






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信:CVer5555,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

科研机构:Snap Research、台湾大学
论文链接:
https://openaccess.thecvf.com/content/CVPR2024/papers/Chen_DSL-FIQA_Assessing_Facial_Image_Quality_via_Dual-Set_Degradation_Learning_and_CVPR_2024_paper.pdf
项目链接:https://dsl-fiqa.github.io/
简介
面部图像质量评估(FIQA)对于人脸识别、社交媒体以及其他基于面部分析的应用至关重要。在这一领域中,通用面部图像质量评估(GFIQA)专注于评估面部图像在各种环境下的感知质量,尤其注重图像的清晰度、噪声水平和其他视觉退化因素。
现有方法的限制
尽管一般图像质量评估(GIQA)[1-2] 在标准数据集上表现出色,但它们常常忽视了面部图像的特殊性质,如表情的复杂性和环境的多样性,导致无法有效评估面部图像的真实感知质量。此外,生物识别面部图像质量评估(BFIQA)[3-4]虽然提高了面部识别系统的识别能力,但这类方法主要关注于图像的可识别性,而不是其感知退化的程度,因此无法全面评估面部图像的质量。
方法
模型概述
此方法是基于深度学习,网路分为三个部分: GFIQA Network, degradation extraction和landmark detection,GFIQA network是基于ViT以及Swin Transformer,用于抽取有关于GFIQA相关的feature,而degradation extraction module是用来抽取图像的degradation representation,这个feature会和GFIQA netowrk所抽出来的featrue透过cross attention产生degradation-aware的IQA feature。此外,我们引入了landmark的资讯到GFIQA network用于引导网路关注在脸部重要特征,最后得到面部质量分数。
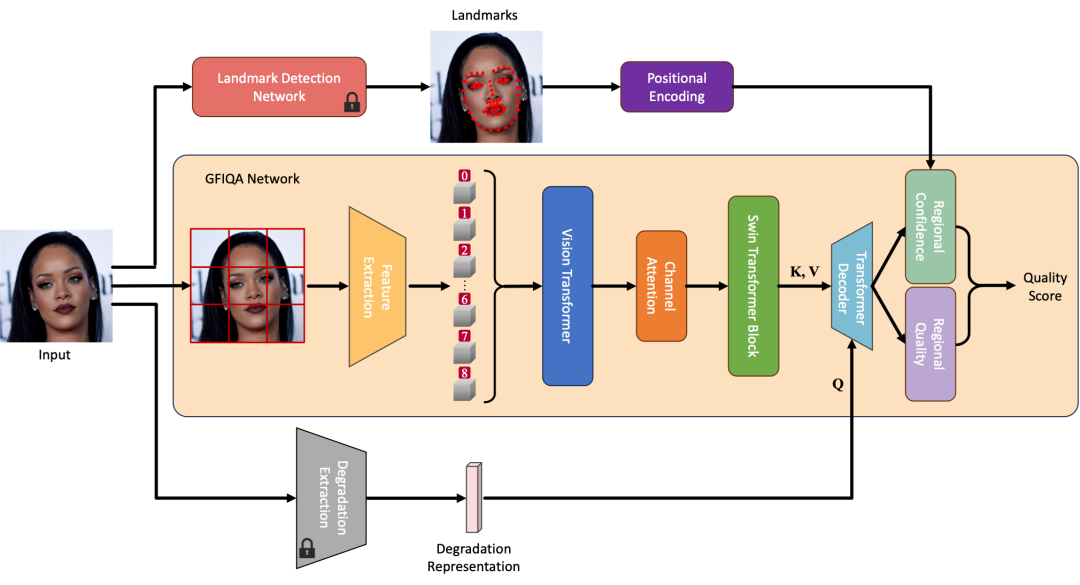
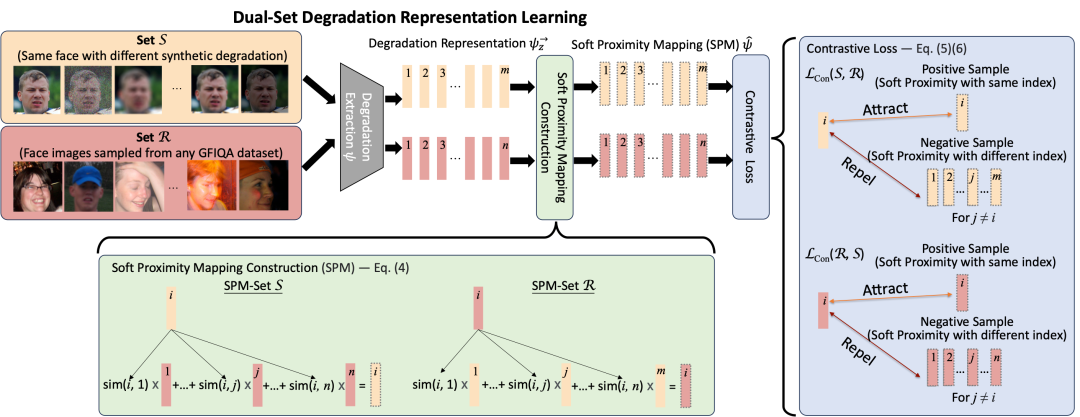
Self-Supervised Dual-Set Degradation Representation Learning (DSL)
当前的自监督degradation learning[5-6] (Patch-based) 是假设degradation在同一张影像相同,再利用对比学习去训练,然而,因为场景的多变性,这样的假设并不准确,会造成优化上的限制。为此,我们提出双集合退化表示学习,此算法透过自监督学习方法,我们能够从合成退化和真实场景退化的数据集中学习,独立地提取退化特征,更准确地模拟并评估真实世界中的面部图像质量。
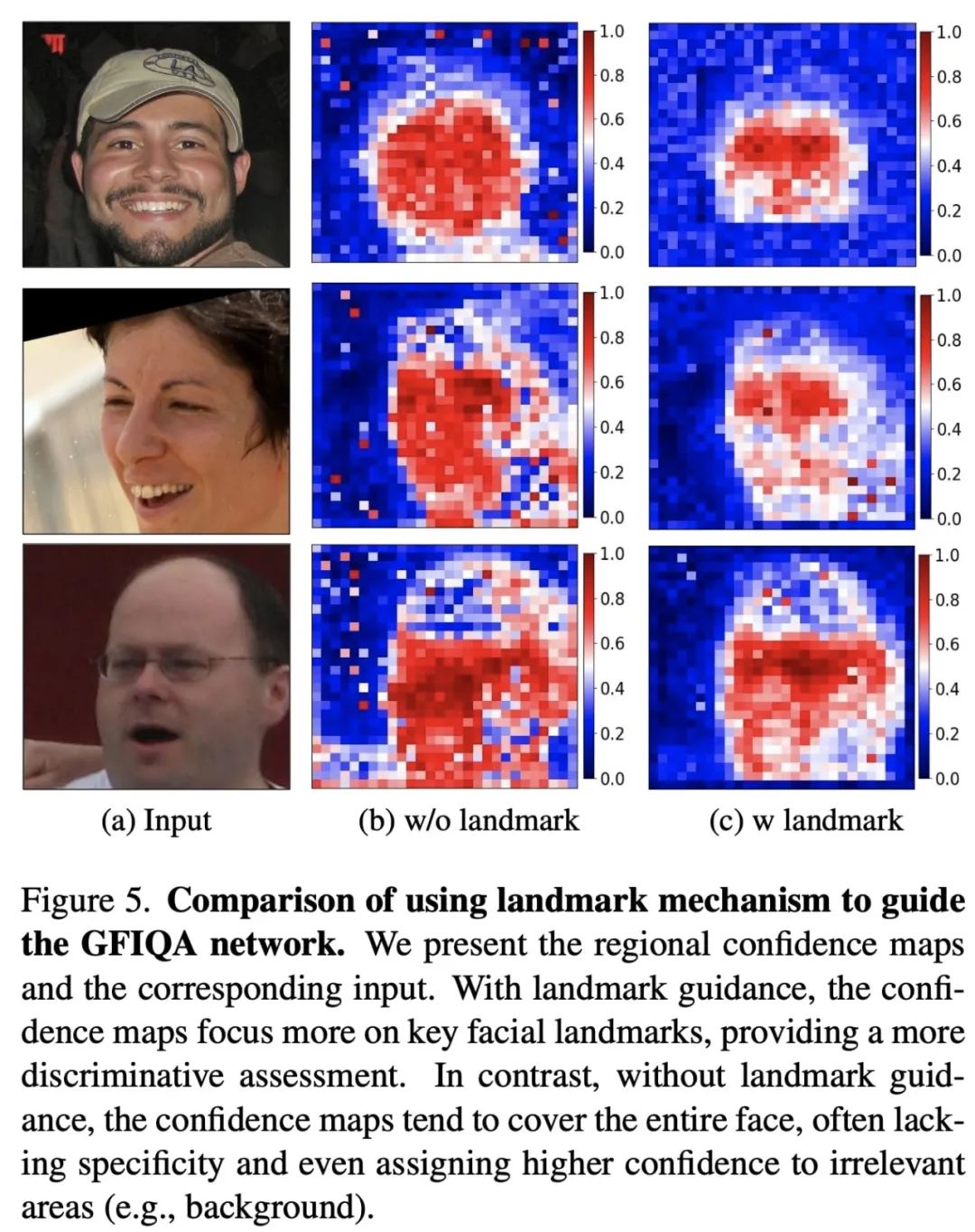
Landmark-guided GFIQA
我们引入landmark detection的DSL-FIQA不仅能评估整体图像的质量,还能对面部的每个关键区域如眼睛、鼻子和嘴巴进行详细评估。这种方法使得质量评估更加细致且符合人类视觉的感知重点。
Comprehensive Generic Face IQA Dataset (CGFIQA-40k)
为了DSL-FIQA的开发和验证,我们构建了一个大型面部图像的CGFIQA-40k数据集。这些图像涵盖了广泛的退化类型、肤色和性别,是目前最全面的用于面部图像质量评估的数据集之一。

实验结果
此篇论文做了许多实验来证明其有效性。
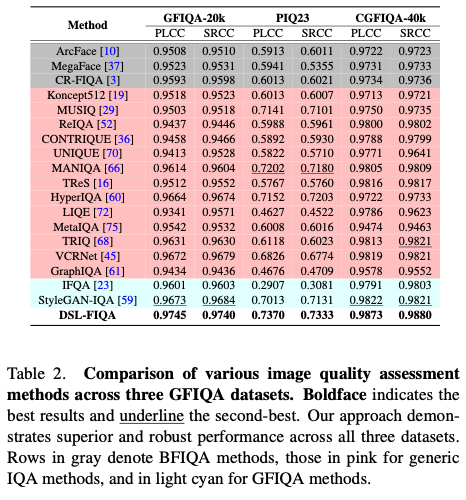
与现有方法的比较
可以发现在不同的人脸质量评估的资料集上此方法都能够达到State-of- the-art的效果。
消融实验(Ablation Study):
针对提出的DSL、Landmark guidance以及其他模组的比较:结果表明了使用论文中提出的所有模块有助于提升在Face Image Quality Assessment的效能。

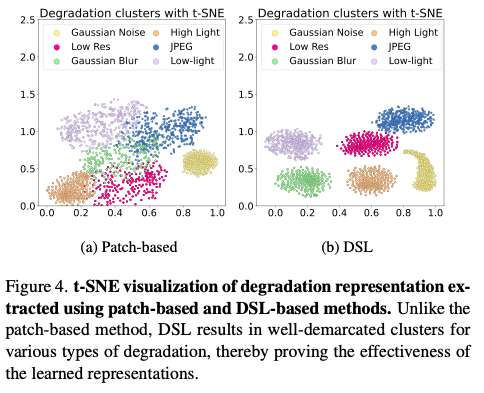
使用t-SNE去针对不同degradation extraction训练方法去做分析:实验结果表明,相较于现有的Patch-based strategy,使用所提出的DSL能够更好的识别不同的degradation。
使用landmark guidance对于模型对于脸部各部位重要性的影响程度:
实验结果表明了使用landmark guidance能够使网路更专注在人脸重要的feature上面。
参考文献
[1] Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. In ICCV, 2021.
[2] Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. In CVPR, 2022.
[3] Fadi Boutros, Meiling Fang, Marcel Klemt, Biying Fu, and Naser Damer. Cr-fiqa: face image quality assessment by learning sample relative classifiability. In CVPR, 2023.
[4] Qiang Meng, Shichao Zhao, Zhida Huang, and Feng Zhou. Magface: A universal representation for face recognition and quality assessment. In CVPR, 2021.
[5] Avinab Saha, Sandeep Mishra, and Alan C Bovik. Re-iqa: Unsupervised learning for image quality assessment in the wild. In CVPR, 2023.
[6] Kai Zhao, Kun Yuan, Ming Sun, Mading Li, and Xing Wen. Quality-aware pre-trained models for blind image quality as- sessment. In CVPR, 2023.
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信:CVer5555,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer5555,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









