






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!


Workshop主页:https://coda-dataset.github.io/w-coda2024/
概述
本次Workshop旨在研讨当前最先进的自动驾驶技术与完全可靠的智能自动驾驶代理之间的差距。近年来,多模态大模型(如GPT-4V)展示了其在多模态感知与理解方面前所未有的进步。然而,利用MLLMs来应对自动驾驶中复杂场景,特别是罕见但关键的难例场景,仍然是一个未解的挑战难题。本次Workshop旨在促进多模态大模型感知与理解、先进的AIGC技术在自动驾驶系统中的应用、端到端自动驾驶等方面的创新研究。
Workshop征稿
本次论文征稿关注自动驾驶场景多模态感知与理解、自动驾驶场景图像与视频生成、端到端自动驾驶、下一代工业级自动驾驶解决方案等主题,包括但不限于:
Corner case mining and generation for autonomous driving.
3D object detection and scene understanding.
Semantic occupancy prediction.
Weakly supervised learning for 3D Lidar and 2D images.
One/few/zero-shot learning for autonomous perception.
End-to-end autonomous driving systems with Large Multimodal Models.
Large Language Models techniques adaptable for self-driving systems.
Safety/explainability/robustness for end-to-end autonomous driving.
Domain adaptation and generalization for end-to-end autonomous driving.
投稿规则:
本次投稿将通过OpenReview平台实行双盲审稿,接收两种形式的投稿:
1.完整论文:论文篇幅在14页内,采用ECCV格式,参考文献和补充材料篇幅不限。被接收的论文将成为ECCV官方论文集的一部分,不允许重新提交到其他会议。
2.扩展摘要:论文篇幅为4页内,采用CVPR格式,参考文献和补充材料篇幅不限。被接收的论文不会被包含在ECCV官方论文集中,允许重新提交到其他的会议。
投稿入口:
1. 完整论文:
https://openreview.net/group?id=thecvf.com/ECCV/2024/Workshop/W-CODA#tab-recent-activity
2.扩展摘要:
https://openreview.net/group?id=thecvf.com/ECCV/2024/Workshop/W-CODA_Abstract_Paper_Track#tab-recent-activity
自动驾驶难例场景多模态理解与视频生成挑战赛
本次竞赛旨在提升多模态模型在自动驾驶中极端情况的感知与理解,并生成描绘这些极端情况的能力。我们提供丰厚的奖品和奖金,诚邀您的参与!
赛道一:自动驾驶难例场景感知与理解
本赛道关注多模态大模型(MLLMs)在自动驾驶难例场景的感知和理解能力,包括整体场景理解、区域理解和行驶建议等方面的能力,旨在推动更加可靠且可解释的自动驾驶代理的发展。
赛道二:自动驾驶难例场景视频生成
本赛道关注扩散模型生成多视角自动驾驶场景视频的能力。基于给定的自动驾驶场景3D几何结构,模型需要生成与之对应的自动驾驶场景视频,并保证时序一致性、多视角一致性、指定的分辨率和视频时长。
竞赛时间:2024年6月15日至2024年8月15日
奖项设置:冠军1000美元,亚军800美元,季军600美元(每赛道)
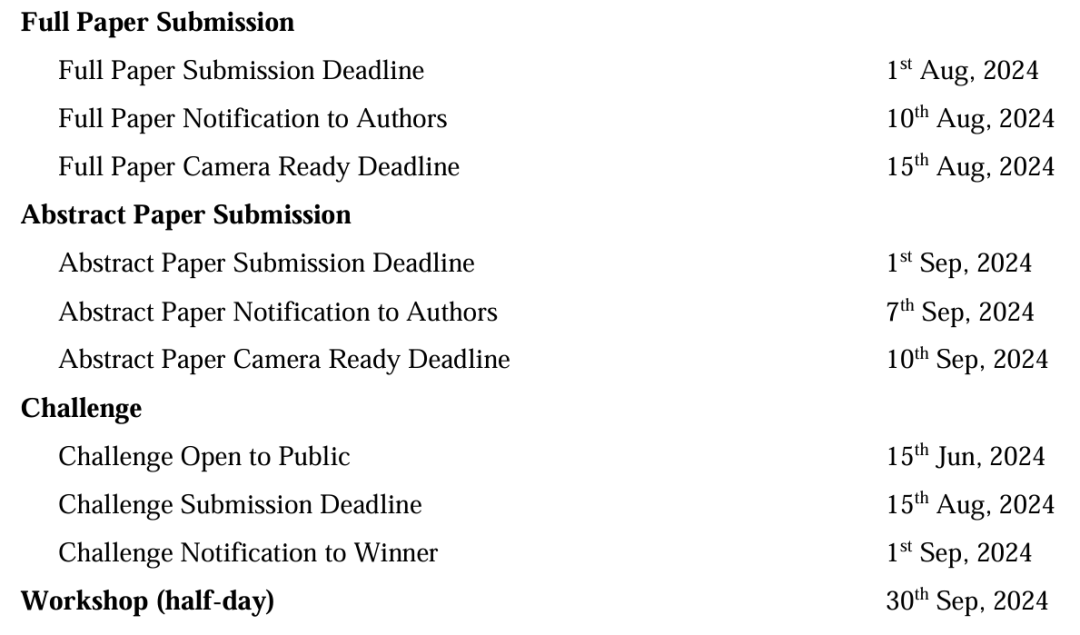
时间节点(AoE Time, UTC-12)
联系方式
如有任何关于Workshop和挑战赛的问题,请邮件联系:
w-coda2024@googlegroups.com
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集自动驾驶交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-自动驾驶微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如自动驾驶+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









