







🧙♂️ 诸位好,吾乃斜杠君,编程界之翘楚,代码之大师。算法如流水,逻辑如棋局。
📜 吾之笔记,内含诸般技术之秘诀。吾欲以此笔记,传授编程之道,助汝解技术难题。
📄 吾之文章,不以繁复之言,惑汝耳目;但以浅显之语,引汝入胜。
🚀 若此文对阁下有所裨益,敬请👍🏻-点赞 ⭐ - 收藏 👀 - 关注,不胜感激。
什么是EMO
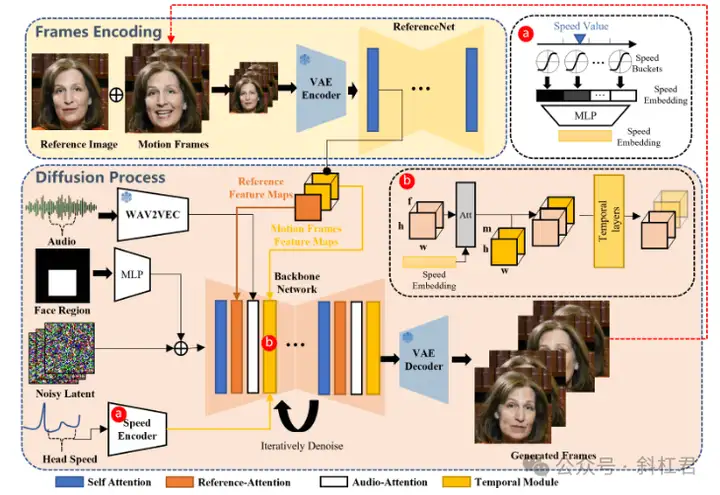
EMO(Emote Portrait Alive)是由阿里巴巴集团智能计算研究院开发的一个音频驱动的AI肖像视频生成系统,它能够通过单一的参考图像和语音音频,生成具有表现力的面部表情和各种头部姿势的视频。这一技术的核心在于其高度的表现力和逼真度,能够捕捉并再现人类面部表情的细微差别,包括微妙的微表情,以及与音频节奏相匹配的头部运动。
EMO的主要特点包括:
1.音频驱动的视频生成:无需依赖预先录制的视频片段或3D面部模型,直接根据输入的音频生成视频。
2.高表现力和逼真度:视频生成质量高,能够再现人类表情的细微差别。
3.无缝帧过渡:确保视频帧之间的过渡自然流畅。
4.身份保持:通过FrameEncoding模块保持角色外观与输入图像的一致性。
5.稳定的控制机制:采用速度控制器和面部区域控制器增强稳定性。
6.灵活的视频时长:根据输入音频长度生成任意时长的视频。
7.跨语言和跨风格:适应多种语言和艺术风格,包括中文、英文以及现实主义、动漫和3D风格。
技术报告地址:https://arxiv.org/abs/2402.17485
EMO的使用方法
在手机的软件平台下载通义千问APP,在选择“频道”->“全民舞台”,即可进入使用。
EMO的使用方法简单直观,用户可以通过通义App体验这一前沿技术。首批上线了80多个EMO模板,包括热门歌曲和网络热梗等。用户可以在歌曲、热梗、表情包中任选一款模板,上传一张肖像照片,EMO随即合成演戏唱歌视频。
就是生成时间有些漫长,大概需要15-20分钟左右。

EMO的使用场景
EMO技术的潜力巨大,未来有望应用于数字人、数字教育、影视制作、虚拟陪伴、电商直播等场景。它将为内容创作者提供更多的可能性,使得创意表达不再受限于传统的视频制作方式。随着技术的不断进步和优化,EMO有望成为AI领域的一个重要里程碑。
好了,关于阿里EMO的项目就为大家分享到这里。我为大家整理了关于阿里EMO项目的相关网址,大家可以到这里了解更详细的信息,可以亲自体验一下哦 :)
官方主页:https://humanaigc.github.io/emote-portrait-alive/
研究论文:https://arxiv.org/abs/2402.17485
GitHub地址:https://github.com/HumanAIGC/EMO
🧙♂️ 诸位好,我是斜杠君。全栈技术,正在从事AI应用领域的研究,如果您有关于 AI 或 AI工作流 的特别需求或问题,可以通过 爱发电 向我提问。

👑 阁下若觉此文有益,恳请👍🏻-点赞 ⭐ - 收藏 👀 - 关注,以资鼓励。倘若有疑问或建言,亦请在评论区💬评论 赐教,吾将感激不尽。
欢迎关注我的公众号



















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









