







(13)开始实现分类器(ANN)功能,使用outputX作为Classifier的输入。代码如下:
Y_Train = train_Y.iloc[:3051].values
Y_Test = train_Y.iloc[3052:].values
Y_Test.shape
X_New_Train = outputX
X_New_Train = X_New_Train[:3051, :]
Y_Train = Y_Train.reshape((-1,1))
X_Test = outputX
X_Test = X_Test[3052:, :]
classifier = Sequential()
#检查输入尺寸的输出X_DBN
classifier.add(Dense (6, activation = 'relu', input_dim = 12))
#h隐藏
classifier.add(Dense (6, activation = 'relu'))
#输出
classifier.add(Dense(1, activation = 'sigmoid'))
# optimizer = keras.optimizers.Adam(lr=0.002)
# classifier.compile(optimizer = optimizer, loss = 'binary_crossentropy', metrics = ['accuracy'])
classifier.compile(optimizer = 'Adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
classifier.fit(X_New_Train, Y_Train, batch_size = 100, epochs = 200)执行后会输出:
Train on 3051 samples
Epoch 1/200
3051/3051 [==============================] - 0s 12us/sample - loss: 0.7015 - acc: 0.4782
Epoch 2/200
3051/3051 [==============================] - 0s 9us/sample - loss: 0.6934 - acc: 0.5015
Epoch 3/200
3051/3051 [==============================] - 0s 9us/sample - loss: 0.6904 - acc: 0.5477
Epoch 4/200
3051/3051 [==============================] - 0s 10us/sample - loss: 0.6891 - acc: 0.5726
Epoch 5/200
3051/3051 [==============================] - 0s 11us/sample - loss: 0.6880 - acc: 0.5719
Epoch 6/200
3051/3051 [==============================] - 0s 10us/sample - loss: 0.6869 - acc: 0.5736
Epoch 7/200
......
Epoch 198/200
3051/3051 [==============================] - 0s 12us/sample - loss: 0.6751 - acc: 0.5739
Epoch 199/200
3051/3051 [==============================] - 0s 11us/sample - loss: 0.6750 - acc: 0.5775
Epoch 200/200
3051/3051 [==============================] - 0s 12us/sample - loss: 0.6749 - acc: 0.5778
<tensorflow.python.keras.callbacks.History at 0x7f7c91147470>(14)最后查看结果,代码如下:
y_pred = classifier.predict(outputX)
y_pred = (y_pred > 0.5)
pred = (train_Y[3052:] > 0.5)
yty = np. count_nonzero(pred)
yty
outputX.shape执行后会输出:
104
(3390, 12)(15)实现混淆矩阵处理,代码如下:
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(train_Y[3051:], y_pred[3051:])
print(cm)执行后会输出:
[[ 90 145]
[ 29 75]](16)查看本方案的最终得分成绩,代码如下:
def f1score( tn, fp, fn, tp):
precision = tp/(tp + fp)
print('precision',precision)
recall = tp/(tp+fn)
print('recall',recall)
return 2 * (precision * recall) / (precision + recall)
tn, fp, fn, tp = confusion_matrix(train_Y, y_pred, labels=[0,1]).ravel()
print(f1score(tn, fp, fn, tp))执行后会输出:
precision 0.5503909643788011
recall 0.7470518867924528
0.633816908454227110.2.2 实现集成
编写文件JustInTime_SW_Pred_Ensemble.ipynb,使用 DBN 模型实现LogisticRegression、GaussianNB 和 RandomForestClassifier 的和集成。具体实现流程如下所示:
(1)导入CSV文件,并获取文件中的数据数目,代码如下:
bugzilla = pd.read_csv('/content/drive/My Drive/dataset/bugzilla.csv')
columba = pd.read_csv('/content/drive/My Drive/dataset/columba.csv')
jdt = pd.read_csv('/content/drive/My Drive/dataset/jdt.csv')
mozilla = pd.read_csv('/content/drive/My Drive/dataset/mozilla.csv')
platform = pd.read_csv('/content/drive/My Drive/dataset/platform.csv')
postgres = pd.read_csv('/content/drive/My Drive/dataset/postgres.csv')
df = pd.read_csv('/content/drive/My Drive/dataset/FinalDF.csv')
def normalize(x):
x = x.astype(float)
min = np.min(x)
max = np.max(x)
return (x - min)/(max-min)
def view_values(X, y, example):
label = y.loc[example]
image = X.loc[example,:].values.reshape([-1,1])
print(image)
print("Shape of dataframe: ", df.shape)执行后会输出:
Shape of dataframe: (227417, 17)(2)查看前5行数据中的信息,代码如下:
df = df.drop(['commitdate','transactionid'], axis=1)
df.head()执行后会输出:
ns nm nf entropy la ld lt fix ndev pd npt exp rexp sexp bug
0 1 1 3 0.579380 0.093620 0.000000 480.666667 1 14 596 0.666667 143 133.50 129 1
1 1 1 1 0.000000 0.000000 0.000000 398.000000 1 1 0 1.000000 140 140.00 137 1
2 3 3 52 0.739279 0.183477 0.208913 283.519231 0 23 15836 0.750000 984 818.65 978 0
3 1 1 8 0.685328 0.016039 0.012880 514.375000 1 21 1281 1.000000 579 479.25 550 0
4 2 2 38 0.769776 0.091829 0.072746 366.815789 1 21 6565 0.763158 413 313.25 405 0(3)开始实现深度信念网络,首先创建受限玻尔兹曼机类RBM,然后定义需要的超参数,并分别创建向前传递函数、向后传递函数和采样函数,其中h为隐藏层,v为可见层。代码如下:
class RBM(object):
def __init__(self, input_size, output_size,
learning_rate, epochs, batchsize):
#定义超参数
self._input_size = input_size
self._output_size = output_size
self.learning_rate = learning_rate
self.epochs = epochs
self.batchsize = batchsize
#使用零矩阵初始化权重和偏差
self.w = np.zeros([input_size, output_size], dtype=np.float32)
self.hb = np.zeros([output_size], dtype=np.float32)
self.vb = np.zeros([input_size], dtype=np.float32)
#向前传递,其中h为隐藏层,v为可见层
def prob_h_given_v(self, visible, w, hb):
return tf.nn.sigmoid(tf.matmul(visible, w) + hb)
#从RBM已学习的生成模型生成新特征
def rbm_output(self, X):
input_X = tf.constant(X)
_w = tf.constant(self.w)
_hb = tf.constant(self.hb)
_vb = tf.constant(self.vb)
out = tf.nn.sigmoid(tf.matmul(input_X, _w) + _hb)
hiddenGen = self.sample_prob(self.prob_h_given_v(input_X, _w, _hb))
visibleGen = self.sample_prob(self.prob_v_given_h(hiddenGen, _w, _vb))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
return sess.run(out), sess.run(visibleGen), sess.run(hiddenGen)
inputX = df.iloc[:,:-1].apply(func=normalize, axis=0).values
inputY= df.iloc[:,-1].values
print(type(inputX))
inputX = inputX.astype(np.float32)
#List to hold RBMs
rbm_list = []
#define parameters of RBMs we will train
# 14-20-12-12-2
# def __init__(self, input_size, output_size,learning_rate, epochs, batchsize):
rbm_list.append(RBM(14, 20, 0.1, 200, 100))
rbm_list.append(RBM(20, 12, 0.05, 200, 100))
rbm_list.append(RBM(12, 12, 0.05, 200, 100))(4)开始进行训练,为了实现更平衡的数据帧,使用函数drop()删除不必要的字符串列。在训练时需要设置限制玻尔兹曼机的参数,最后使用for循环遍历每个RBM输入输出列表。执行后会输出:
deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.cast` instead.
Epoch: 0 reconstruction error: 0.113313
Epoch: 1 reconstruction error: 0.117359
Epoch: 2 reconstruction error: 0.114953
Epoch: 3 reconstruction error: 0.111951
Epoch: 4 reconstruction error: 0.110032
Epoch: 5 reconstruction error: 0.111399
Epoch: 6 reconstruction error: 0.111426
Epoch: 7 reconstruction error: 0.108291
Epoch: 8 reconstruction error: 0.109852
Epoch: 9 reconstruction error: 0.107341
Epoch: 10 reconstruction error: 0.103858
Epoch: 11 reconstruction error: 0.107152
Epoch: 12 reconstruction error: 0.108607
Epoch: 13 reconstruction error: 0.102160
Epoch: 14 reconstruction error: 0.106119
Epoch: 15 reconstruction error: 0.107382
Epoch: 16 reconstruction error: 0.108130
......
Epoch: 145 reconstruction error: 0.125590
Epoch: 146 reconstruction error: 0.122321
Epoch: 147 reconstruction error: 0.125713
Epoch: 148 reconstruction error: 0.127262
Epoch: 149 reconstruction error: 0.123992 (5)使用for循环遍历上面的每个RBM输入输出列表,并循环绘制重建误差和RBM的可视化图,代码如下:
i = 1
for err in error_list:
print("RBM",i)
pd.Series(err).plot(logy=False)
plt.xlabel("Epoch")
plt.ylabel("Reconstruction Error")
plt.show()
i += 1执行效果如图10-7所示。
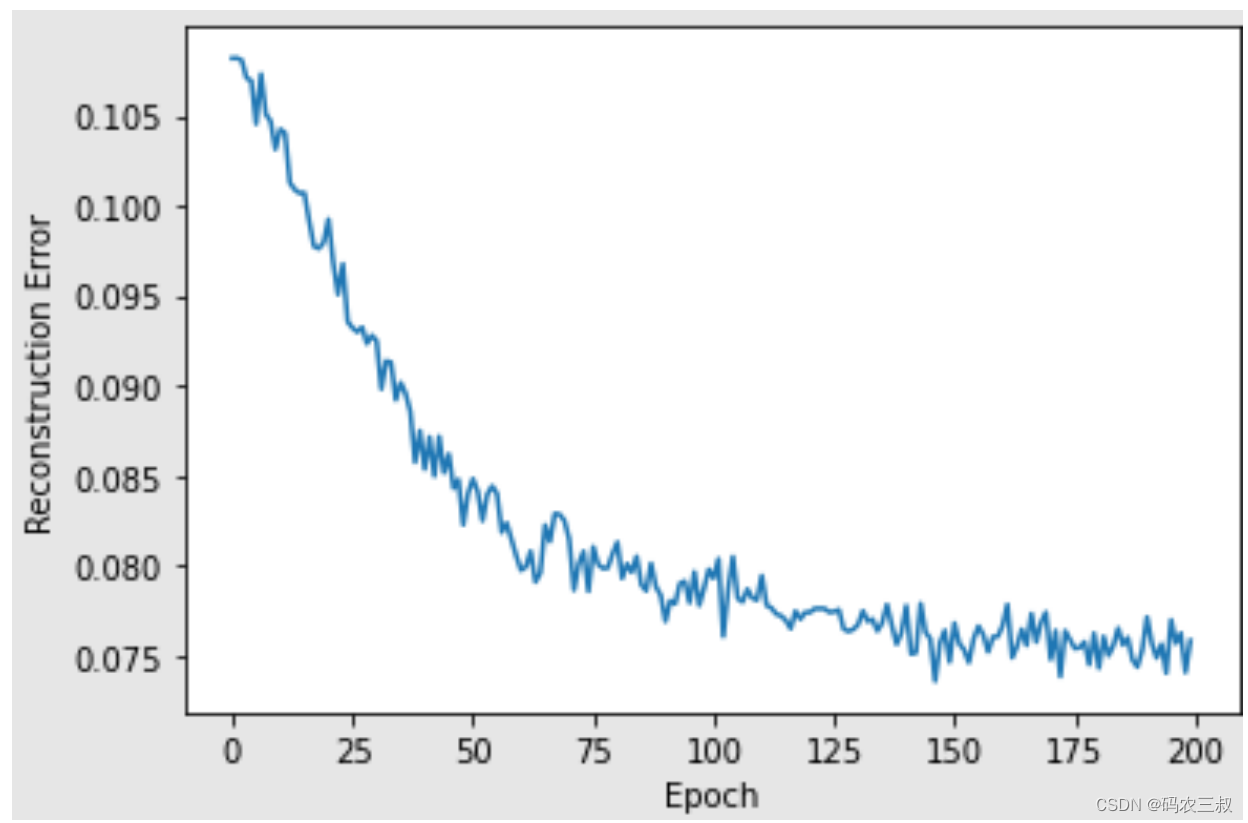
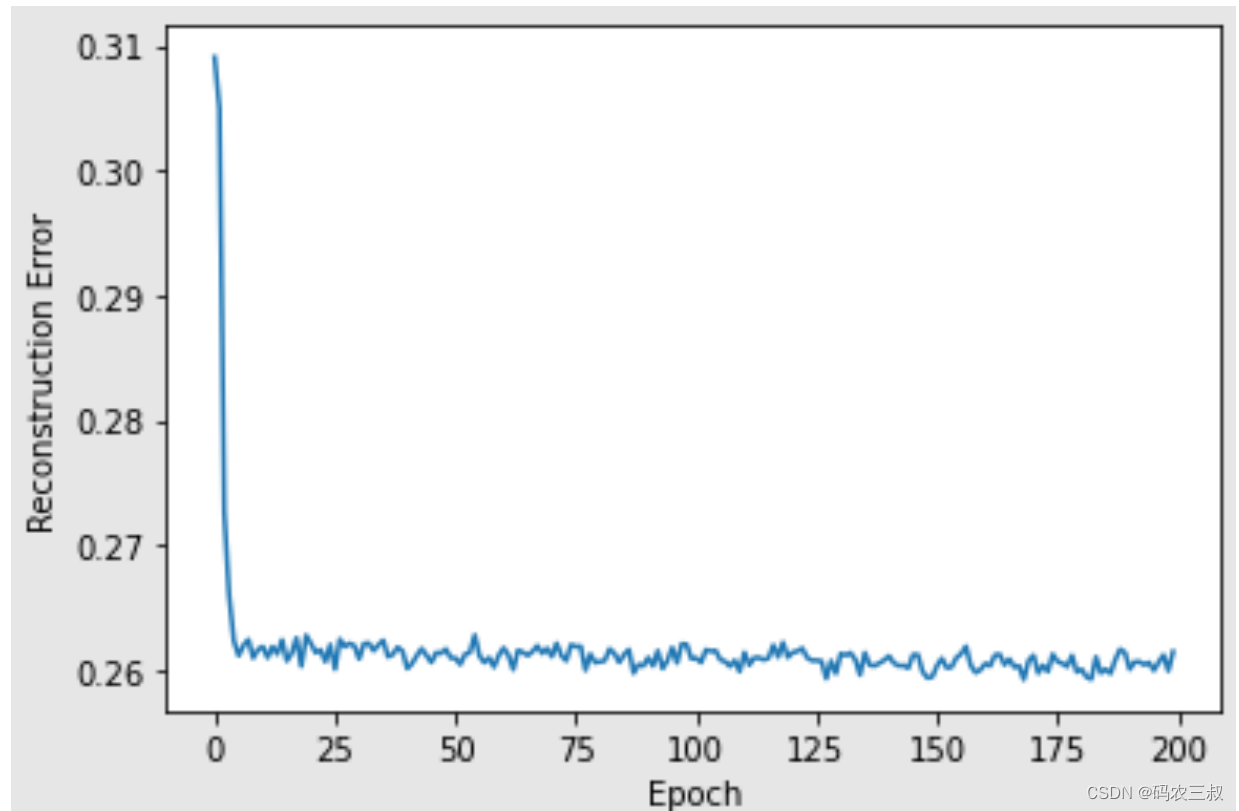
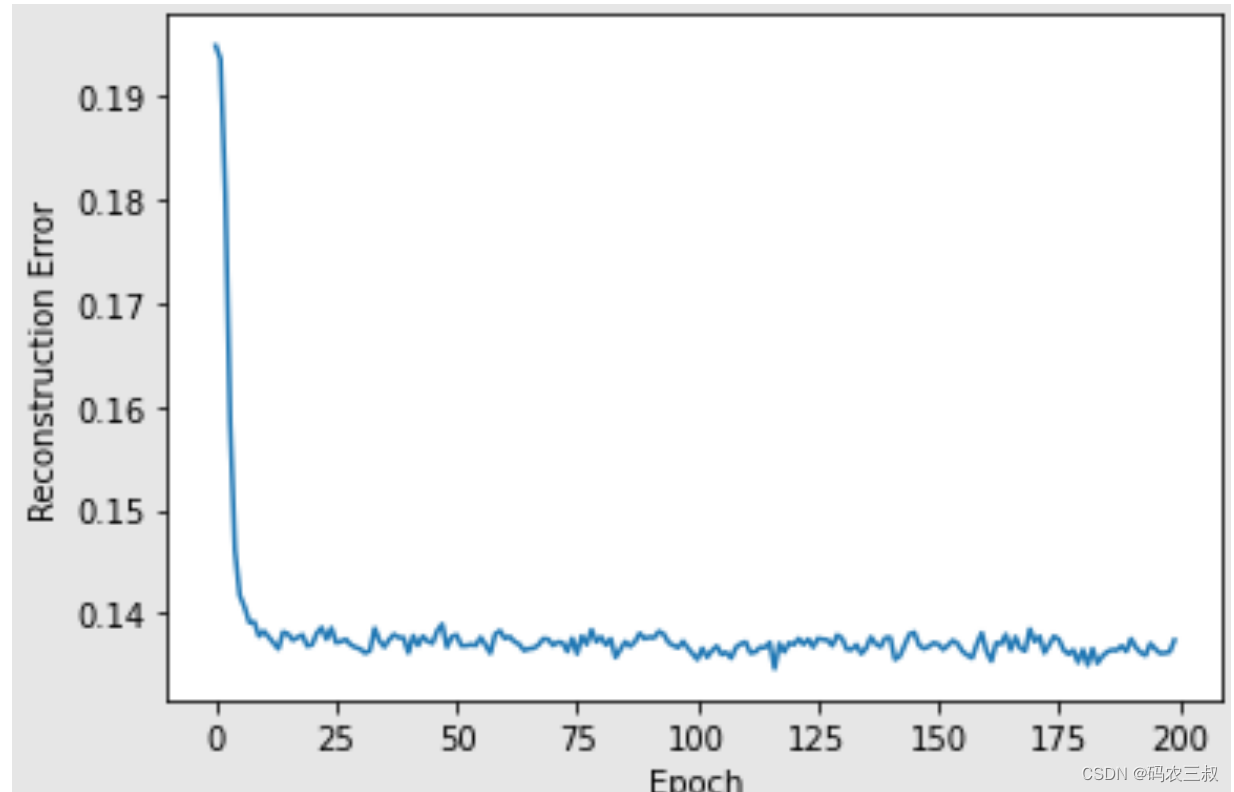
图10-7 可视化图
(6)开始实现LogisticRegression、GaussianNB 和 RandomForestClassifier 的集成功能,并创建函数f1score()查看这种方案的得分。代码如下:
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
lr = LogisticRegression(random_state=1)
lr.fit(X_New_Train, row_Y)
forest = RandomForestClassifier(n_estimators=50, random_state=1)
forest.fit(X_New_Train, row_Y)
gnb = GaussianNB()
gnb.fit(X_New_Train, row_Y)
def f1score( tn, fp, fn, tp):
precision = tp/(tp + fp)
print('Precision: ',precision)
recall = tp/(tp+fn)
print('Recall: ',recall)
return 2 * (precision * recall) / (precision + recall)
def f1score( tn, fp, fn, tp):
precision = tp/(tp + fp)
print('Precision: ',precision)
recall = tp/(tp+fn)
print('Recall: ',recall)
return 2 * (precision * recall) / (precision + recall)
tn, fp, fn, tp = confusion_matrix(train_Y, y_pred, labels=[0,1]).ravel()
print('F1-score: ',f1score(tn, fp, fn, tp))执行后会输出:
Precision: 0.561010804913244
Recall: 0.572023254144836
F1-score: 0.5664635121448497(7)分离数据帧,自定义编写函数根据分离的数据获取预测结果。代码如下:
bugzilla = pd.read_csv('/content/drive/My Drive/dataset/bugzilla.csv')
columba = pd.read_csv('/content/drive/My Drive/dataset/columba.csv')
jdt = pd.read_csv('/content/drive/My Drive/dataset/jdt.csv')
mozilla = pd.read_csv('/content/drive/My Drive/dataset/mozilla.csv')
platform = pd.read_csv('/content/drive/My Drive/dataset/platform.csv')
postgres = pd.read_csv('/content/drive/My Drive/dataset/postgres.csv')
def preds(mod, op):
y_preds = mod.predict(op)
y_preds = (y_preds > 0.5)*1
y_preds_final = np.array(y_preds)
return y_preds_final
def concatenate(list1, list2, list3, list4):
l = np.zeros(len(list1))
for i in range (0, len(list1)-1):
l[i] = (list1[i] + list2[i] + list3[i] + list4[i]) / 4
return l
def predict(op):
y_predict = concatenate(preds(ann, op), preds(lr, op), preds(forest, op), preds(gnb, op))
y_predict = (y_predict > 0.5)
return y_predict
def dbn_op(inputX):
for i in range(0, len(rbm_list)):
rbm = rbm_list[i]
outputX, reconstructedX, hiddenX = rbm.rbm_output(inputX)
inputX= hiddenX
return outputX
def dataframe_score(df1):
df1 = df1.drop(['commitdate','transactionid'], axis=1)
train_X_op = df1.iloc[:,:-1].apply(func=normalize, axis=0).astype(np.float32)
train_Y_op = df1.iloc[:,-1]
op = dbn_op(train_X_op)
y_pred_op = predict(op)
cm = confusion_matrix(train_Y_op, y_pred_op)
print(cm)
tn, fp, fn, tp = confusion_matrix(train_Y_op, y_pred_op, labels=[0,1]).ravel()
print('F1-score: ',f1score(tn, fp, fn, tp))
print('bugzilla:')
dataframe_score(bugzilla)
print('--------------------------------------------------------------------')
print('columba:')
dataframe_score(columba)
print('--------------------------------------------------------------------')
print('jdt:')
dataframe_score(jdt)
print('--------------------------------------------------------------------')
print('mozilla:')
dataframe_score(mozilla)
print('--------------------------------------------------------------------')
print('platform:')
dataframe_score(platform)
print('--------------------------------------------------------------------')
print('postgres:')
dataframe_score(postgres)
print('--------------------------------------------------------------------')
print('Overall:')
cm = confusion_matrix(train_Y, y_pred)
print(cm)
tn, fp, fn, tp = confusion_matrix(train_Y, y_pred, labels=[0,1]).ravel()
print('F1-score: ',f1score(tn, fp, fn, tp))执行后会输出:
bugzilla:
[[ 686 2238]
[ 224 1472]]
Precision: 0.3967654986522911
Recall: 0.8679245283018868
F1-score: 0.5445800961894193
--------------------------------------------------------------------
columba:
[[2071 1023]
[ 922 439]]
Precision: 0.3002735978112175
Recall: 0.32255694342395297
F1-score: 0.3110166489550124
--------------------------------------------------------------------
jdt:
[[21369 8928]
[ 2923 2166]]
Precision: 0.19524067063277448
Recall: 0.4256238946747888
F1-score: 0.2676883148983501
--------------------------------------------------------------------
mozilla:
[[36841 56285]
[ 1420 3729]]
Precision: 0.0621355017162662
Recall: 0.724218294814527
F1-score: 0.11445145251139449
--------------------------------------------------------------------
platform:
[[34859 19939]
[ 3870 5582]]
Precision: 0.21872183691861605
Recall: 0.590562843842573
F1-score: 0.31921768221199215
--------------------------------------------------------------------
postgres:
[[8623 6689]
[3118 2001]]
Precision: 0.23026467203682394
Recall: 0.39089665950380936
F1-score: 0.28981099283076256
--------------------------------------------------------------------
Overall:
[[22398 12473]
[11926 15940]]
Precision: 0.561010804913244
Recall: 0.572023254144836
F1-score: 0.5664635121448497
















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











