







 本文介绍了LoRA(低秩适配器)方法,用于减少大语言模型如codeLLama-34B在全量微调时的资源消耗。LoRA通过低秩矩阵A和B模拟参数更新,降低了微调参数量,保持了模型性能。文中详细阐述了LoRA的工作原理,并提供了在unix环境下配置CUDA并使用PEFT库进行LoRA微调的步骤。
本文介绍了LoRA(低秩适配器)方法,用于减少大语言模型如codeLLama-34B在全量微调时的资源消耗。LoRA通过低秩矩阵A和B模拟参数更新,降低了微调参数量,保持了模型性能。文中详细阐述了LoRA的工作原理,并提供了在unix环境下配置CUDA并使用PEFT库进行LoRA微调的步骤。
前言
微调的含义,就是把已经训练好的模型拿来,给它吃特定的下游任务数据,使得模型在预训练权重上继续训练,直至满足下游任务性能标准。
全量微调指的是,在下游任务的训练中,对预训练模型的每一个参数都做更新。例如图中,给出了Transformer的Q/K/V矩阵的全量微调示例,对每个矩阵来说,在微调时,其d*d个参数,都必须参与更新。
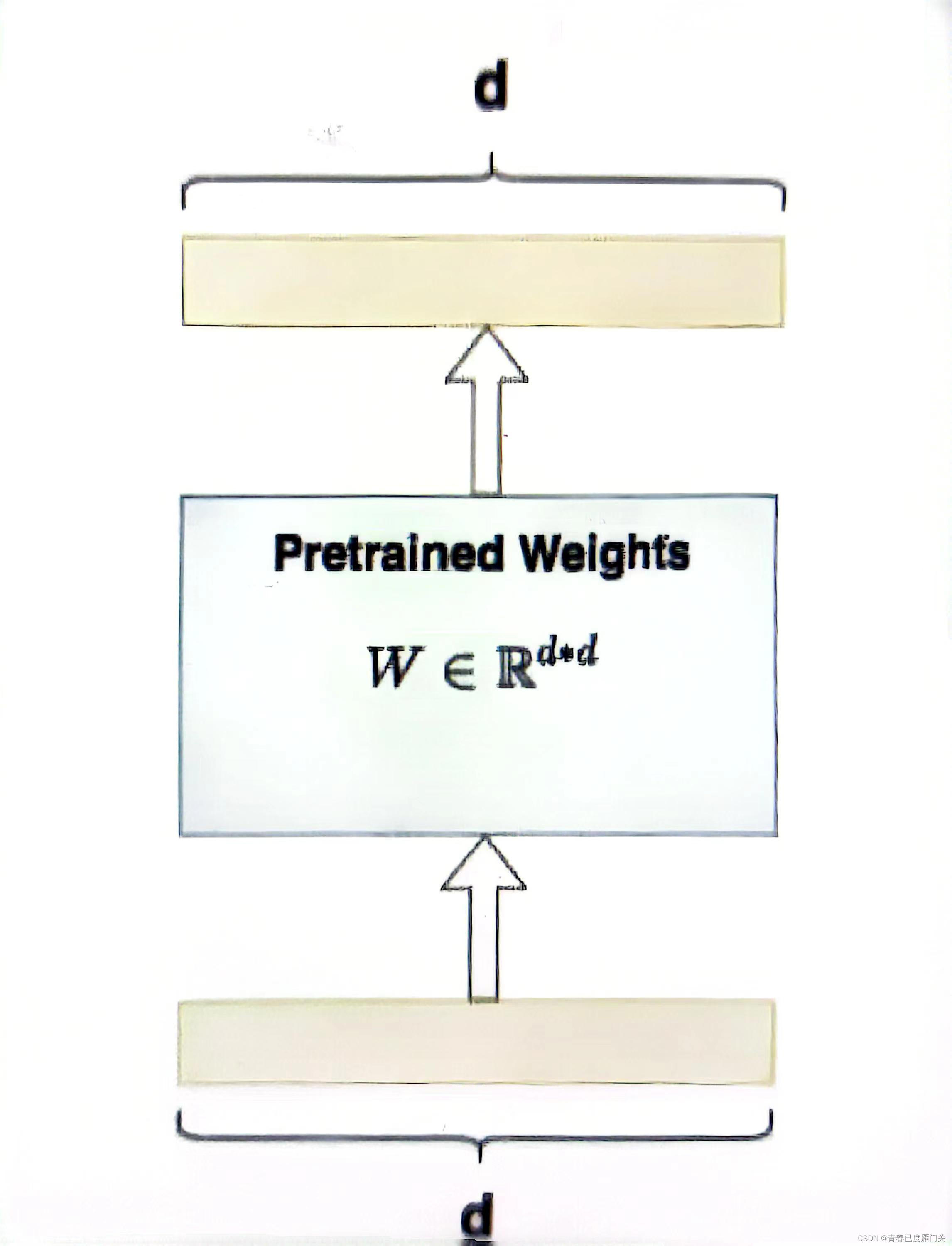
目前有大量对LLM(大语言模型)做Fine-tune的方式,不过需要消耗的资源非常高,例如:
1、Stanford Alpaca:对LLaMA-7B做Fine-tune,需要4颗A100(80GB) GPU
2、FastChat/Vicuna: 对LLaMA-7B做Fine-tune,需要4颗A100(40GB) GPU
使用LoRA则可以较好的解决这个问题。
LoRA全称为Low-Rank Adaptation of Large Language Models(低秩适配器),是一种模拟全量参数微调的特殊方法:不改变原模型的情况下,在旁边增加一个降维和升维操作来模拟训练真正能影响模型效果的那些参数,从而达到精调效果。
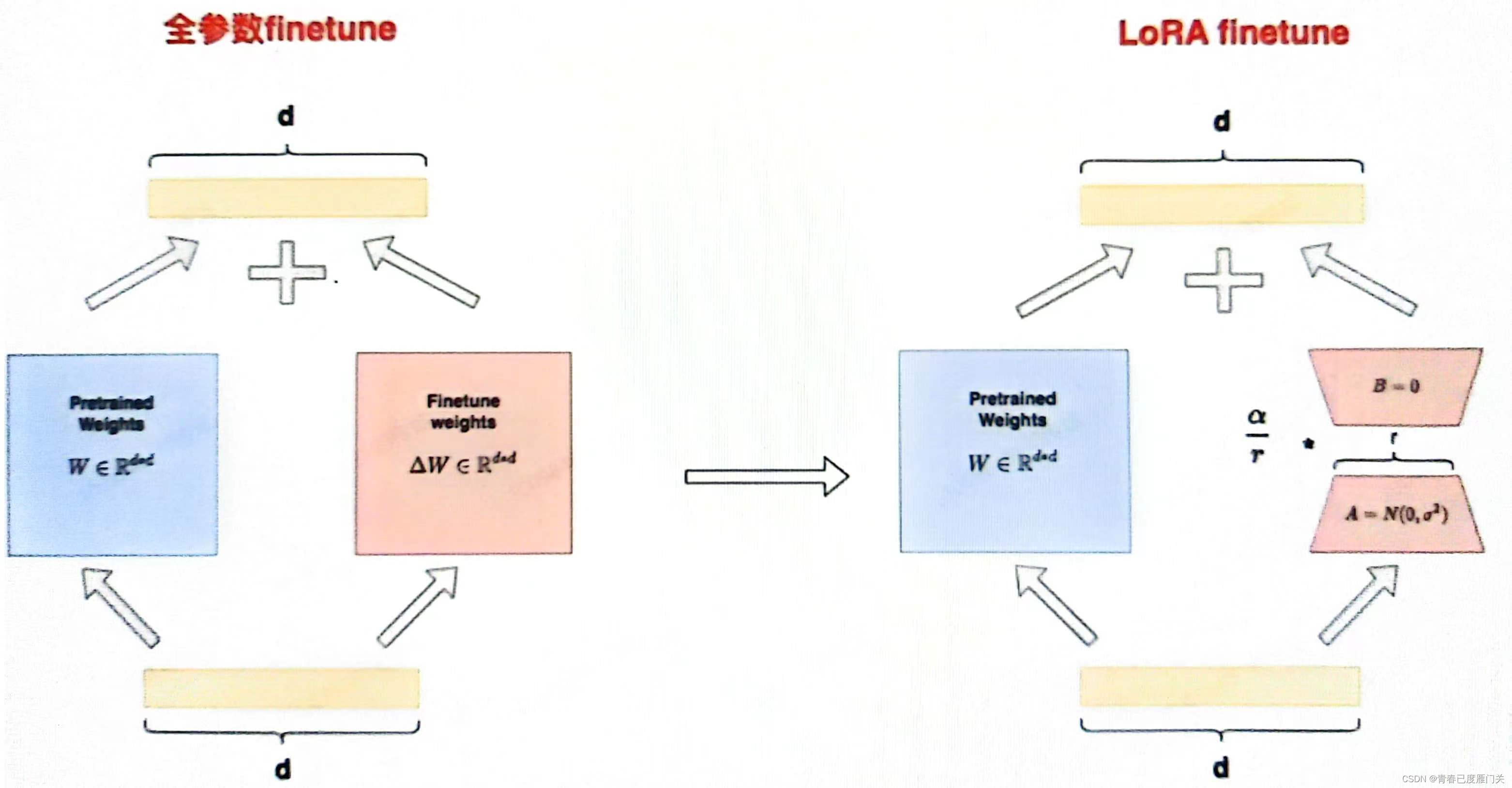
图中左侧表示“全参数finetune”的场景。我们将参数分成了两个部分::预训练权重
:finetune增量权重
之所以这么拆分,是因为全参数finetune可以理解成“冻住的预训练权重”+“微调过程中产生的权重更新量”。设输入为x,输出为 y,则有:y=(w+-w)x
图中右侧表示“LoRA finetune”的场景。在LoRA中,我们用矩阵A和B来近似表达w::低秩矩阵A,其中r被称为“秩”,对A用高斯初始化.
:低秩矩阵B,对B采用零初始化。
经过这样一番拆分,我们将w改写成-w=B的形式,使得微调参数量从d*d降低至2*r*d,同时不改变输出数据的维度,即在LoRA下我们有: y=wx+BAx
另外,在原论文中提到过对于两个低秩矩阵,会用超参
(一个常数)来做调整,这个超参是作为scaling rate直接和低秩矩阵相乘的,也就是最终的输出为:
微调过程:
环境配置:
使用unix操作系统,并配置CUDA运算环境。推荐运行配置如下表:
| 设备 | 配置 | 推荐配置 |
| 处理器 | Intel i7 | Intel Xeon |
| 运行内存 | 26GB | 40GB |
| 显卡内存 | 26GB | 40GB |
| 硬盘大小 | 30GB | 40GB |
基座模型
codeLlama-34B
语料格式
[ {"instruction":"", "input":"", "output":""} ]
实现过程
五、实现过程
LoRA 微调的内部实现流程主要包括以下几个步骤:
1、确定要使用 LoRA 的层。peft库目前支持调用 LoRA的层包括:nn.Linear、nn.Embedding、nn.Conv2d三种。通过参数target_modules确定。target_modules是一个字符串列表,每一个字符串是需要进行LoRA的层名称,例如:
target_modules = ["q_proj","v_proj"]这里的 q_proj 即为注意力机制中的Wq,v_proj即为注意力机制中的Wv。我们可以根据模型架构和任务要求自定义需要进行LoRA操作的层。在创建 LoRA模型时,会获取该参数,然后在原模型中找到对应的层,该操作主要通过使用re对层名进行正则匹配实现:
#找到模型的各个组件中,名字里带“q_proj","v_proj"的
target_module_found = re.fullmatch(self.peft_config.target_modules, key)
# 这里的 key,是模型的组件名2、对每一个要使用LoRA的层,替换为LoRA层。所谓LoRA层,实则是在该层原结果基础上增加了一个旁路,通过低秩分解(即矩阵A和矩阵B)来模拟参数更新。然后对于每一个找到的目标层,创建一个新的lora层:
#注意这里的Linear是在该py中新建的类,不是torch的Linear
new_module=Linear(target .in_features,target.out_features,bias=bias,**kwargs)最后调用_replace_module方法替换掉原来的linear:
self._replace_module(parent,target_name, new_module,target)replace方法,就是把原来的weight和bias赋给新创建的module,然后再分配到指定的设备上:
def _replace_module(self,parent_module,child_name,new_module,old_module):
setattr(parent_module,child_name,new_module)
new_module.weight = old_module.weight
if old_module.bias is not None:
new_module.bias =old_module.bias
if getattr(old_module,"state", None) is not None:
new_module.state =old_module.state
new_module.to(old_module.weight.device)
# dispatch to correct device
for name, module in new_module.named_modules():
if "lora_" in name:
module.to(old_module.weight .device)3、冻结原参数,进行微调,更新LoRA层参数。
实现了LoRA层的替换后,进行微调训练即可。由于在LoRA层中已冻结原参数,在训练中只有A和B的参数会被更新,从而实现了高效微调.
使用PEFT对LORA的实现
peft进行了很好的封装,支持我们便捷、高效地对大模型进行微调。
1、加载所需使用的库:
import transformers
from peft import(
LoraConfig,
get_peft_model,
get_peft_model_state_dict,
prepare_modeI_for_int8_training,
set_peft_model_state_dict,
)
from transformers import LlamaForCausalM,LlamaTokenizer 2、使用transformer加载原模型和原tokenizer:
model=LlamaForCausalLM.from_pretrained(
base model,
load_in_8bit=True,
torch_dtype=torch.float16,
device_map=device_map,
)
tokenizer =LlamaTokenizer.from_pretrained(base_model) 3、设定peft参数,获取LoRA模型:
#设置超参数及配置
LORA R=8
LORA_ALPHA = 16
LORA_DROPOUT= 0.05
TARGET_MODULES =[
"q_proj",
"v_proj",
]
config =LoraConfig(
r=LORA_R,
lora_alpha=LORA ALPHA,
target_modules=TARGET_MODULES,
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
)
#创建基础transformer模型
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
#加入PEFT策略
model = get_peft_model(model,config)
注意,对不同的模型,LoRA参数可能有所区别。例如,对于ChatGLM,无需指定target_modeules,peft 可以自行找到;对于BaiChuan,就需要手动指定。task_type是模型的任务类型,大模型一般都是CAUSAL LM 即传统语言模型
4、使用transformers 提供的Trainer进行训练即可:
trainer= Trainer(
model=model,
train_dataset=dataset,
args=training_args,
data_collator=lambda x: data_collator_glm(x, tokenizer),
)
trainer.train() 
















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









