






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer444,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文搞科研,强烈推荐!


论文地址:https://arxiv.org/abs/2306.07520
代码地址:https://github.com/hwz-zju/Instruct-ReID
引言
行为重识别(person re-identification, ReID)在安防领域有广泛与成熟的应用。不同的任务场景对ReID提出不同的需求,从而衍化出多种不同类型的ReID任务,例如针对较长周期识别的Clothes Changing ReID(CC-ReID)、利用文本描述进行识别的Text-to-Image ReID(T2I-ReID)等等。而由于现有ReID模型大多只能处理单任务,多种任务就需要多个模型来解决,给实际使用带来了额外训练、部署的开销,不方便大规模的落地应用。
那么能够用一个模型实现所有主流ReID任务呢?
答案是可以。文章提出了一种统一的ReID模型IRM(Instruct ReID Model),一网打尽6种ReID任务,包括:
traditional ReID
clothes-changing ReID (CC-ReID)
clothes template based clothes-changing ReID (CTCC-ReID)
visible-infrared ReID (VI-ReID)
text-to-image ReID (T2I-ReID)
language-instructed ReID (LI-ReID)
并在6个任务的10个数据集上均取得了state-of-art的结果,见图1(b)。

文章三大亮点:
提出instruct-ReID任务,实现一个任务兼容六种主流ReID任务
首个面向统一ReID范式的benchmark
一个模型在多种主流ReID任务上取得最优性能
Benchmark
文章提出了一个新的benchmark,OmniReID,用于instruct-ReID任务的训练与测试。
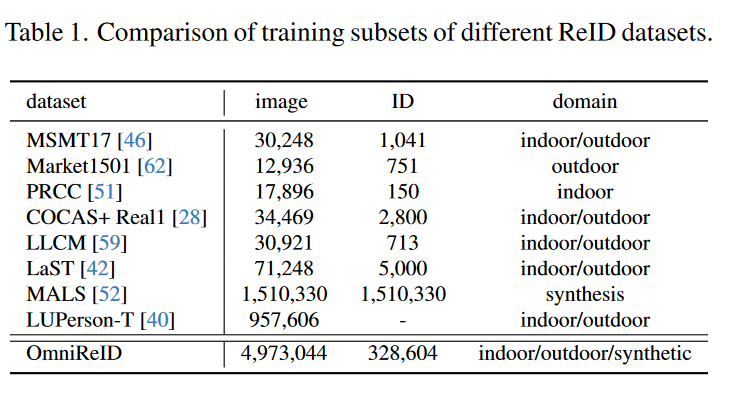
OmniReID的训练集基于12个公开数据集制作而成,共包含497万张图像与32.8万个体。与其他ReID benchmark的训练集对比见表1.
作者额外生成了instruction数据以构建CTCC-ReID与LI-ReID训练数据。以下为instruction制作的相关过程。
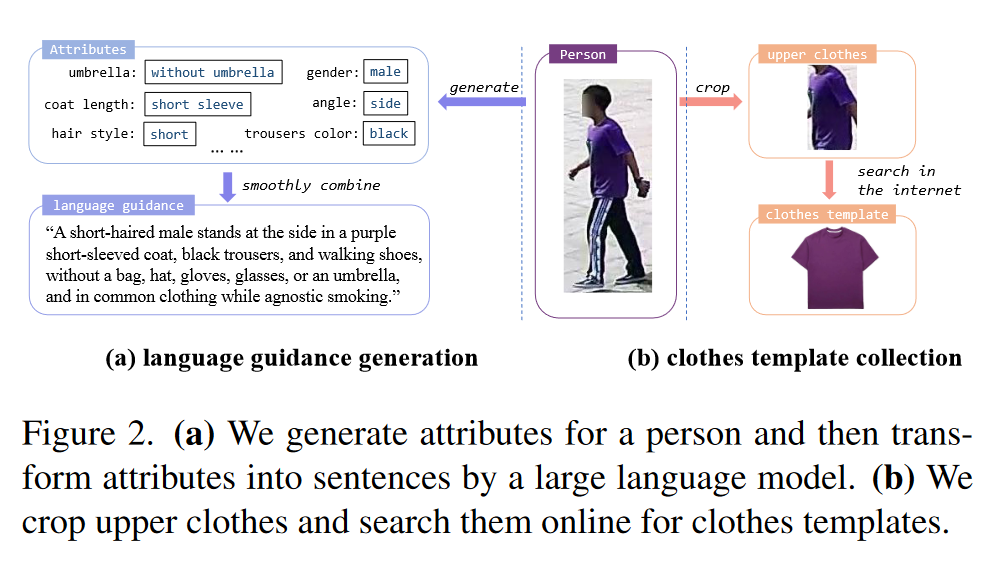
(1)LI-ReID instruction制作 LI-ReID给定了人的图片与一段文本描述,分别作为query和instruction输入,希望在gallery中找到符合文本描述的同一个人。为此,作者首先通过人工标注获得图片的attributes,例如年龄、性别、衣服类型等等;随后利用Alpaca-LoRA大语言模型,将这些attibutes连接成一段流程的话。最后由人工进行数据清洗,得到了最终的instruction。过程如图2(a)所示。
(2)CTCC-ReID instruction制作 CTCC-ReID与LI-ReID类似,不过instruction的输入不再是文本描述,而是衣服图片,并希望在gallery中找到穿着相同衣服的同一个人。因此,作者首先利用human parsing模型SCHP对ReID图片进行处理,得到仅包含衣服的图片。进一步的,作者从电商平台上,利用以图搜货的方式搜索这些衣服图片,获取了对应衣服的商品图片。最终经过数据清洗后得到了CTCC任务的instruction。过程如图2(b)所示
方法
文本的模型由4个部分组成,包括各种任务的instruction的生成模块、editing transformer 、instruction编码器以及cross-model的attention 。
整体流程:输入的instruction 会首先经过instruction编码器得到特征,并与配对的图像的tokens一同送入editing transformer ,基于instruction对输入图像进行特征编辑,得到特征,随后与instruction的特征一同送入attention 进行进一步融合,得到。最后,文章提出了一种新的adaptive triplet loss 用来监督网络的训练。整体流程如图3(a)所示。
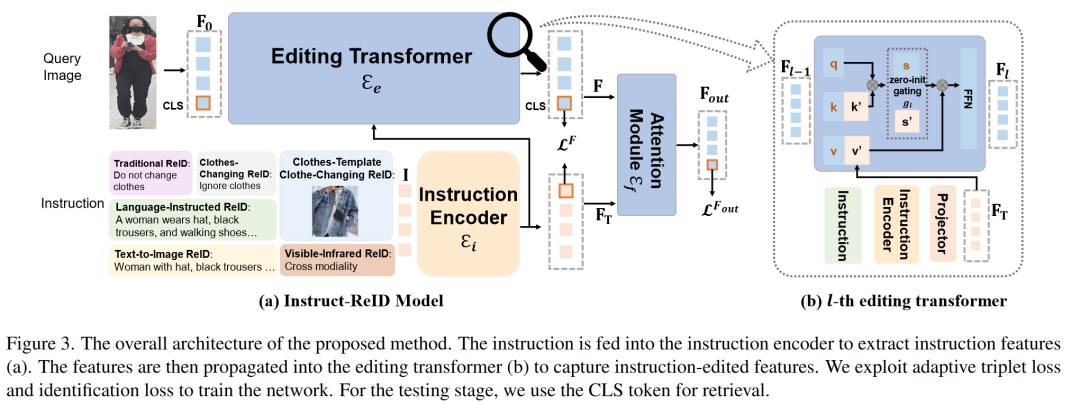
instruction生成:instruct-ReID接收一个图像和一个instruction作为输入,并检索出对应的图像。通过改变的instruction输入,instruct-ReID可以视作不同的主流ReID任务。
editing transformer:editing transformer由个零初始化的transformer组成。instruction通过后的特征在经过一个project layer同图像特征一同送入transformer层,由一个零初始化的可学习的门控参数对二者进行结合,实现特征编辑。
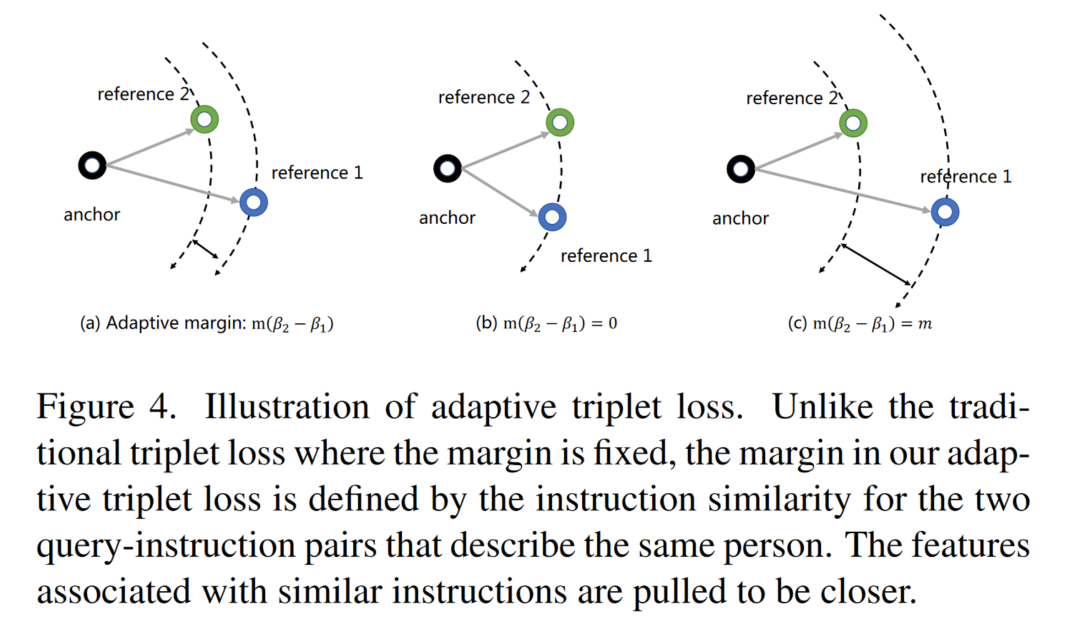
Adaptive Triplet loss:传统的triplet loss并没有考虑到instruction对检索的影响,因此文章提出了一种Adaptive triplet loss以实现instruct-ReID任务的学习。令为锚点,与为两个参考点。根据参考点与锚点的identity标签与,得到相似度函数:
其中表示指示函数。Adaptive triplet loss表达式为:
其中表示triplets数量,代表margin,表示欧式距离。图4给出了Adaptive triplet loss的可视化解释
实验
训练方法:文章采用了两种训练方法:
单任务训练(STL):训练只在相应数据集的训练与测试集上进行
多任务训练(MTL):先在联合数据集上训练,然后在各个数据集上进行测试
实现细节:文章使用经过ReID pretrain的ViT-Base网络作为图像编码器,使用ALBEF作为instruction的编码器。训练与测试中的所有图片均采用大小
实验结果:
Clothes-Changing ReID (CC-ReID). 在STL下,IRM在LTCC, VC-Clothes三个数据集上相较原有SOTA分别有+5.9%与+8.3%的提升。在MTL下,IRM在PRCC上取得了52.3%的mAP,取得了新的SOTA。具体数值如表2所示。
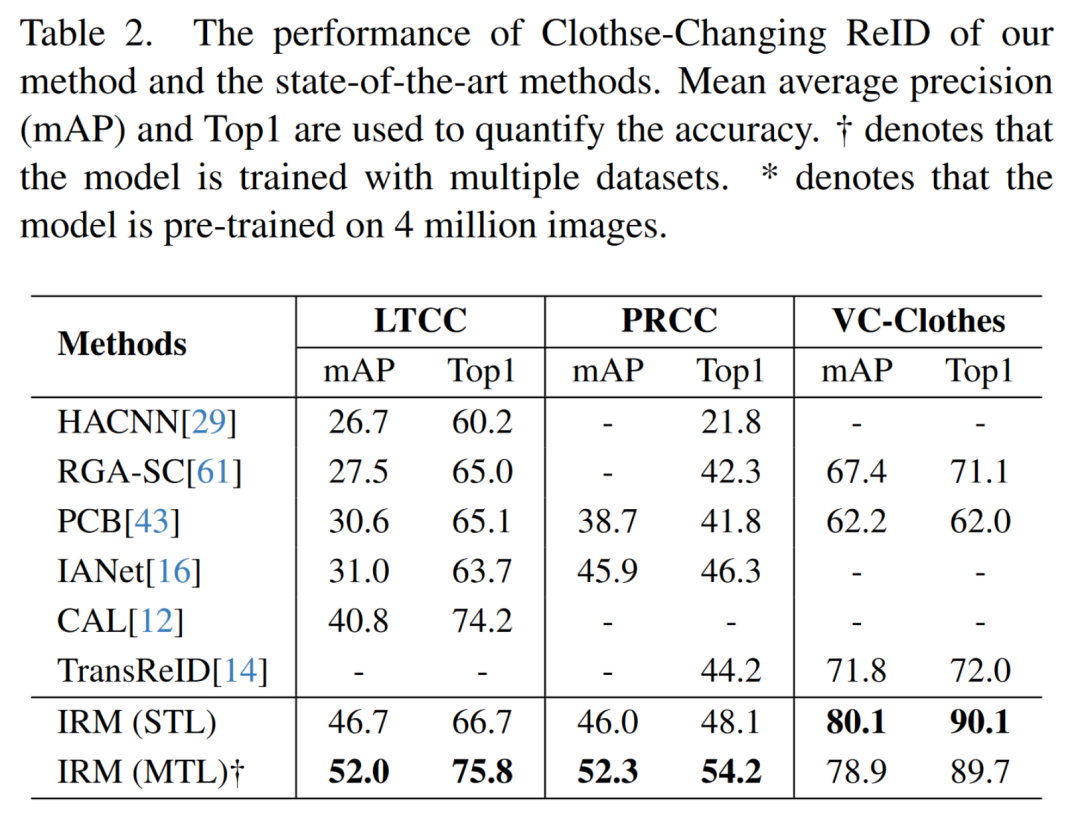
Visible-Infrared ReID (VI-ReID). IRM在LLCM数据集上分别采用红外-可见光(IR-to-VIS)与可见光到红外(VIS-to-IR)两种设定进行实验。在MTL下,模型在两种设定上均取得了新的SOTA,相较原有SOTA提升了+4.3%与+1.7%。具体数值参见表3。
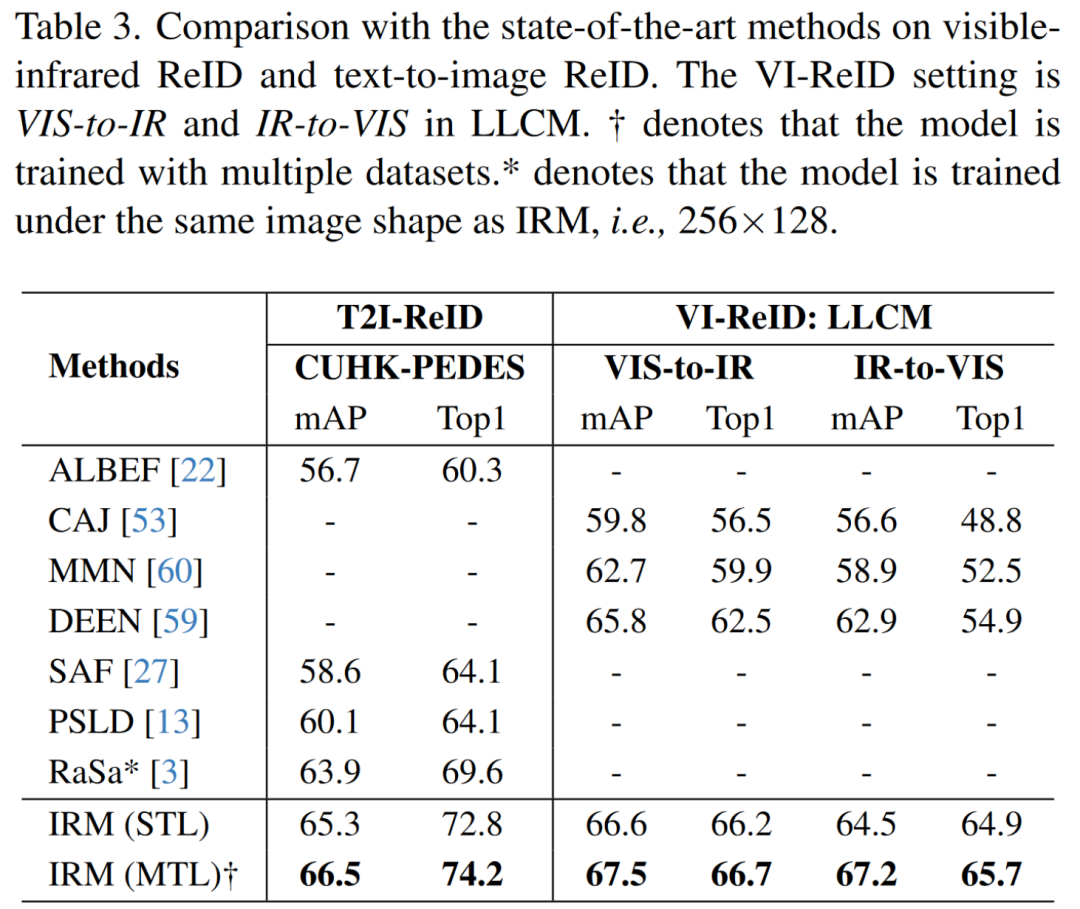
Text-to-Image ReID (T2I-ReID). IRM在STL下,取得了65.3%的mAP,并在MTL下进一步取得了66.5%的mAP,相较之前的SOTA提升了2.6%。具体数值见表3。
Clothes Template Based Clothes-Changing ReID (CTCC-ReID). 在STL下,IRM在COCAS+ Real2数据集上相较之前SOTA提高了+2.2%;在MTL下,IRM取得了更好的结果,相较之前SOTA提高了+11.7%。具体数值如表4所示。
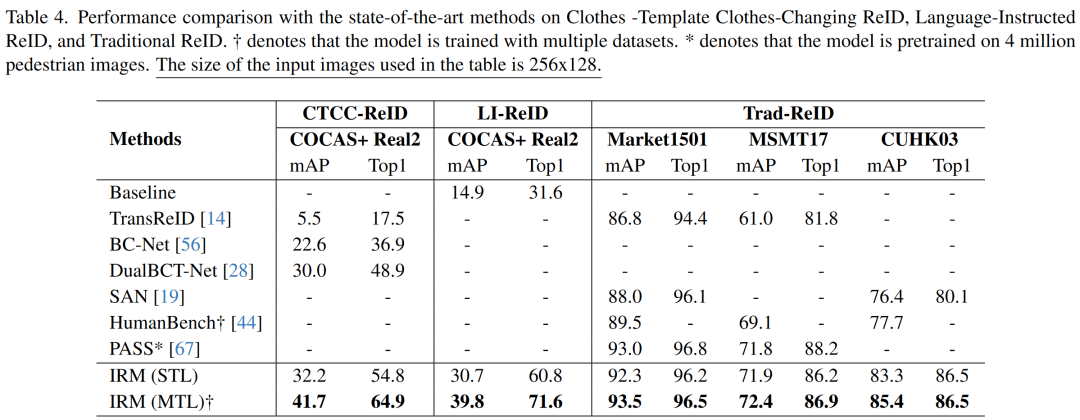
Language-Instructed ReID (LI-ReID). 由于LI-ReID是文章新提出的一种setting,所以文章使用在COCAS+ Real1上进行训练的ViT-Base作为Baseline。在STL下,IRM超过baseline +15.8%的mAP;在MTL下,IRM相较STL下进一步提升+9.1%,取得了SOTA的结果。具体数值如表4所示。
Traditional ReID (Trad-ReID). IRM在传统ReID任务上也取得了不错的成绩。在STL下,IRM在CUHK03上相较原有单任务训练的SOTA提升了+6.9%,并在Market1501与MSMT17上取得了与 SOTA相近的结果;在MTL下,IRM性能进一步提升,在Market1501、MSMT17与CUHK03上均超越了原有SOTA。具体结果如表4所示。
消融实验:
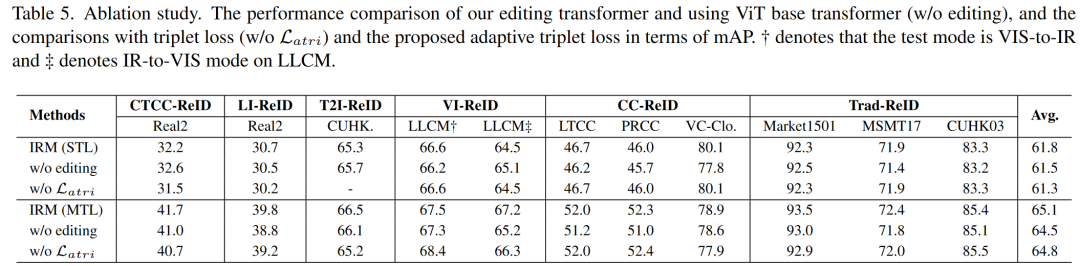
Editing Transformer. 为了验证editing transformer的有效性,文章将其替换成一个传统的ViT结构,只接收图像输入而不用instruction对其融合。实验结果表明,使用editing transformer在MTL下可以平均提升各个任务+0.6%的mAP,验证了editing transformer的有效性。具体数值见表5。
Adaptive triplet loss. 为了验证Adaptive triplet loss的有效性,文章将其替换成了一个传统的triplet loss。实验证明在MTL下,传统的triplet loss将会平均引起-0.3%的mAP下降。另一方面,在STL下,使用adaptive triplet loss后在CTCC-ReID与LI-ReID任务上分别提升了+0.7%与+0.5%,验证了文章提出的adaptive triplet loss确实帮助模型同时理解identity与instruction的相似性。具体数值见表5。
CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集ReID和多模态交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-多模态和ReID微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如ReID或者多模态+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 2766
2766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









