






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer2233,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

转载自:Deeeep Learning
重建 vs 生成:解决扩散模型中的优化难题
题目:Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
作者:Jingfeng Yao, Xinggang Wang
作者单位:华中科技大学
Paper: https://arxiv.org/abs/2412.04852
Code:https://github.com/hustvl/LightningDiT


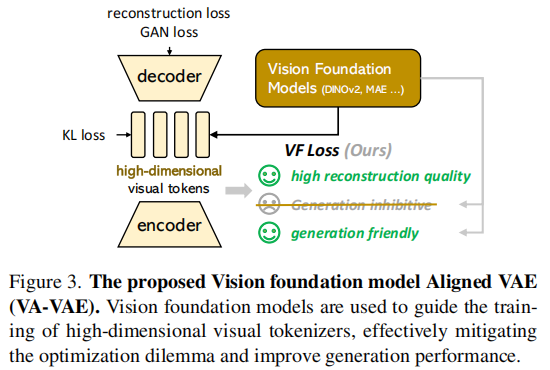
两阶段的潜在扩散模型中存在优化难题:在visual tokenizer 中增加每个标记的特征维度,虽能提升重建质量,但要达到相近的生成性能,却需要大得多的扩散模型和更多训练迭代。因此,现有系统常常只能采用次优解决方案,要么因tokenizer中的信息丢失而产生视觉伪影,要么因计算成本高昂而无法完全收敛。作者认为这种困境源于学习不受约束的高维潜在空间的固有困难。为了解决这一问题,作者建议在训练视觉词元分析器时,将潜在空间与预先训练的视觉基础模型对齐。提出的VA-VAE(视觉基础模型结合变分自动编码器)显著扩展了潜在扩散模型的重建生成边界,使高维潜在空间中的Diffusion Transformers (DiT) 能够更快地收敛。为了充分发挥VA-VAE的潜力,构建了一个增强型DiT基线,改进了训练策略和架构设计,称为LightningDiT。在ImageNet 256x256 生成上实现了最佳 (SOTA) 性能,FID得分为1.35,同时在短短64个epoch内就达到了2.11的FID得分,展现了卓越的训练效率——与原始DiT相比,收敛速度提高了21倍以上。
相关工作
可视化生成的tokenizer
visual tokenizer包括以变分自编码器(VAE)为代表的连续型和 VQVAE、VQGAN 等离散型。离散型词元分析器虽然能提高重建保真度,但编码对照本利用率低下,对生成性能产生不利影响。连续型tokenizer通过增加词元分析器的特征维度会提高重建质量,但会降低生成性能,还需要大幅增加训练成本 ,当前缺乏对连续型 VAE 优化的有效解决方案。
扩散Transformer的快速收敛
扩散Transformer(DiT)目前是潜在扩散模型最常用的实现方式,存在收敛速度慢的问题,往研究提出多种加速方法,本文则从优化视觉词元分析器学习的潜在空间入手,在不修改扩散模型的情况下实现更快收敛,并对 DiT 进行了训练策略和架构设计优化。

网络架构
VA-VAE基于VQGAN模型架构,通过视觉基础模型对齐损失(VF损失)优化潜在空间。VF损失由边缘余弦相似度损失(Marginal Cosine Similarity Loss)和边缘距离矩阵相似度损失(Marginal Distance Matrix Similarity Loss)组成,是一个即插即用模块,在不改变模型架构和训练流程的情况下解决优化困境。
边际余弦相似度损失
将视觉标记器编码器输出的图像潜在特征投影后,与冻结的视觉基础模型输出的特征计算余弦相似度,通过 ReLU 函数和设置边际值,使相似度低于边际值的特征对损失有贡献,从而聚焦于对齐差异较大的特征对。
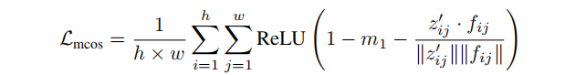
边际余弦相似度损失
将视觉标记器编码器输出的图像潜在特征投影后,与冻结的视觉基础模型输出的特征计算余弦相似度,通过ReLU函数和设置边际值,使相似度低于边际值的特征对损失有贡献,从而聚焦于对齐差异较大的特征对。
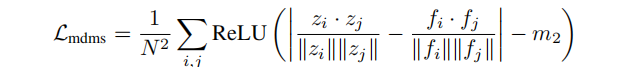

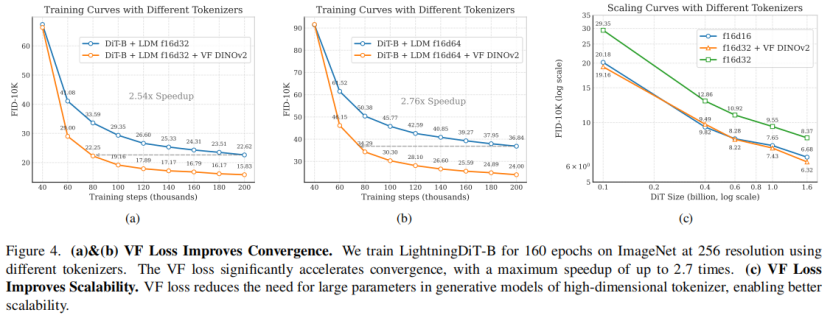
visual tokenizer采用LDM的架构和训练策略,使用VQGAN网络结构和KL损失,训练三种不同的f16标记器(无VF损失,VF损失(MAE),VF损失(DINOv2))。生成模型采用LightningDiT,在ImageNet上以256分辨率训练,设置相关参数和训练策略。
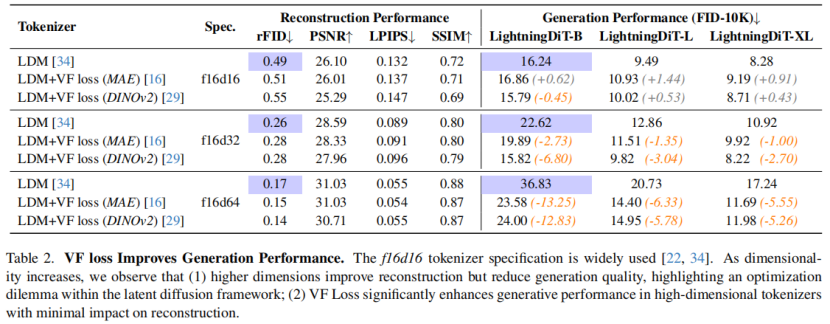
使用 VF 损失在f16d32和f16d64收敛速度提升明显
8种不同tokenizer的重建和生成的评估
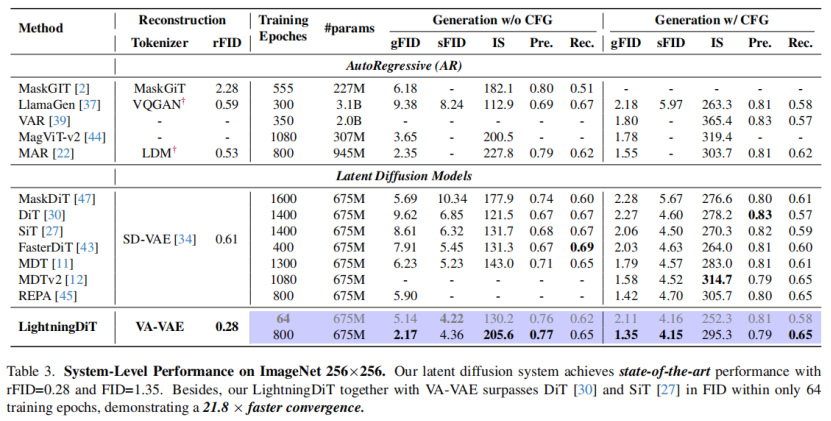
与现有扩散模型对比
可视化效果

何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
CVPR 2025 论文和代码下载
在CVer公众号后台回复:CVPR2025,即可下载CVPR 2025论文和代码开源的论文合集ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CV垂直方向和论文投稿交流群成立
扫描下方二维码,或者添加微信号:CVer2233,即可添加CVer小助手微信,便可申请加入CVer-垂直方向和论文投稿微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者论文投稿+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer2233,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看
















 415
415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









