






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer111,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

32 个标注者,29,429 条标注数据,图像平均分辨率 20001500,当前最难最大的纯手工标注图像感知 benchmark 来了!现有模型没有一个在总分上取得 60% 以上的准确率。

论文链接:
https://arxiv.org/abs/2408.13257
项目主页:
https://mme-realworld.github.io/
代码链接:
https://github.com/yfzhang114/MME-RealWorld
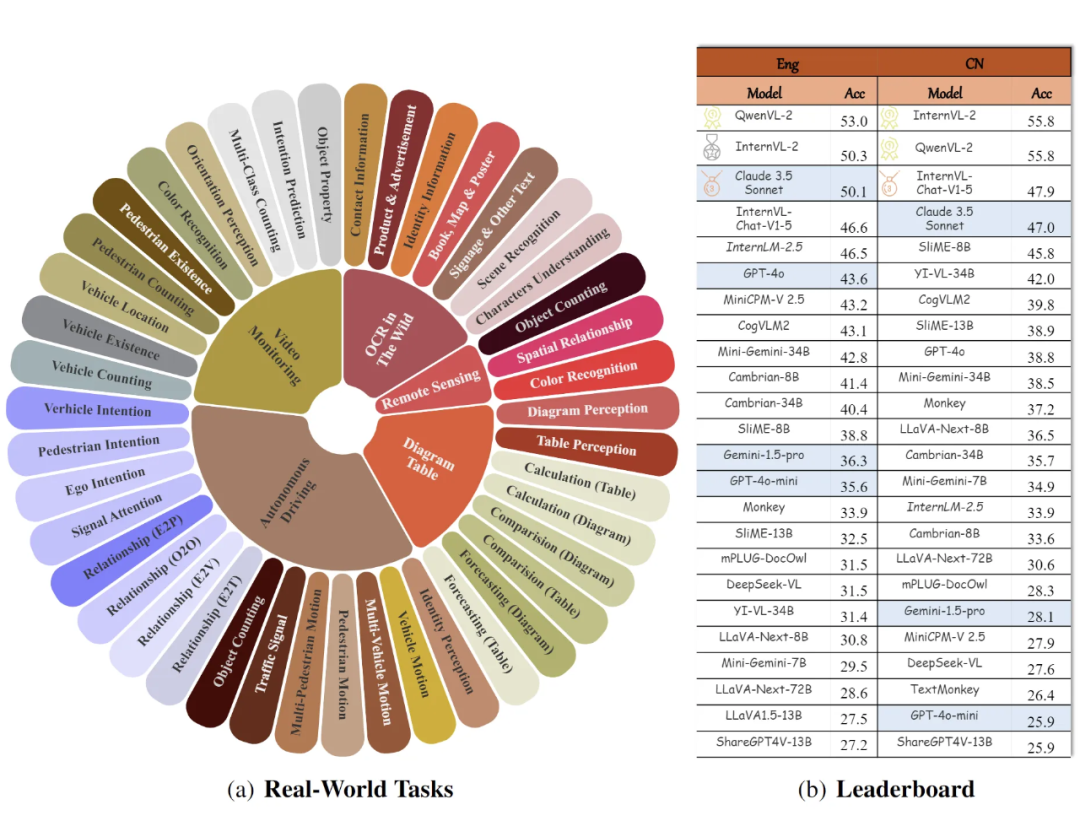

主要发现
在真实世界任务上,Qwen2-vl 和 InternVL2 在中文感知和推理任务上表现明显好于闭源模型比如 Claude 3.5,国内用户可以首选这两个。
英文版二者的感知能力 Qwen2-vl > InternVL2 > 其他,但是推理还是闭源模型 Claude 3.5 更胜一筹。
闭源模型比如 Gpt-4o 对于高分图像的能力被高估了,这方面 GPT-4o 基本上都排不到前三,Gemini-Pro 则更差。
所有 MLLMs 在自动驾驶,遥感数据,视频监控等复杂场景下的表现都非常差,在有些 domain上Qwen2-vl 的 Acc 也只有三十多(五分类),下游任务应用任重而道远。

真实场景部分任务展示

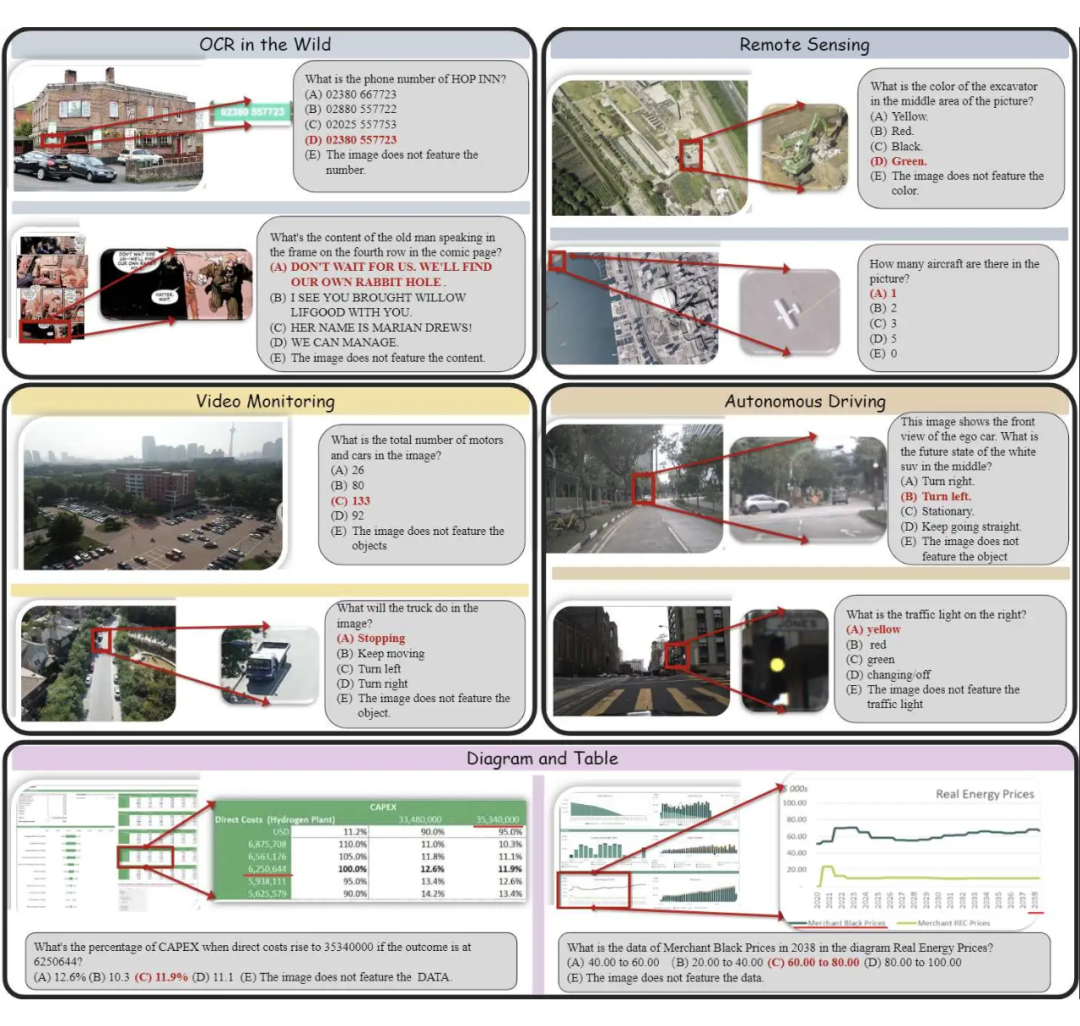
▲ 真实世界 OCR,需要在分辨率超过 1024*1024 的图像上识别细粒度的文字/数字
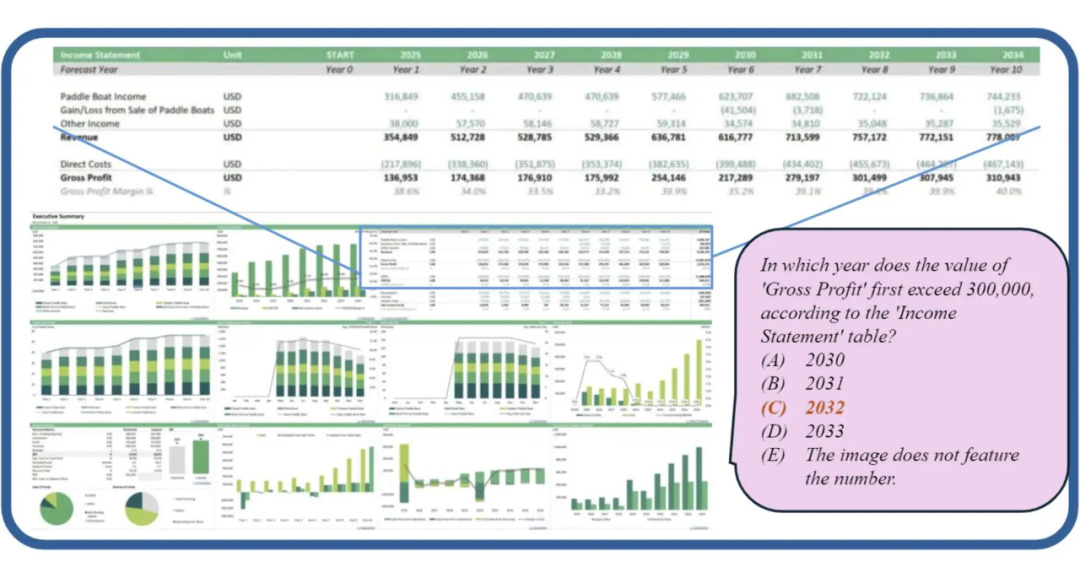
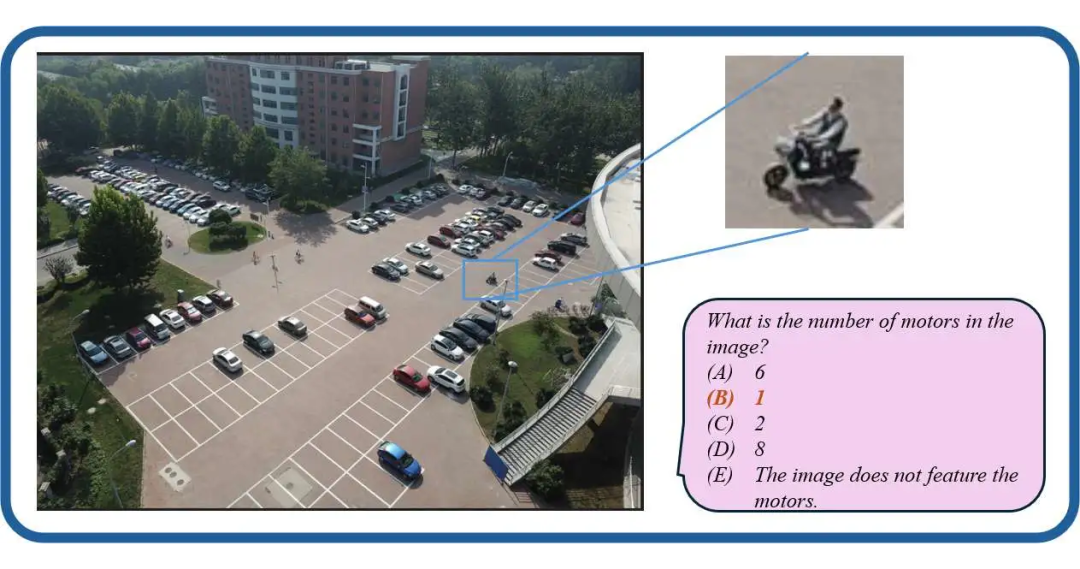 ▲ 监控数据分析:对视频监控数据的具体目标的计数/分析与识别
▲ 监控数据分析:对视频监控数据的具体目标的计数/分析与识别
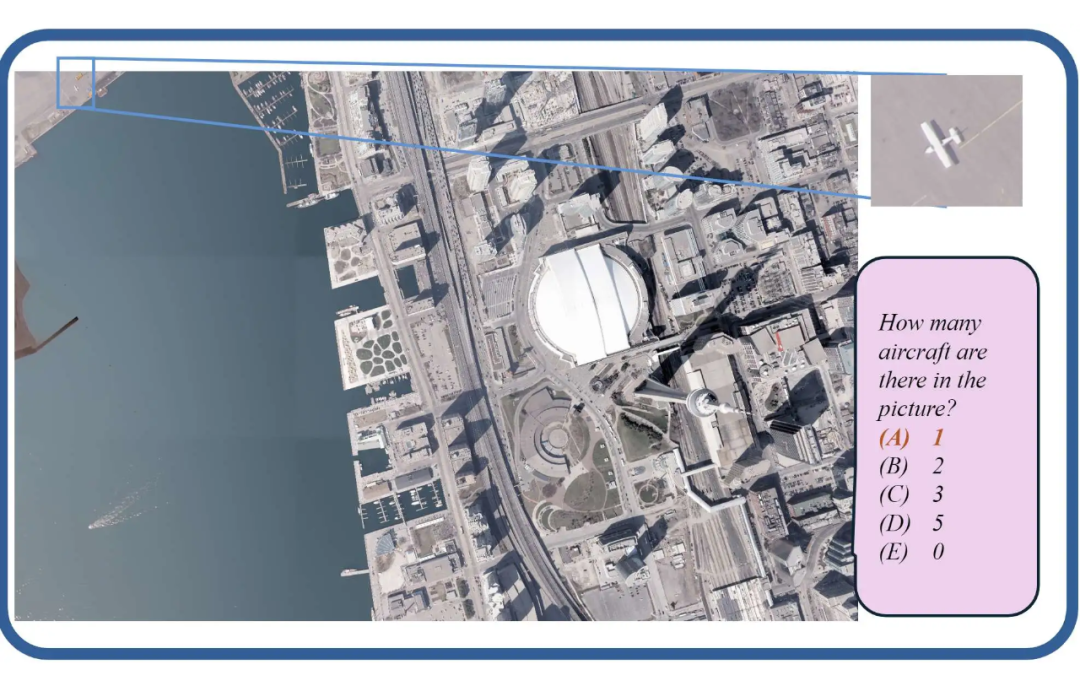
▲ 真实遥感数据物体识别:在高清遥感数据(单张图像大小甚至超过 500mb)上对小物体的统计与属性识别

▲ 自动驾驶:对自动驾驶场景下,自车或者其他车辆拍摄图像中的各种元素的行为理解与预测

为什么需要MME-RealWorld/现有benchmark的不足
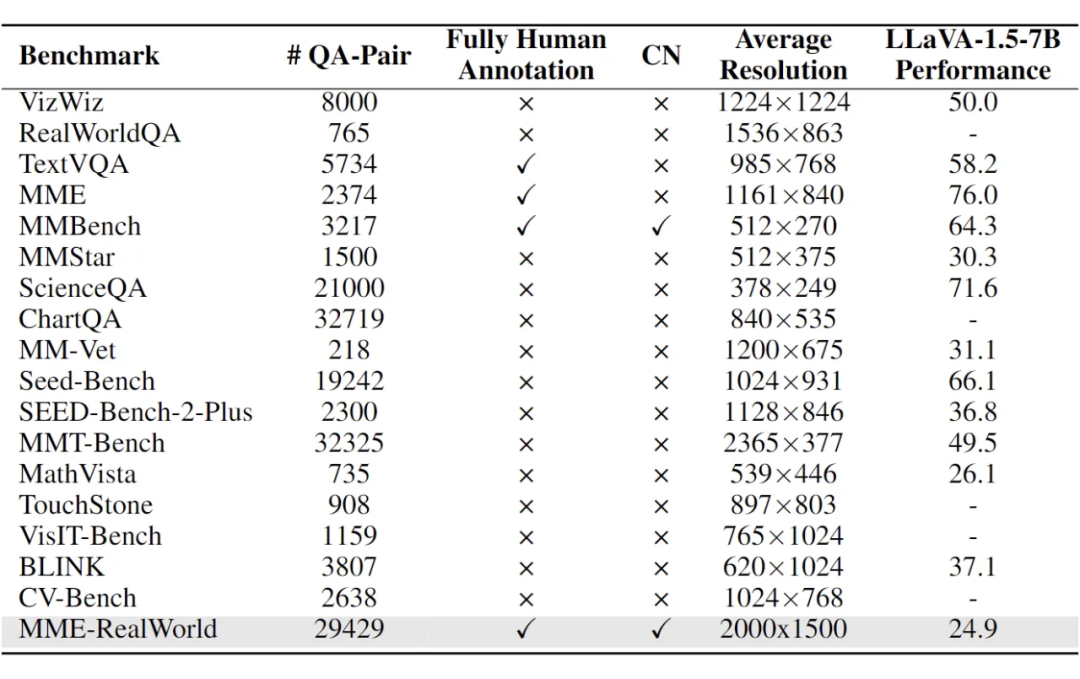
▲ MME-RealWorld 是规模最大的完全由人类标注的数据集,具有最高的平均分辨率和最具挑战性的任务。
近年来,多模态大语言模型(MLLMs)得到了显著的发展。这些模型的主要设计目标是开发能够通过整合多种模态感官数据全面感知人类查询和环境情况的通用智能体。因此,出现了大量全面的评估基准,用于严格评估这些模型的能力。然而,也存在一些常见问题:
1. 数据规模:许多现有的基准数据集包含少于 10,000 个问答对,例如 MME、MMbench、MMStar、MM-Vet、TorchStone 和 BLINK。有限的问答数量可能导致较大的评估波动。
2. 注释质量:虽然一些基准(如 MMT-Bench 和 SEED-Bench)规模相对较大,但其注释是由 LLMs 或 MLLMs 生成的。由于这些模型的性能有限,这种注释过程不可避免地会引入噪声,从而影响注释的质量。例如,在我们的基准中,表现最好的模型 InternVL-2 的准确率仅为 50%,依赖这些模型会不可避免地降低注释的质量。
3. 任务难度:目前,一些基准的最高性能已经达到了 80%-90% 的准确率,且先进 MLLMs 之间的性能差距较小。这使得验证先进模型的优势或改进变得具有挑战性,也难以区分哪个模型明显更优。
鉴于这些问题,作者提出了一个新的基准测试,名为 MME-RealWorld。作者首先关注了一系列具有明确动机的数据集家族,考虑了来自自动驾驶、遥感、视频监控、报纸、街景和金融图表等领域的图像。这些场景即使对人类来说也极具挑战性,作者希望 MLLMs(多模态大模型)能够真正提供帮助。

MME-RealWorld的数据来源与主要特征
基于这些主题,作者从超过 30 万个公共和互联网来源中收集了总计 13,366 张高分辨率图像,这些图像的平均分辨率为 2,000×1,500,包含丰富的图像细节。作者邀请了 25 位专业标注员和 7 位 MLLMs 领域的专家参与数据标注和质量检查,同时确保所有问题对 MLLMs 都具有挑战性。值得注意的是,作者指出,大多数问题甚至对人类来说也很难,需要多名标注员来回答并复查结果。
正如所示,MME-RealWorld 最终包含 29,429 个注释,涵盖 43 个子类任务,每个任务至少有 100 个问题。作者在这一基准测试中对 28 个先进的 MLLMs 进行了评估,并提供了详细的分析。
作者总结了 MME-RealWorld 相对于现有基准的主要优势,如下所示:
数据规模:通过 32 名志愿者的努力,作者手动标注了 29,429 个专注于现实世界场景的 QA 对,使其成为迄今为止最大的完全由人类标注的基准测试。
数据质量:
分辨率:作者指出,许多图像细节(如体育赛事中的记分牌)包含关键信息。只有通过高分辨率图像才能正确解读这些细节,而这对于向人类提供有意义的帮助至关重要。据作者所知,MME-RealWorld 拥有现有基准中最高的平均图像分辨率。
标注:所有标注均由专业团队手工完成,并进行交叉检查以确保数据质量。
任务难度与现实世界应用:上图(b)显示了不同 MLLMs 的性能结果,表明即使是最先进的模型,其准确率也未超过 60%。此外,作者在下图中展示,许多现实世界的任务显著比传统基准测试中的任务更难。例如,在视频监控中,模型需要计算 133 辆车的存在;在遥感中,模型必须识别并计算分辨率超过 5000×5000 的地图上的小物体。
MME-RealWorld-CN:作者指出,现有的中文基准通常从英文版本翻译而来,这有两个限制:
问题与图像不匹配:图像可能与英文场景相关,但与中文问题没有直观的联系。
翻译不匹配:机器翻译并不总是足够精确和完美。为此,作者收集了更多关注中国场景的图像,并邀请中国志愿者进行标注,最终获得了 5,917 个 QA 对。

模型效果与分析
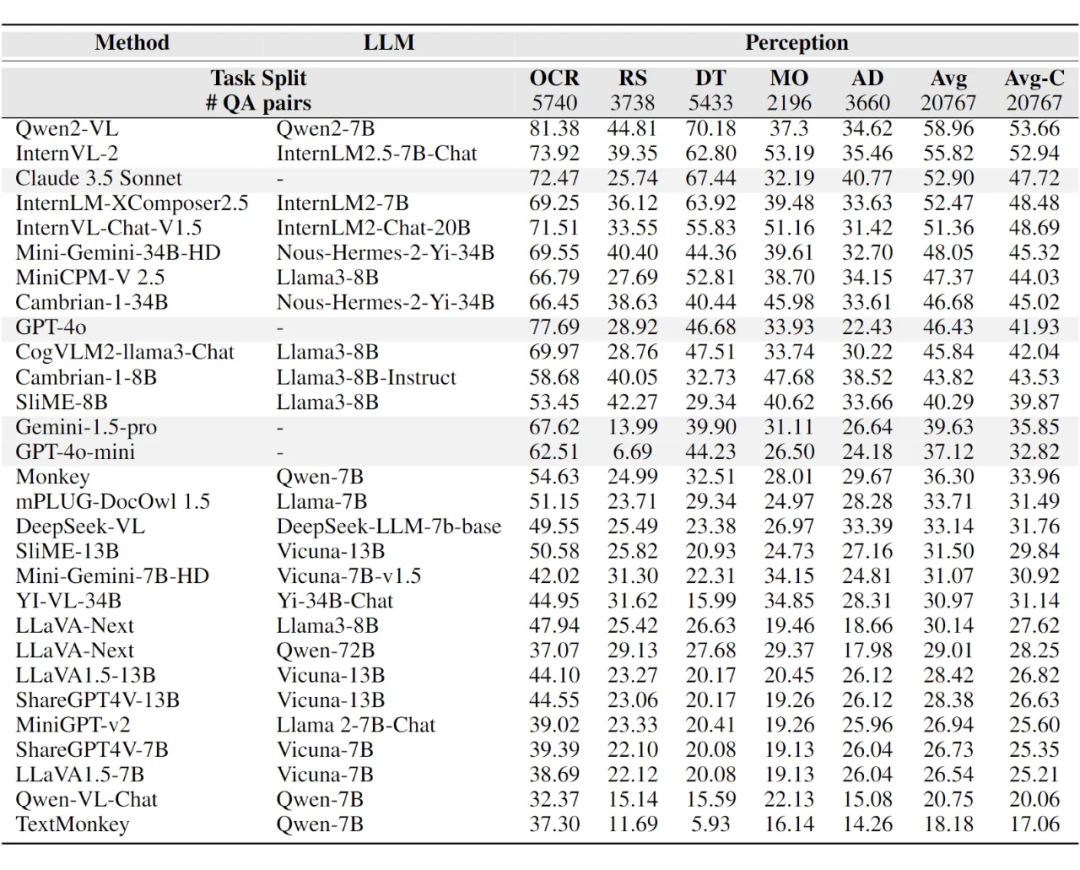
上表展示了不同模型在 5 个领域中的感知能力表现。总体而言,Qwen2-VL 与 InternVL-2 表现出最强的感知能力,优于其他闭源模型。然而,各个任务的表现存在差异,作者总结了以下几点关键观察:
1. OCR 任务表现:GPT-4o 在实际 OCR 任务中表现最佳,达到了 77% 的准确率,但在更具挑战性的任务中,其表现显著下降,落后于其他顶尖模型。这一趋势也在其他闭源模型中出现,如 Gemini-1.5-Pro 和 GPT-4o-mini,它们在 OCR 任务中表现良好,但在其他实际任务中表现欠佳。作者提出了三种可能的原因:
闭源模型在上传本地图像时通常对最大图像尺寸和分辨率有限制。例如,Claude 3.5 Sonnet 的最大分辨率为 8K,最大图像质量为 5MB,而 GPT-4o 和 Gemini-pro 允许上传最大 20MB 的图像。这限制了某些高质量图像的输入,因为需要压缩图像才能上传。
闭源模型往往更为保守。作者观察到,闭源模型输出 “E”(表示图像中不存在相关物体)的比例较高,这表明这些模型可能采用保守的应答策略,以避免幻觉或提供更安全的答案。
闭源模型有时拒绝回答某些问题。由于不同的输入/输出过滤策略,一些样本被认为涉及隐私或有害内容,因此不予回答。
2. 高分辨率输入的优势:允许更高分辨率输入的模型(如 Mini-Gemini-HD 和 SliME)相对于直接使用视觉编码器的模型(如 ShareGPT4V 和 LLaVA1.5)表现出显著优势。在相同的模型大小下,这些模型在不同子任务中的表现均有所提升。这强调了高分辨率图像处理对于解决复杂现实任务的重要性。
3. 不同领域的趋势:遥感任务涉及处理极大图像,要求对图像细节有更深入的理解。在这些任务中,专注于高分辨率输入的模型(如 Cambrian-1、Mini-Gemini-HD 和 SliME)表现优于其他模型。此外,在大量图表数据上进行训练的模型在处理复杂图表时表现出更好的感知能力。例如,SliME 和 LLaVA1.5 的训练集中包含的图表数据有限且相对简单,因此在这一类别中的表现不及更近期的模型。
4. 推理能力:下表展示了推理任务的实验结果。在推理能力方面,Claude 3.5 Sonnet 在大多数领域中表现最为出色,尤其是在图表相关任务中,比排名第二的 GPT-4o 高出 16.4%。闭源模型 GPT-4o 表现良好,略微落后于排名第二的 InternVL-2,但在多个领域中甚至优于 InternVL-2。
大多数开源模型表现不佳,传统基准方法(如 LLaVA1.5 和 Qwen-VL-Chat)的结果接近随机猜测。此外,推理任务比感知任务更具挑战性。即使是排名最高的模型,其平均准确率也未能超过 45%,类别准确率也未超过 50%。这表明当前模型在达到人类级别的推理能力方面仍有很大差距。
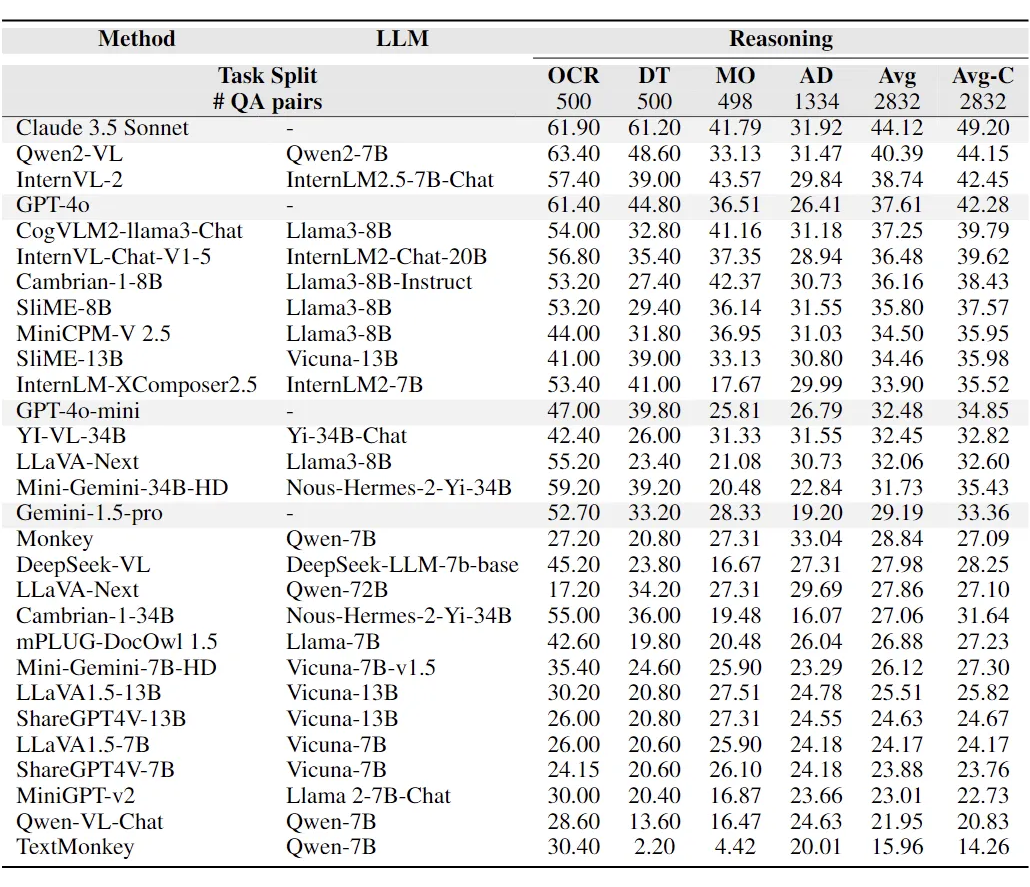
▲ 推理任务的实验结果显示,模型按照其平均性能进行排名。为了区分,专有模型的行被灰色突出显示。

目前MLLM的缺陷以及值得注意的点
现有模型在图像细节感知方面的不足: 多数模型选择答案 “E” 的频率远高于实际数据中的比例,这表明这些模型的视觉感知模块未能准确识别图像中的对象。
MLLMs 在理解动态信息方面的局限性: 在自动驾驶和监控任务中,MLLMs 在理解和推理动态信息方面表现出明显的不足,显示出与人类能力之间的巨大差距。
计算效率: 处理高分辨率图像时,各模型的计算效率差异显著。某些模型在处理超过 1024×1024 分辨率的图像时计算需求非常高,如 Mini-Gemini-HD,计算成本比 LLaVA1.5 高约 5 倍。这也显示了现有方法在处理高分辨率图像时的固有局限性。
错误选项分析: 研究发现,不同的 MLLM 在处理不确定问题时的应对策略有所不同。较大的模型通常采取更保守的策略,倾向于选择更安全的 “E” 选项,而较小的模型往往倾向于选择第一个选项 “A”。值得注意的是,InternVL-2 的错误选择分布非常均匀,这可能解释了其在评估中的优异表现。
指令跟随能力: 闭源模型在按照指令选择和输出单一答案方面表现较好,而开源模型往往不严格遵循指令,生成过多的附加分析,有时甚至在达到预定义的最大 token 数之前仍继续输出。这表明开源模型在指令执行能力方面仍有很大优化空间。

总结与未来工作
本文提出了 MME-RealWorld 基准测试,旨在解决现有 MLLM 评估中的关键局限性,如数据规模、标注质量和任务难度。作为迄今为止最大、分辨率最高的纯人工标注数据集,MME-RealWorld 得益于 32 名标注者的参与,确保了高质量数据和最小的个人偏差。大多数 QA 对都集中在自动驾驶和视频监控等现实世界场景上,这些场景具有重要的适用性。
此外,MME-RealWorld-CN 作为一个专注于中文场景的基准测试,基本上能够确保所有图像和问题都与中文环境相关,且全中文为母语的人工标注,不存在机器翻译引发的一系列问题。
本文还对广泛的模型进行的评估揭示了显著的性能差距,突出了当前模型在复杂图像感知方面的缺陷,并强调了进一步提高的需求。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer111,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer111,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看














 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









