






学习手册中给的建议是这样的:
-
特征选择与删除:分析特征的重要性,可以使用特征选择方法(如基于模型的特征重要性)来选择最具有预测能力的特征,也可以删除一些对模型性能影响较小的特征。
-
特征组合与交互:将不同特征进行组合、相乘、相除等操作,创建新的特征,以捕捉特征之间的复杂关系。
-
数值型特征的分桶(Binning):将连续的数值型特征划分为多个区间,可以提高模型对特征的鲁棒性。
-
类别型特征的编码:除了One-Hot编码外,可以尝试使用其他编码方式,如Label Encoding、Target Encoding等,来更好地处理类别型特征。
-
时间特征的挖掘:除了示例中的日期和小时提取,还可以尝试提取星期几、月份等时间信息,可能会影响用户行为。
-
特征缩放:对数值型特征进行缩放,将它们映射到一个相似的范围,有助于模型收敛和性能提升。
由于本废物实力有限……:
只搞了特征选择与删除
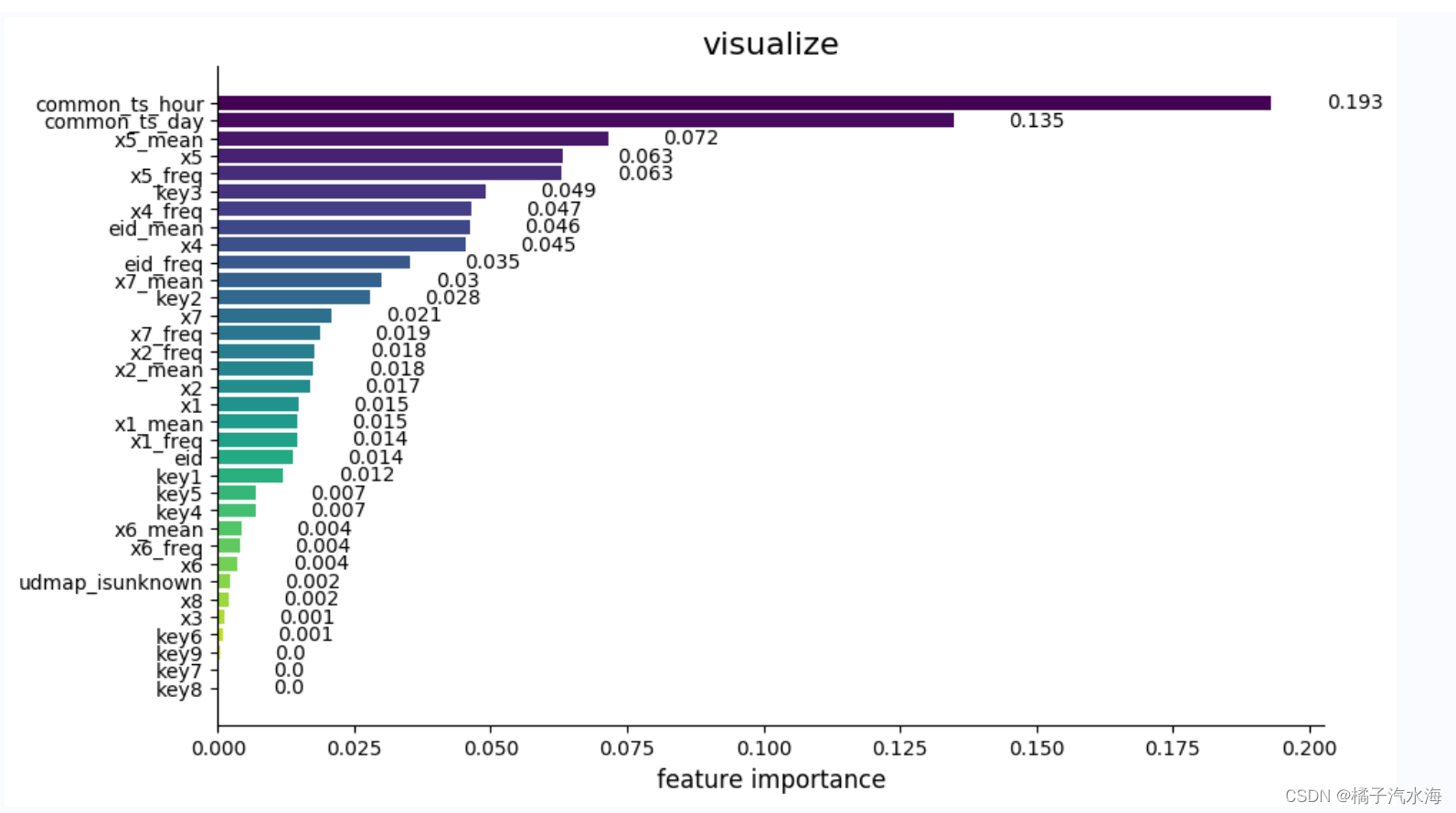
(受上次笔记得到的特征重要性的影响,训练模型时删除了key6-key9特征)
验证精度高了一点点。
然后因为上次笔记里发现加了一大堆特征模型精度验证结果变高,我就浩浩荡荡加了一大堆特征,精度又高了,我狂喜。

(过拟合的伏笔早早埋下惹!)
but由于老是报错有Nan,一开始填充中位数也不行,最后全填充0了。
还搞了下删除离群点
依旧抄的:[数据挖掘与分析]Kaggle实战技巧总结 - 知乎 (zhihu.com)
def detect_outliers(df,n,features):
outlier_indices=[]
#迭代每一个特征
for col in features:
#计算四分位数
Q1=np.percentile(df[col],25)
Q3=np.percentile(df[col],75)
#计算IQR Interquartile range 四分位差
IQR=Q3-Q1
#Outlier Step
outlier_step=1.5*IQR
#判断每个特征内的离群点
outlier_index=df[(df[col] > Q3+outlier_step) | (df[col] < Q1-outlier_step)].index
outlier_indices.extend(outlier_index)
#只有当n个以上的特征出现离群现象时,这个样本点才被判断为离群点
outlier_dict=Counter(outlier_indices) #统计样本点被判断为离群的次数,并返回一个字典
outlier_indices=[k for k,v in outlier_dict.items() if v > n]
return outlier_indices
然后删除了x3,x5的离群点(因为上次笔记箱型图发现x3离群点多,x5重要性高),验证数值又升高了
提交发现分数升到了0.73125
又稍微改了一下到了0.7314
结局:盛极必衰的过拟合和拉跨的最终分数
我就想着把各种特征都删一下异常值
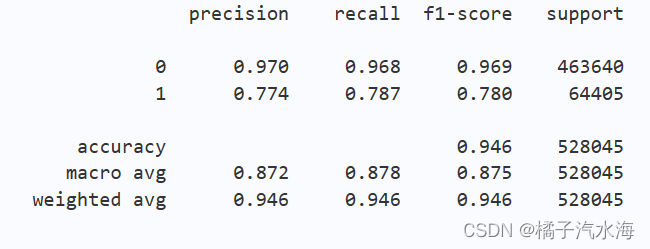
验证的精度显著提高,我就狂喜。
结果分数越来越低,又降回了0.69。我不信邪,结果更低了,直接0.64
然后我的三次机会就在徒劳的挣扎中用完了,分数悲伤地停在了0.7314
这时我才意识到模型过拟合了,but为时已晚/(ㄒoㄒ)/~~

















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









