出针对人体全身姿态与体型估计任务的动捕大模型SMPLer-X。该工作使用来自不同数据源的多达450万个实例对模型进行训练,在7个关键榜单上均刷新了最佳性能。
SMPLer-X除了常见的身体动作捕捉,还能输出面部和手部动作,甚至对体型做出估计。

论文链接:https://arxiv.org/abs/2309.17448
项目主页:https://caizhongang.github.io/projects/SMPLer-X/
凭借大量数据和大型模型,SMPLer-X在各种测试和榜单中表现出强大的性能,即使在没有见过的环境中也具有出色的通用性:
1. 在数据扩展方面,研究人员对32个3D人体数据集进行了系统的评估与分析,为模型训练提供参考;
2. 在模型缩放方面,利用视觉大模型来研究该任务中增大模型参数量带来的性能提升;
3. 通过微调策略可以将SMPLer-X通用大模型转变为专用大模型,使其能够实现进一步的性能提升。

扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文强推!

总而言之,SMPLer-X探索了数据缩放与模型缩放(图1),对32个学术数据集进行排名,并在其450万个实例上完成了训练,在7个关键榜单(如AGORA、UBody、EgoBody和EHF)上均刷新了最佳性能。
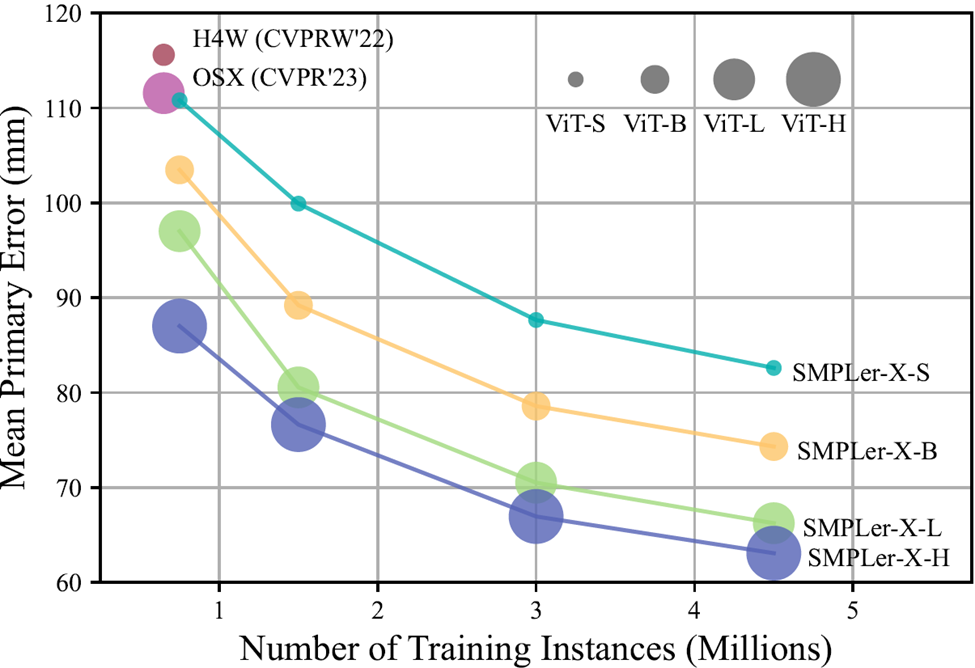 Figure 1 增大数据量和模型参数量在降低关键榜单(AGORA、UBody、EgoBody、3DPW 和 EHF)的平均主要误差(MPE)方面都是有效的
Figure 1 增大数据量和模型参数量在降低关键榜单(AGORA、UBody、EgoBody、3DPW 和 EHF)的平均主要误差(MPE)方面都是有效的
现有3D人体数据集的泛化性研究
研究人员对32个学术数据集进行了排名:为了衡量每个数据集的性能,需要使用该数据集训练一个模型,并在五个评估数据集上评估模型:AGORA、UBody、EgoBody、3DPW和EHF。
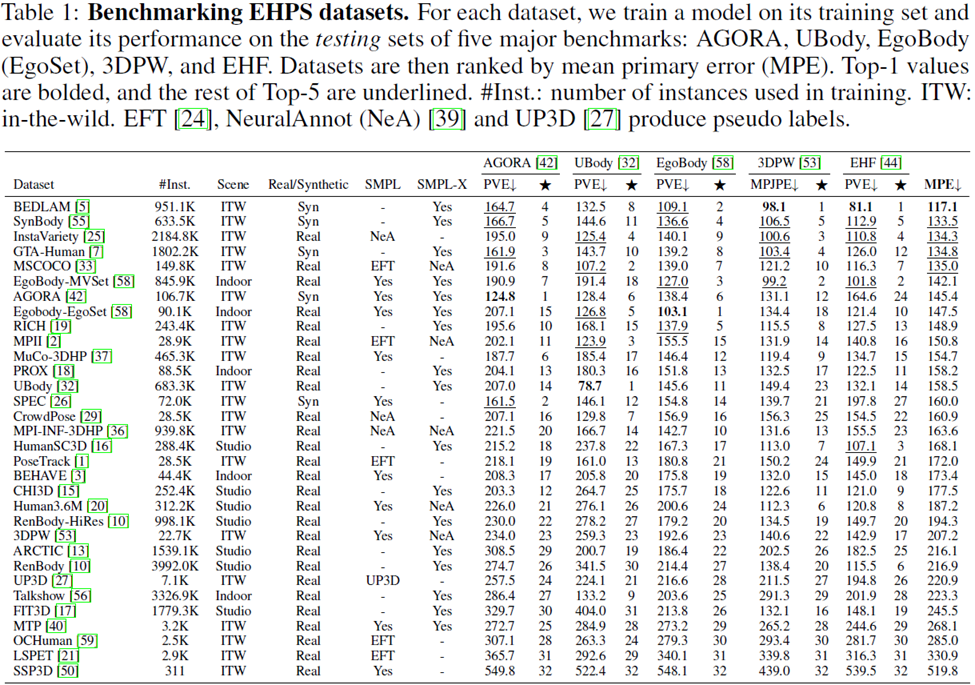
表中还计算了平均主要误差(Mean Primary Error, MPE),以便于在各个数据集之间进行简单比较。
从数据集泛化性研究中得到的启示
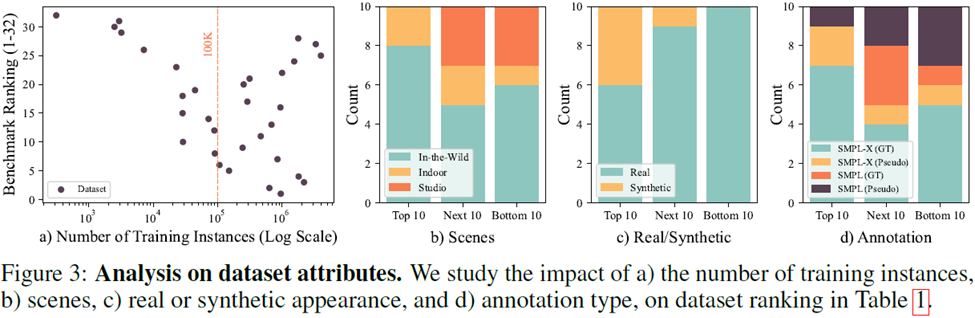
从大量数据集的分析(图3)中,可以得出以下四点结论:
1. 关于单一数据集的数据量,10万个实例数量级的数据集用于模型训练可以得到较高的性价比;
2. 关于数据集的采集场景,In-the-wild数据集效果最好,如果只能室内采集,需要避免单一场景以提升训练效果;
3. 关于数据集的采集,数据集排名前三中有两个是生成数据集,生成数据近年来展现出了强大的性能。
4. 关于数据集的标注,伪标签的数据集在训练中也发挥了至关重要的作用。
动捕大模型的训练与微调
当前最先进的方法通常只使用少数几个数据集(例如,MSCOCO、MPII和Human3.6M)进行训练,而这篇文章中探讨使用了更多数据集。
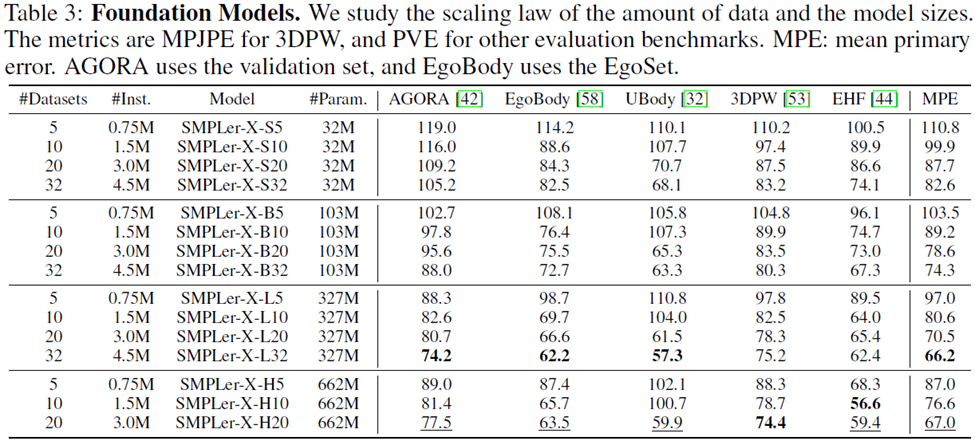
在始终优先考虑排名较高的数据集的前提下使用了四种数据量:作为训练集的5、10、20和32个数据集,总大小为75万、150万、300万和450万实例。
除此之外,研究人员也展示了低成本的微调策略来将通用大模型适应到特定场景。
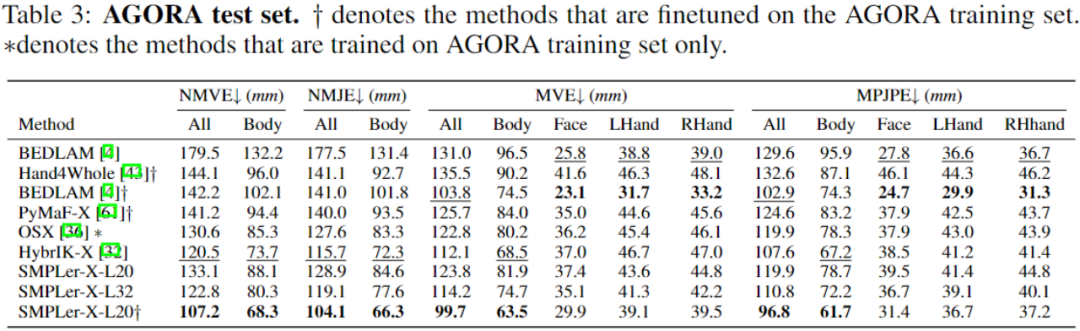
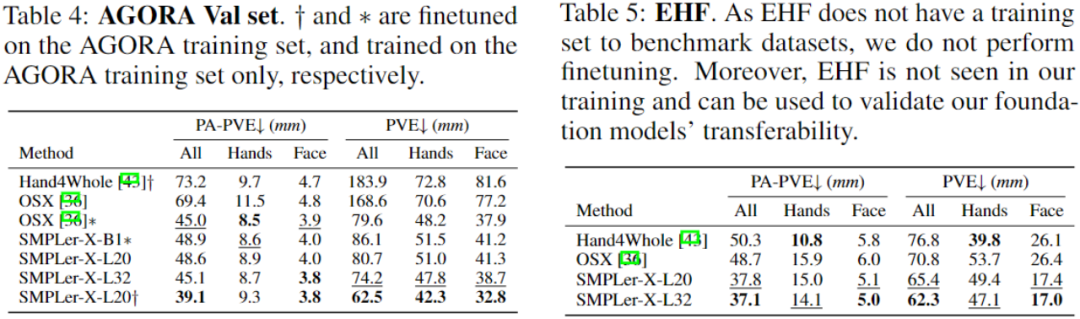
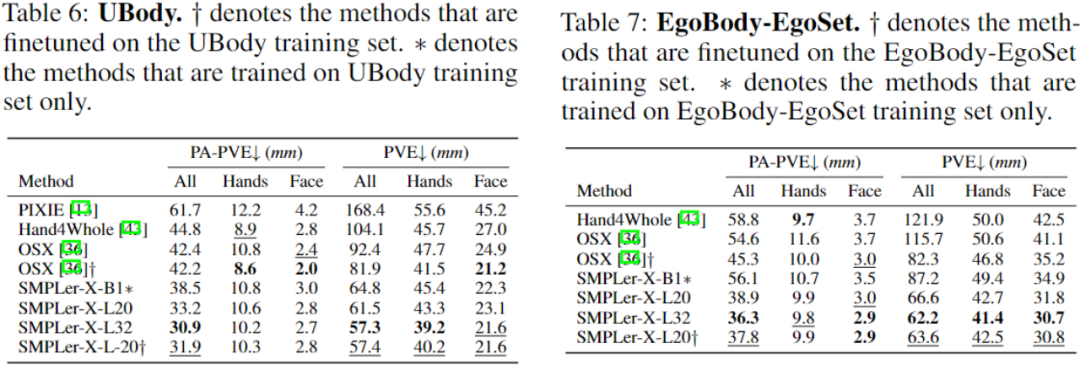
上表中展示了部分主要测试,如AGORA测试集(表3)、AGORA验证集(表4)、EHF(表5)、UBody(表6)、EgoBody-EgoSet(表7)。
此外,研究人员还在ARCTIC和DNA-Rendering两个测试集上评估了动捕大模型的泛化性。
研究人员希望SMPLer-X能带来超出算法设计的启发,并为学术社区提供强大的全身人体动捕大模型。
代码和预训练模型都已开源,更多详情请访问项目主页:https://caizhongang.github.io/projects/SMPLer-X/
结果展示



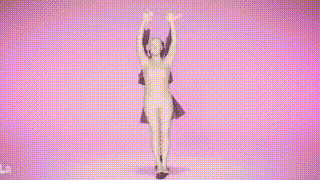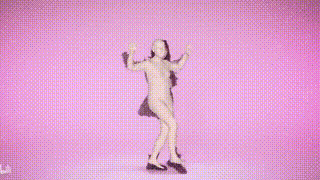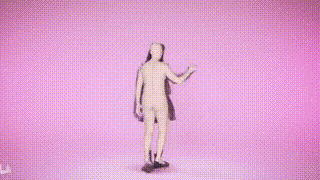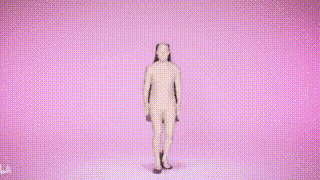




参考资料:
https://arxiv.org/abs/2309.17448
在CVer微信公众号后台回复:动作捕捉,可以下载本论文pdf、代码和数据集,学起来!
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集计算机视觉和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-计算机视觉或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
















 2224
2224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









