







请大家关注我,本文章粉丝可见,我会一直更新下去,完整代码进QQ群获取:323140750,大家一起进步、学习。
FinBERT是基于BERT的模型,但经过了针对金融领域的预训练和微调。使用了金融领域的大量文本数据进行了预训练,从而使其在金融文本分类和情感分析等任务中表现出色。
9.4.1 FinBERT模型介绍
FinBERT模型的官方地址是: https://github.com/ProsusAI/finBERT,大家可以使用如下git命令将FinBERT下载到你的本地计算机,或者直接从GitHub页面下载ZIP文件。
git clone https://github.com/yiyanghkust/FinBERT.git
在网络结构上,FinBERT采用了与 Google 发布的原生BERT 相同的架构,包含了 FinBERT-Base 和 FinBERT-Large 两个版本,其中前者采用了 12 层 Transformer 结构,后者采用了 24 层 Transformer 结构。FinBERT 采用了两大类预训练任务,分别是字词级别的预训练和任务级别的预训练。其中,在任务级别的预训练上,为了让模型更好地学习到语义层的金融领域知识,更全面地学习到金融领域词句的特征分布,我们同时引入了两类有监督学习任务,分别是研报行业分类和财经新闻的金融实体识别任务,具体说明如下:
(1)研报行业分类
对于公司点评、行业点评类的研报,天然具有很好的行业属性,因此我们利用这类研报自动生成了大量带有行业标签的语料。并据此构建了行业分类的文档级有监督任务,各行业类别语料在 5k~20k 之间,共计约40万条文档级语料。
(2)财经新闻的金融实体识别
与研报行业分类任务类似,利用已有的企业工商信息库以及公开可查的上市公司董监高信息,基于金融财经新闻构建了命名实体识别类的任务语料,共包含有 50 万条的有监督语料。
9.4.2 基于FinBERT模型的市场情感分析系统
请看下面的实例,演示了使用预训练的深度学习模型FinBERT进行金融情感分类任务的过程,包括数据处理、模型微调、性能评估和预测。这有助于金融领域中对新闻标题等文本数据进行情感分析和情感预测。
实例9-5:金融市场情感分析(源码路径:daima/9/financial-classification.ipynb)
概括来说, 本实例实现了实现了以下功能:
- 加载预训练的金融情感分类模型(FinBERT)。
- 对金融新闻标题进行数据预处理,包括分词、编码、数据拆分等。
- 使用训练数据对模型进行微调(Fine-tuning)以适应金融情感分类任务。
- 通过训练和验证过程,监测模型性能并选择最佳模型。
- 加载最佳模型,并使用其进行情感分类预测。
- 计算并打印模型在验证集上的准确率和每个情感类别的准确率。
- 提供了一种在金融领域进行情感分类任务的示例,可以用于预测金融新闻标题的情感倾向。
本实例的具体实现流程如下所示。
(1)函数show_headline_distribution(sequence_lengths, figsize)用于分析新闻标题长度的分布情况,通过可视化直方图展示新闻标题长度的分布,以便了解标题长度的数据分布特征。它还计算了长度大于512的标题所占的百分比,提供了对极长标题的信息。具体实现代码如下所示。
# 显示新闻标题长度的分布
def show_headline_distribution(sequence_lengths, figsize=(15, 8)):
# 获取长度大于512的新闻标题所占的百分比
len_512_plus = [rev_len for rev_len in sequence_lengths if rev_len > 512]
percent = (len(len_512_plus) / len(sequence_lengths)) * 100
print("最大序列长度为 {}".format(max(sequence_lengths)))
# 配置图表大小
plt.figure(figsize=figsize)
sns.set(style='darkgrid')
# 增加图表上的信息
sns.set(font_scale=1.3)
# 绘制结果
sns.distplot(sequence_lengths, kde=False, rug=False)
plt.title('新闻标题长度分布')
plt.xlabel('新闻标题长度')
plt.ylabel('新闻标题数量')(2)函数show_random_headlines(total_number, df)用于随机选择指定数量的新闻标题,并打印它们的情感标签和标题文本。这有助于查看数据集中的随机样本,以了解情感标签和标题之间的关系。具体实现代码如下所示。
# 显示随机新闻标题
def show_random_headlines(total_number, df):
# 随机抽取一定数量的新闻标题
n_reviews = df.sample(total_number)
# 打印每个新闻标题
for val in list(n_reviews.index):
print("新闻 #{}".format(val))
print(" - 情感: {}".format(df.iloc[val]["sentiment"]))
print(" - 新闻标题: {}".format(df.iloc[val]["NewsHeadline"]))
print("")(3)函数get_headlines_len(df)的主要目的是计算每个新闻标题的长度,并返回一个包含所有标题长度的列表。它通过对新闻标题进行编码来实现,以便后续的情感分析任务可以使用这些编码后的数据。具体实现代码如下所示。
# 获取新闻标题的长度
def get_headlines_len(df):
headlines_sequence_lengths = []
print("编码中...")
for headline in tqdm(df.NewsHeadline):
encoded_headline = finbert_tokenizer.encode(headline, add_special_tokens=True)
# 记录编码后的新闻标题长度
headlines_sequence_lengths.append(len(encoded_headline))
print("任务结束.")
return headlines_sequence_lengths(4)函数encode_sentiments_values(df)用于将情感标签(例如"positive"、"negative")编码为数字,以便在深度学习模型中进行处理。它创建一个情感标签到数字编码的映射,并将数据集中的情感标签替换为相应的数字。具体实现代码如下所示。
# 编码情感值
def encode_sentiments_values(df):
possible_sentiments = df.sentiment.unique()
sentiment_dict = {}
for index, possible_sentiment in enumerate(possible_sentiments):
sentiment_dict[possible_sentiment] = index
# 编码所有情感值
df['label'] = df.sentiment.replace(sentiment_dict)
return df, sentiment_dict(5)函数f1_score_func(preds, labels)的功能是计算F1得分,用于评估模型在情感分类任务中的性能。它通过比较模型的预测结果和真实标签来计算F1得分,考虑了精确度和召回率。具体实现代码如下所示。
# F1得分函数
def f1_score_func(preds, labels):
preds_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return f1_score(labels_flat, preds_flat, average='weighted')(6)函数accuracy_per_class(preds, labels):用于计算每个情感类别的分类准确度。它将模型的预测结果与真实标签进行比较,并为每个情感类别计算准确度,以评估模型在不同情感类别上的性能。具体实现代码如下所示。
# 每个类别的准确度
def accuracy_per_class(preds, labels):
label_dict_inverse = {v: k for k, v in sentiment_dict.items()}
preds_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
for label in np.unique(labels_flat):
y_preds = preds_flat[labels_flat==label]
y_true = labels_flat[labels_flat==label]
print(f'类别: {label_dict_inverse[label]}')
print(f'准确度: {len(y_preds[y_preds==label])}/{len(y_true)}\n')(7)函数evaluate(dataloader_val)用于评估模型的性能,包括计算验证集上的损失和生成预测结果。它在模型训练过程中用于监测模型的性能,并返回损失值、预测结果和真实标签,以便进一步的分析和评估。具体实现代码如下所示。
# 评估函数
def evaluate(dataloader_val):
model.eval()
loss_val_total = 0
predictions, true_vals = [], []
for batch in dataloader_val:
batch = tuple(b.to(device) for b in batch)
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'labels': batch[2],
}
with torch.no_grad():
outputs = model(**inputs)
loss = outputs[0]
logits = outputs[1]
loss_val_total += loss.item()
logits = logits.detach().cpu().numpy()
label_ids = inputs['labels'].cpu().numpy()
predictions.append(logits)
true_vals.append(label_ids)
loss_val_avg = loss_val_total/len(dataloader_val)
predictions = np.concatenate(predictions, axis=0)
true_vals = np.concatenate(true_vals, axis=0)
return loss_val_avg, predictions, true_vals(8)使用库Pandas从指定路径加载CSV文件,并将其存储在名为financial_data的DataFrame中。具体实现代码如下所示。
path_to_file = "../input/financialnewsheadline/FinancialNewsHeadline.csv"
financial_data = pd.read_csv(path_to_file, encoding='latin-1', names=['sentiment', 'NewsHeadline'])
financial_data.head()在文件FinancialNewsHeadline.csv中包含了多个新闻标题及其情感标签,每个新闻标题都附带一个情感标签,标记了新闻标题的情感极性,包括neutral(中性)、negative(负面)和positive(正面)。这些数据可以用于情感分析或其他自然语言处理任务的训练和分析。执行后会输出:
sentiment NewsHeadline
0 neutral According to Gran , the company has no plans t...
1 neutral Technopolis plans to develop in stages an area...
2 negative The international electronic industry company ...
3 positive With the new production plant the company woul...
4 positive According to the company 's updated strategy f...(9)打印输出关数据集的一些基本信息,包括数据的形状和情感标签的分布。具体实现代码如下所示。
print("Data shape: {}".format(financial_data.shape))
print("\nSentiment distribution: {}".format(financial_data.sentiment.value_counts()))对上述代码的具体说明如下:
- print("Data shape: {}".format(financial_data.shape)):打印数据集的形状,即行数和列数。这将显示数据集中有多少行和多少列。
- print("\nSentiment distribution: {}".format(financial_data.sentiment.value_counts())):打印情感标签的分布情况。value_counts()函数用于计算每个不同情感标签的出现次数,以便了解数据集中每个情感标签的样本数量。在打印之前,通过\n添加一个换行符,以使输出更易读。
执行后会输出:
Data shape: (4846, 2)
Sentiment distribution: neutral 2879
positive 1363
negative 604
Name: sentiment, dtype: int64(10)绘制情感标签的分布情况图表,以可视化展示数据集中每个情感标签的样本数量。具体实现代码如下所示。
plt.figure(figsize = (15,8))
sns.set(style='darkgrid')
sns.set(font_scale=1.3)
sns.countplot(x='sentiment', data = financial_data)
plt.title('News Sentiment Distribution')
plt.xlabel('News Polarity')
plt.ylabel('Number of News')执行后会生成一个柱状图,如图9-1所示。这样直观地展示了每种情感标签在数据集中的分布情况,有助于了解数据集中不同情感标签的相对频率。这对于数据的初步探索性分析(EDA)非常有用。
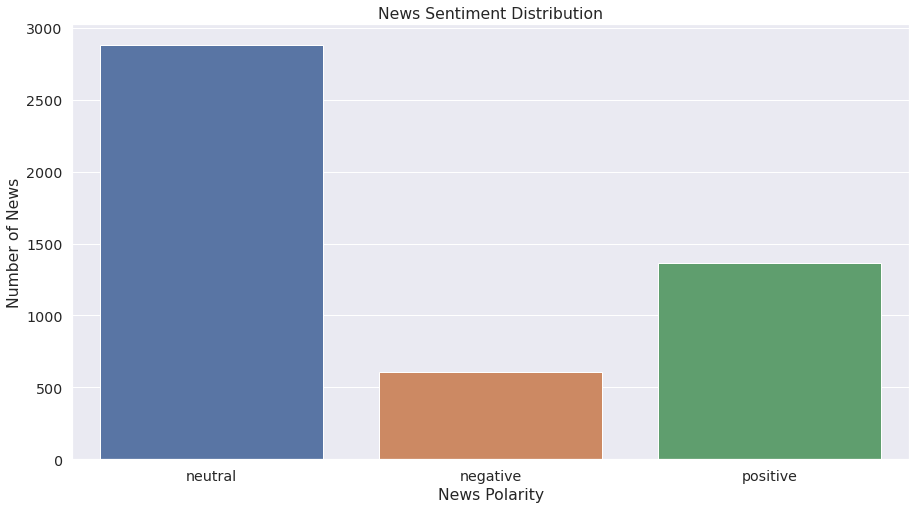
图9-1 每种情感标签在数据集中的分布情况
(11)调用了之前定义的show_random_headlines函数,以显示随机选择的5个新闻标题以及它们的情感标签。具体实现代码如下所示。
show_random_headlines(5, financial_data)执行后将随机选择5个样本,并打印每个样本的情感标签和新闻标题文本,以便查看这些数据的样本内容和情感标签。
(12)调用前面定义的encode_sentiments_values函数,将其返回的结果存储在名为financial_data的DataFrame中,并获得了情感标签到数字编码的映射sentiment_dict。具体实现代码如下所示。
financial_data, sentiment_dict = encode_sentiments_values(financial_data)
financial_data.head()执行后显示经编码后的数据集的前几行,以便查看情感标签已经以数字形式表示的数据。这有助于后续的建模和分析工作,因为模型通常需要处理数字形式的标签而不是文本标签。
未完待续

















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











