










、互联带宽
CUDA-samples测试
平台
Pro WS WRX90E-SAGE SE
AMD Ryzen Threadripper PRO 7975WX 32-Cores
0/257 GB
PCIE 5.0 平台
安装完驱动和最新的CUDA toolkit
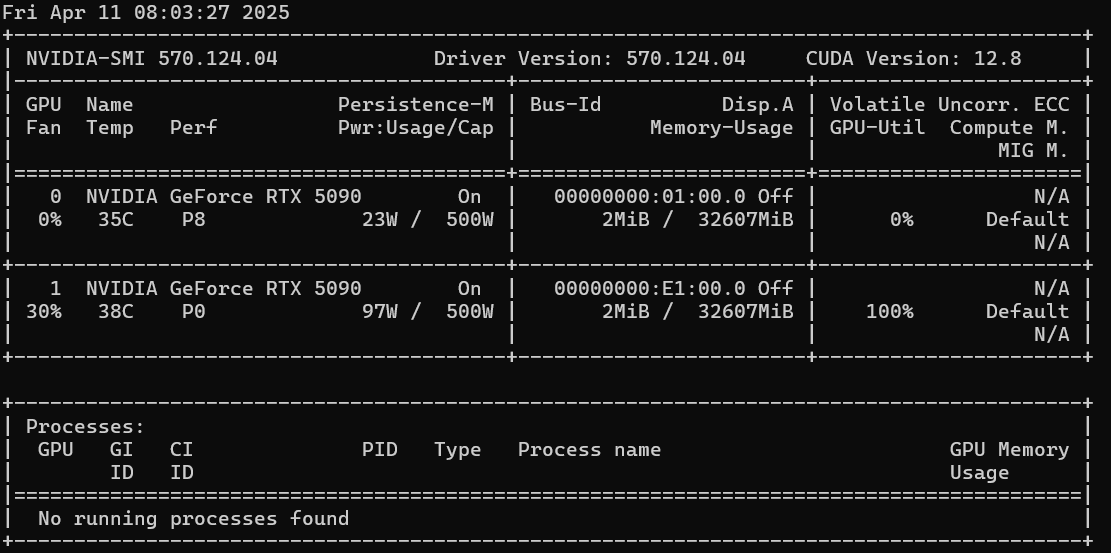
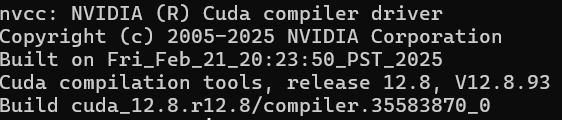
从nvidia官方cuda仓库中,可以下载到cudasamples(但是不能安装最新的12.8,只能装12.4,12.8实测在12.8.96驱动中编译不通过)

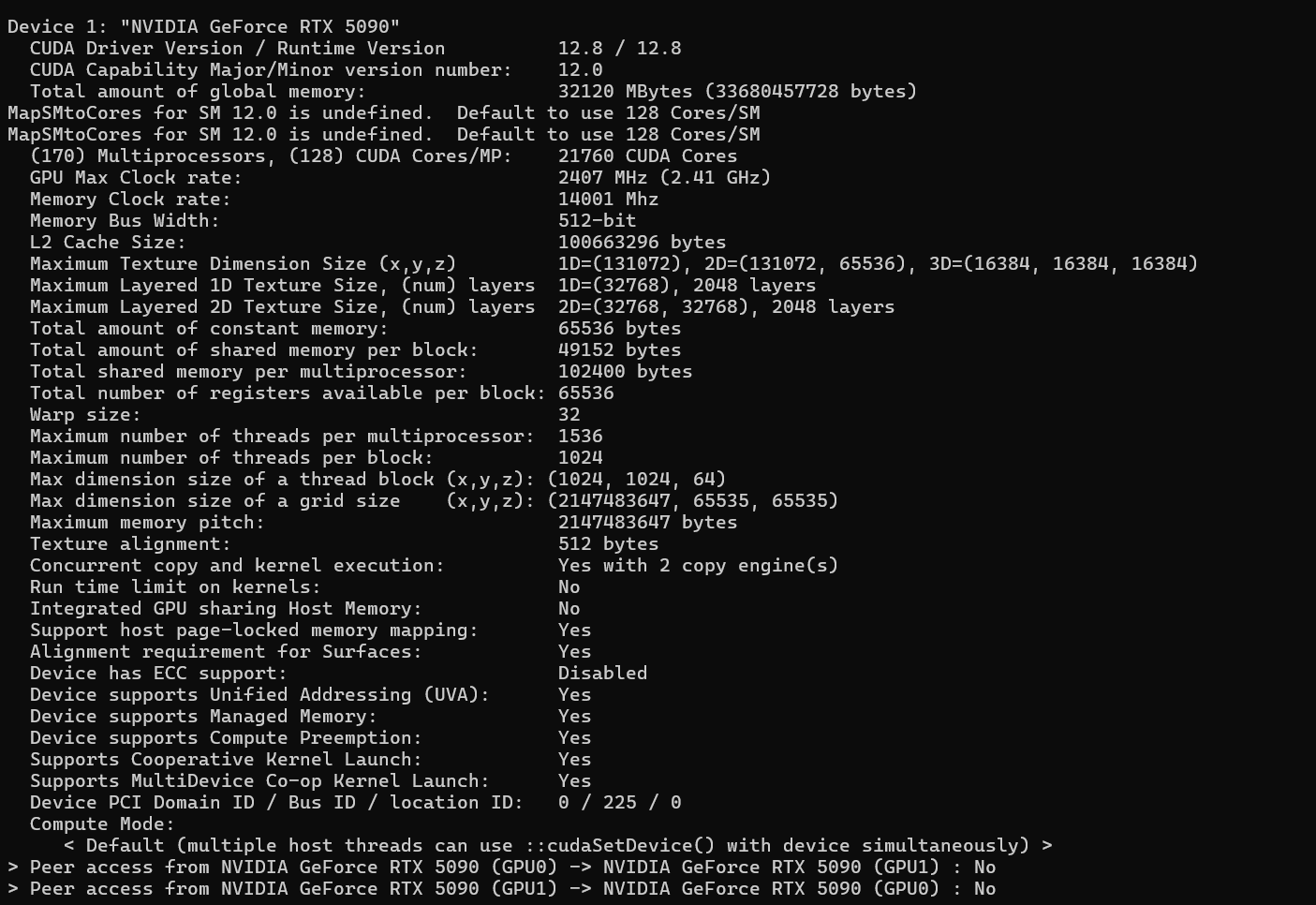
git clone https://github.com/NVIDIA/cuda-samples.gitdevicequery结果
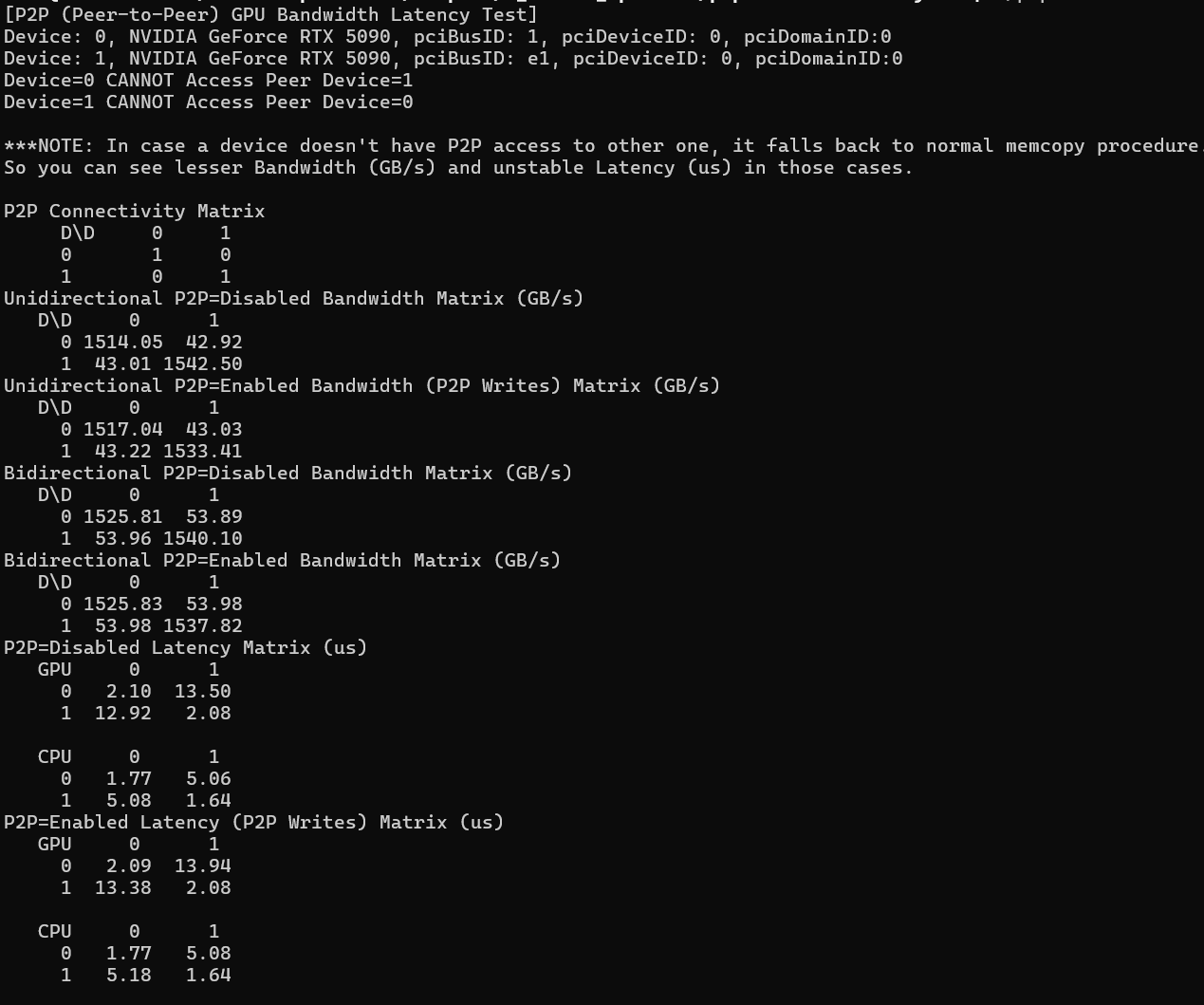
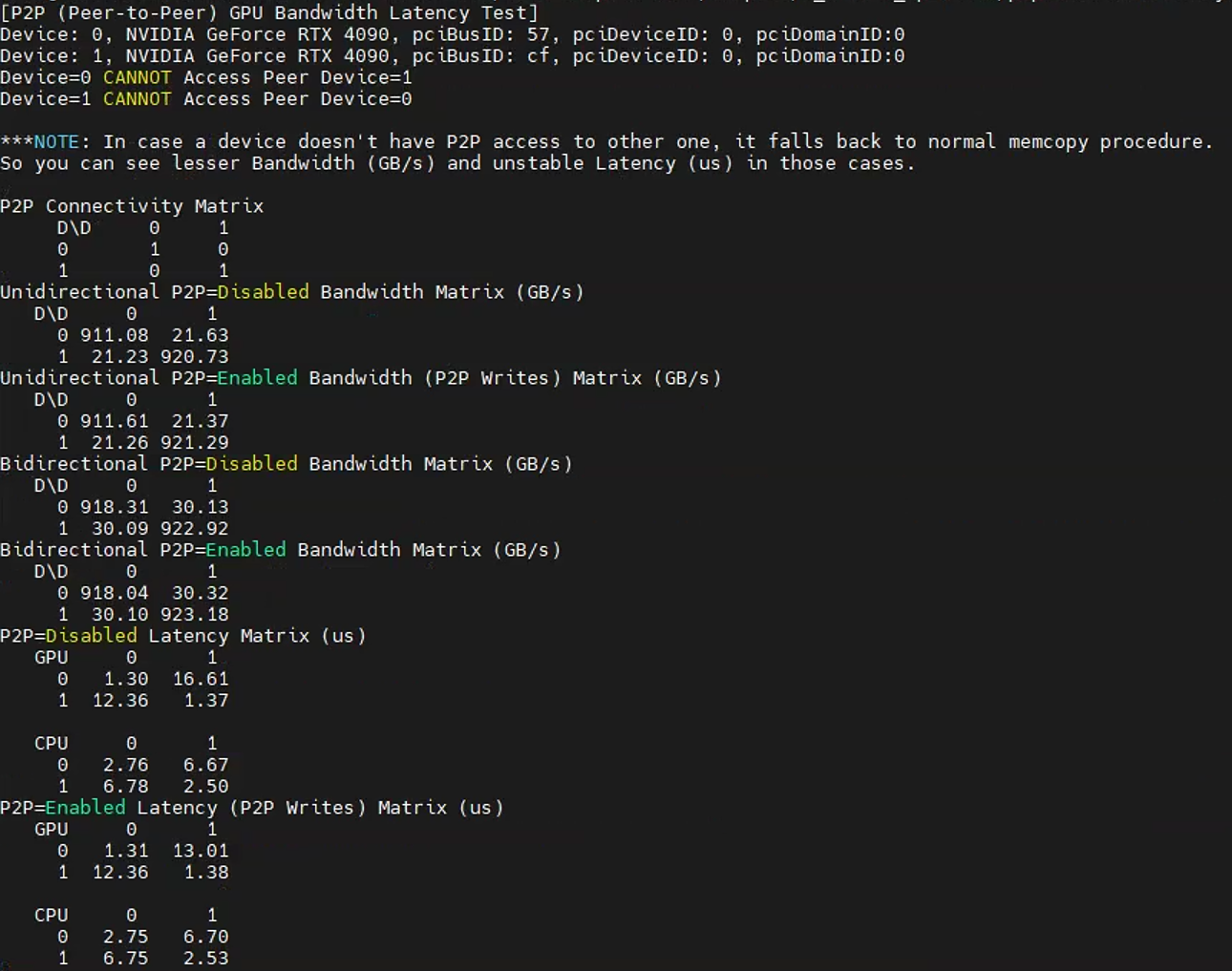
p2p带宽测试结果
可以看到峰值能来到50Gb/s左右,比就算4090开启了P2P后的性能也快了一倍左右
NCCL带宽测试
由于5090属于sm120,在目前cuda12.8中的nccl仍对其有支持上的问题,因此需要手动重新编译安装最新版的NCCL通信库
移除现有NCCL
apt-get remove --purge libnccl2 libnccl-dev -y
apt-get autoremove --purge -y下载最新NCCL
git clone https://github.com/NVIDIA/nccl.git & cd nccl/安装依赖
apt update
apt install build-essential devscripts debhelper fakeroot -y编译NCCL(可加-j参数多核编译)
make pkg.debian.build安装最新的NCCL
cd /build/pkg/deb/
dpkg -i libnccl-dev_2.26.2-1+cuda12.8_amd64.deb libnccl2_2.26.2-1+cuda12.8_amd64.deb安装完成后,可以通过安装nccl-tesl来测试安装是否正确
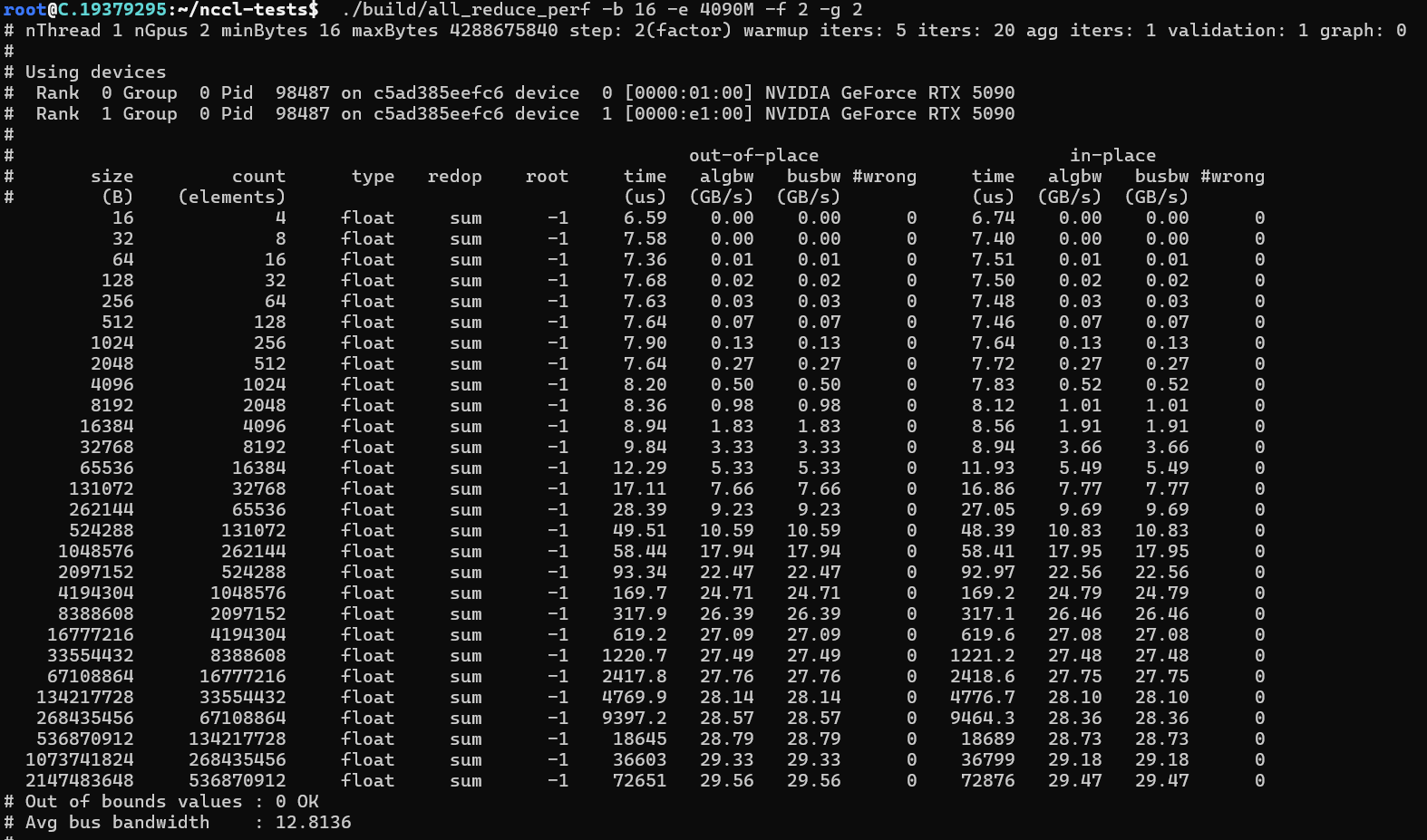
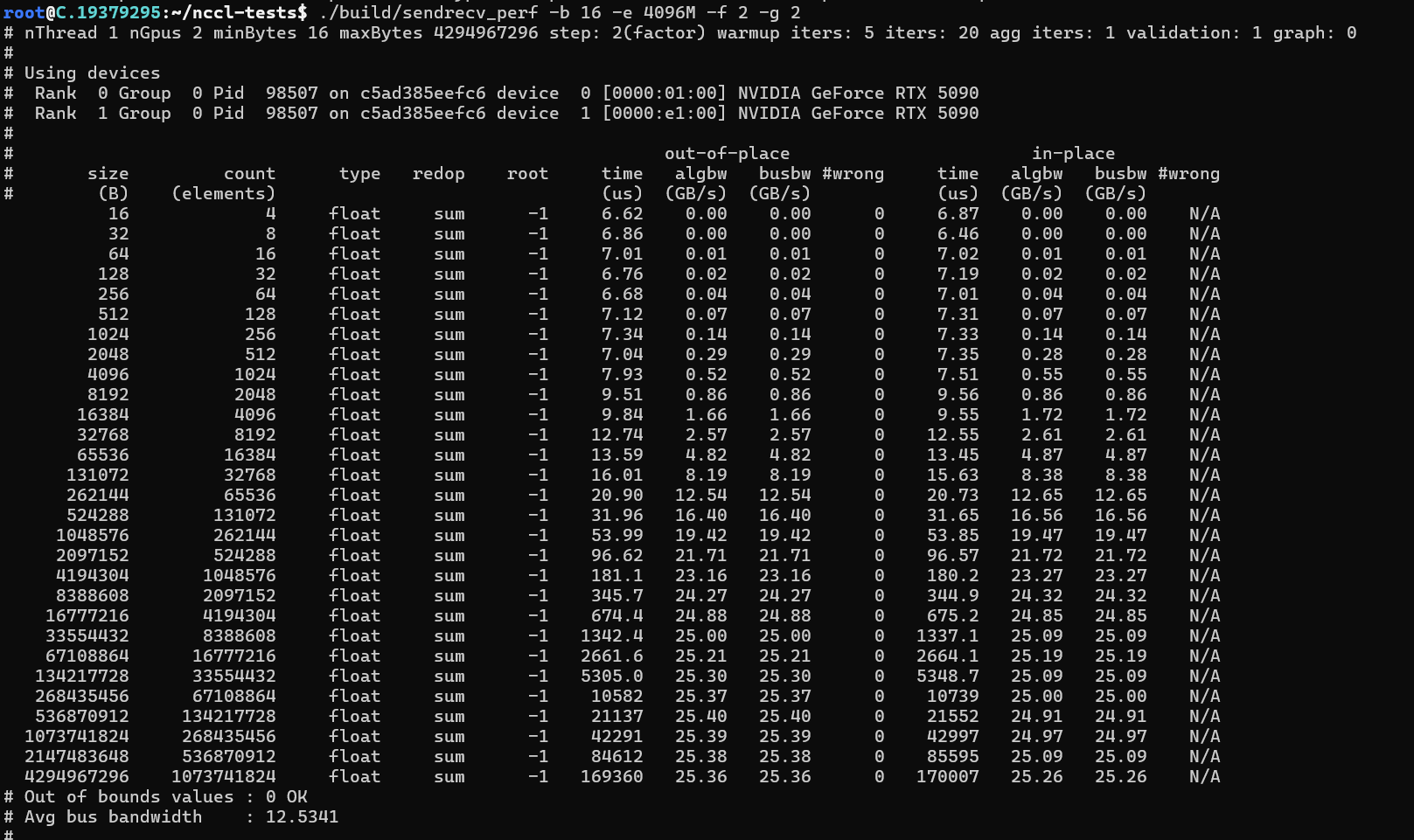
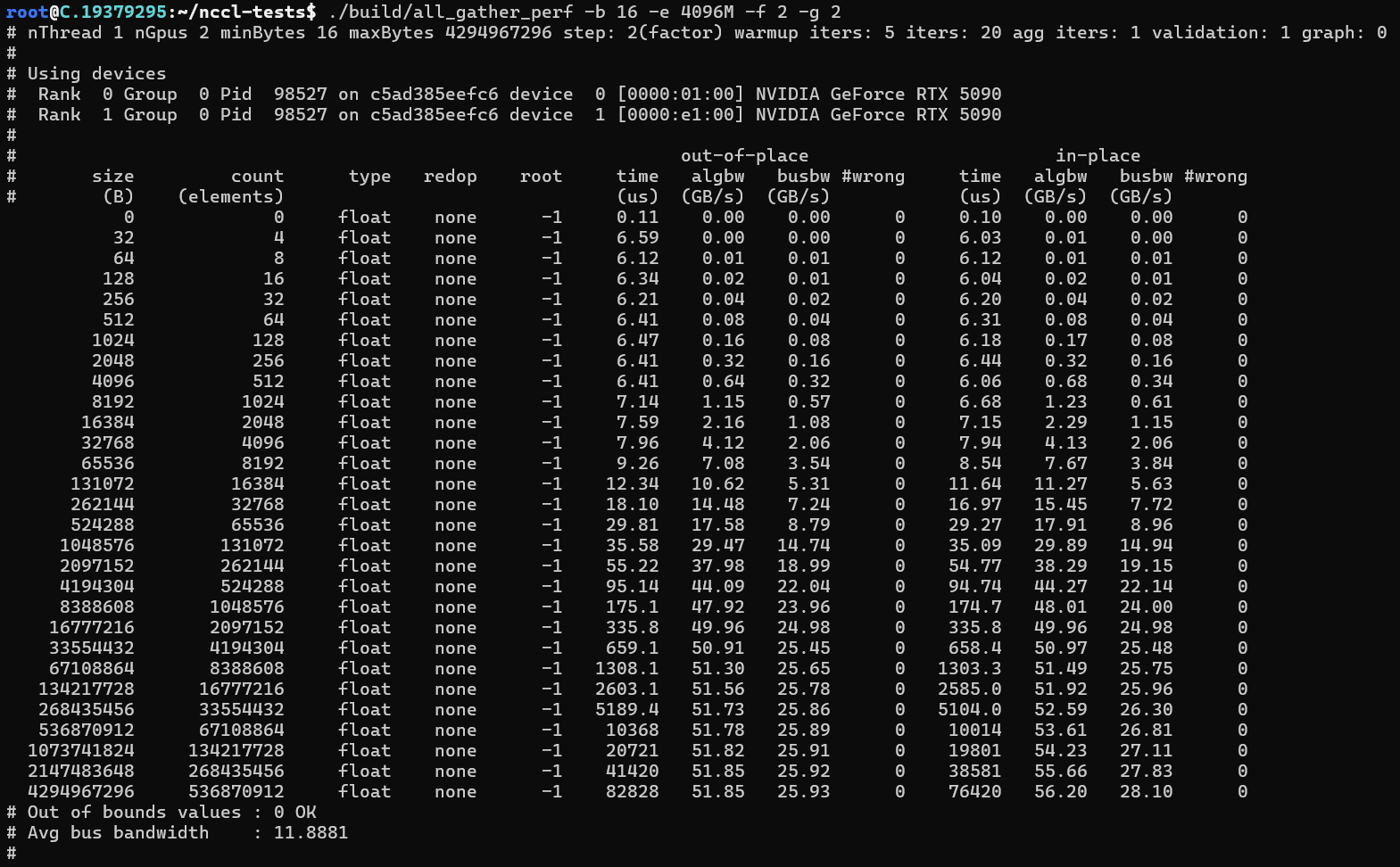
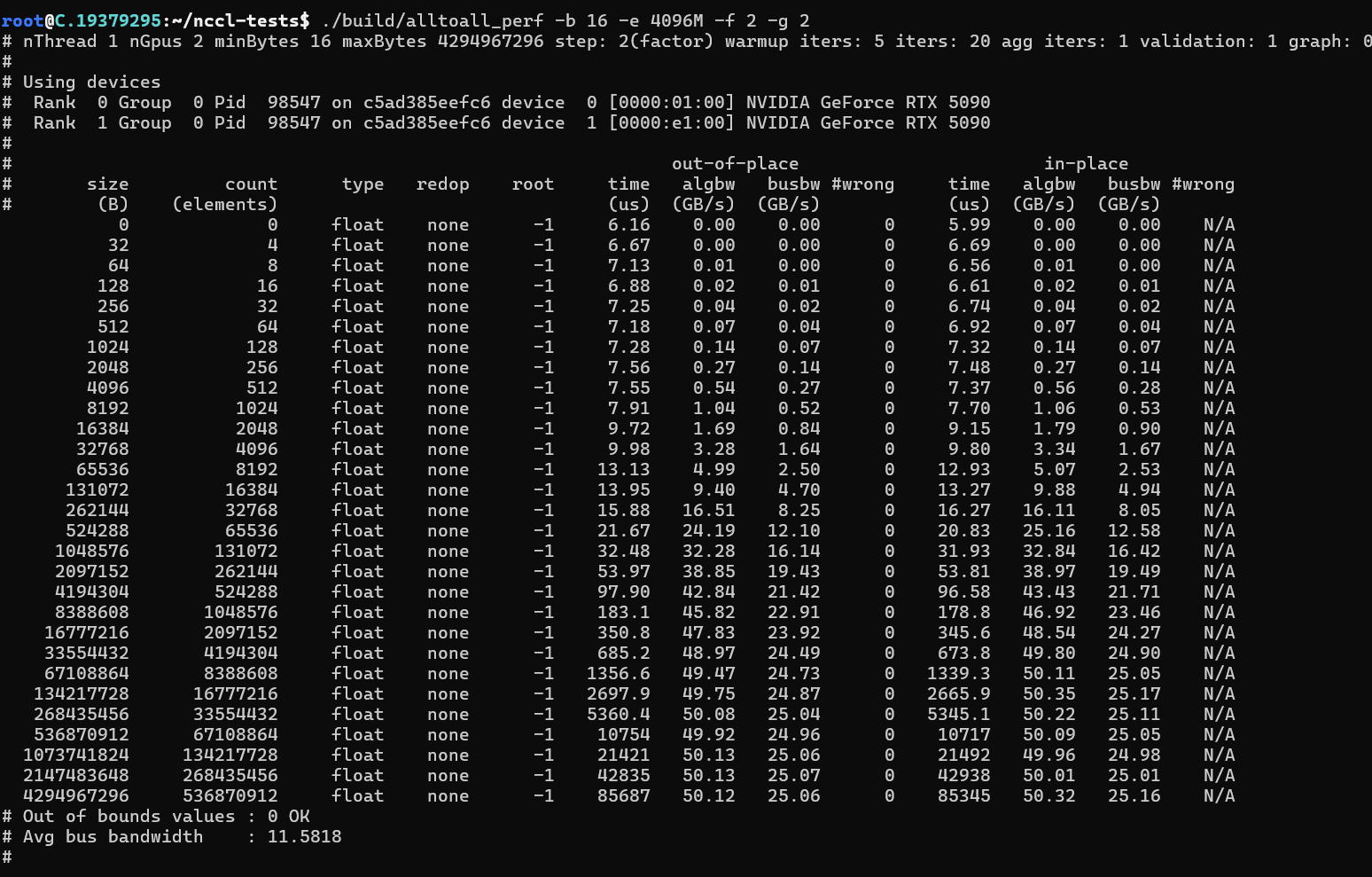
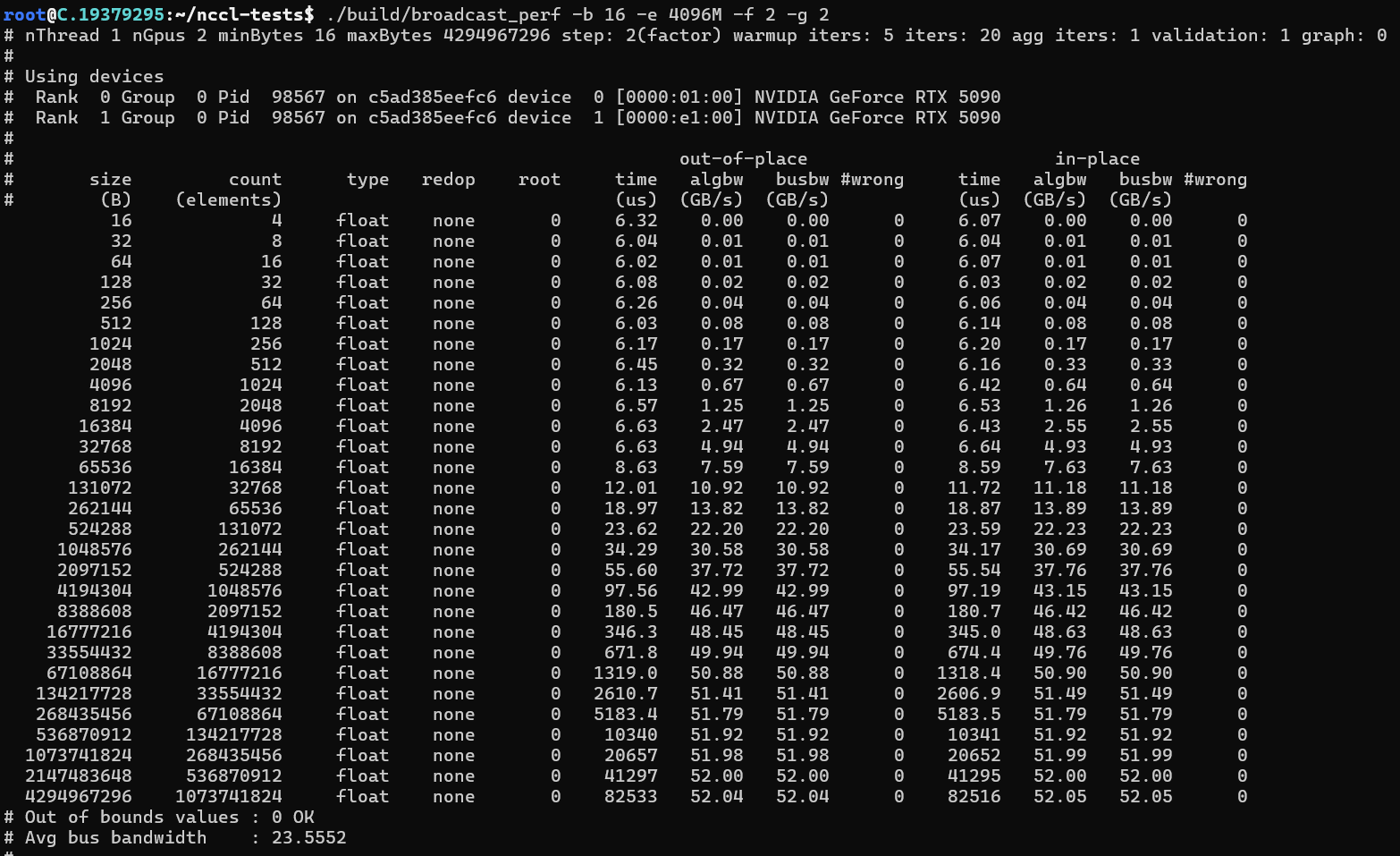
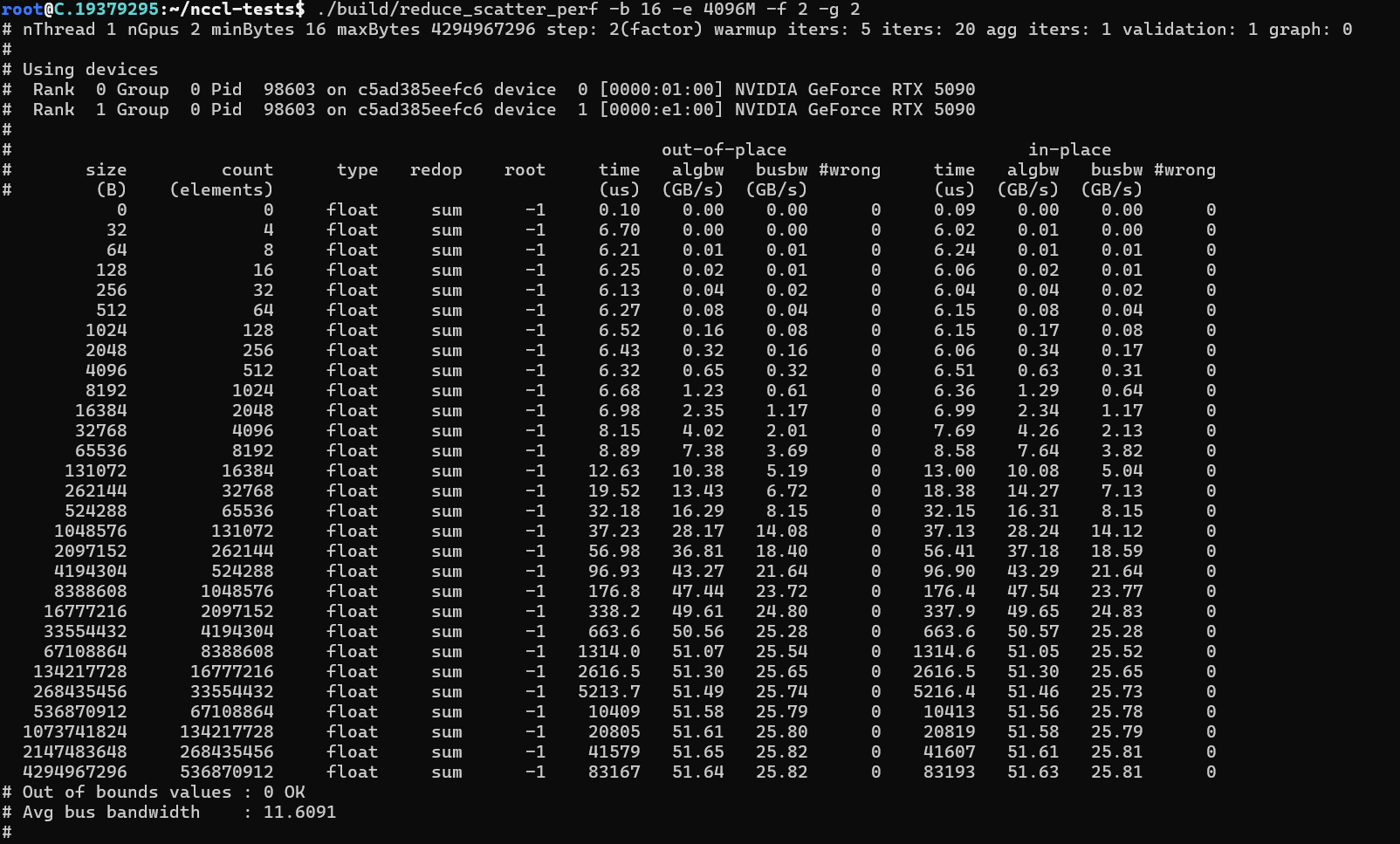
推理性能测试
VLLM
从github上下载最新的vllm
git clone https://github.com/vllm-project/vllm.git && cd vllmpython use_existing_torch.py
安装依赖
pip install -r requirements/build.txt
pip install setuptools_scm创建ccache文件夹
mkdir <path/to/ccache/dir>编译安装
MAX_JOBS=<number> CCACHE_DIR=<path/to/ccache/dir> python setup.py develop安装完成后,即可用python检查vllm版本
python -c "import vllm; print(vllm.__version__)"



















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











