







Parallel and Non-parallel data, Disentanglement, and Prototype Editing
Text Style Transfer (TST) is an important task in natural language generation, which aims to control certain attributes in the generated text, such as politeness, emotion, humor, and many others while preserving the content. It has a long history in the field of Natural Language Processing and recently has re-gained significant attention thanks to the rise of deep neural models.
I suggest reading the paper Deep Learning for Text Style Transfer: A Survey for a more in-depth explanation.
Applications
- Intelligent Bots for which users prefer distinct and consistent persona (e.g., empathetic and informal) instead of emotionless or inconsistent persona.
- Development of intelligent writing assistants that help to polish writings to better fit their purpose, e.g., more professional, polite, objective, humorous, or other advanced writing requirements.
- Automatic text simplification, i.e. from complex to simple text.
- Debiasing online text, i.e. from biased to objective text.
- Fighting against offensive language, i.e. from offensive to non-offensive text
Parallel corpora vs non-parallel corpora
Text Style Transfer algorithms can be developed in a supervised way with parallel corpora, i.e. text that comes twice with the same content but with different styles, and in an unsupervised way with non-parallel corpora.
Here is a list of common TST subtasks with corresponding datasets.
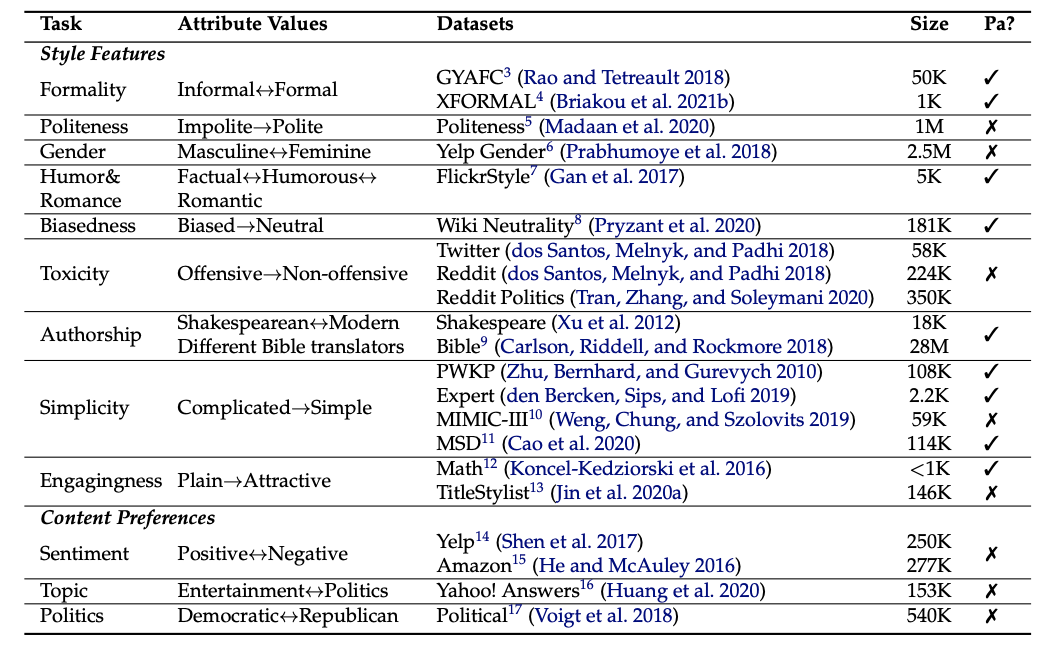
List of common subtasks of TST with corresponding datasets. Image from the paper “Deep Learning for Text Style Transfer: A Survey”.
The size of the datasets corresponds to the number of sentences contained. The last column indicates whether the dataset is parallel or non-parallel.
Methods on parallel data
Most supervised methods adopt the standard neural sequence-to-sequence (seq2seq) model with the encoder-decoder architecture, the same commonly used for neural machine translation and text generation tasks such as summarization. The encoder-decoder seq2seq model can be implemented by either LSTM or Transformer.
Methods on non-parallel data
There are mainly three types of unsupervised approaches for non-parallel data:
- Disentanglement: disentangle text into its content and attribute in the embeddings latent space, and then apply generative modeling.
- Prototype Editing: works by deleting only the parts of the sentences with the wrong attributes (e.g. formal in place of informal) and replacing them with words with the correct attributes, making sure that the resulting text is still fluent.
- Pseudo-parallel Corpus Construction: used to train the model as if in a supervised way with pseudo-parallel data. One way to construct pseudo-parallel data is through retrieval, namely extracting aligned sentence pairs from two mono-style corpora.
How to evaluate
A successful style-transferred output not only needs to demonstrate the correct target style, but also, due to the uncontrollability of neural networks, we need to verify that it preserves the original semantics, and maintains natural language fluency.
Therefore, the commonly used practice of evaluation considers the following three criteria:
- Transferred style strength.
- Semantic preservation, i.e. maintains the same meaning.
- Fluency.
As it’s not always easy to compute automatically these metrics, both automatic evaluation and human evaluation are commonly employed.
Thank you for reading! If you are interested in learning more about NLP, remember to follow NLPlanet on Medium, LinkedIn, and Twitter!















 991
991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









