






weak supervised objection detection/localization的方法主要可以分成以下三大类(个人理解):
- 以WSDDN为代表的一类
- 以CAM为代表类激活图的方法
- 最近出现的基于point annotation的方法
前面两种方法都是只通过image-level的标注来进行目标检测,而最后一种方法是通过point annotation来进行检测(即会给出每个object中的一个点的坐标以及这个object的类别)
1.WSDDN类
1.1 Weakly Supervised Deep Detection Networks
来源:CVPR2016
这篇文章可以说是WSDDN这一类的开山之作
motivate:
这篇文章的motivate是预训练好的cnn可以在其他的任务上进行泛化,因此作者使用了在图像分类任务上预训练好的CNN网络并对其进行一些改动。
主要方法:
WSDDN的流程如下图所示

作者采用在图像分类任务上预训练好的网络(如VGG),并将该网络中最后一个卷积块中的relu之后的pooling层替换为SPP层,同时对原图利用SSW或者EB的算法进行region proposals,将这些region proposals送入到SPP中,将这些的特征融合并将其池化至同一尺寸。然后经过两个全连接层fc6和fc7,从fc7出来之后,将分为两个数据流。
分类数据流:
这一部分会对之前生成的region proposals进行分类,以确定每一个region proposals的类别。通过fc8,我们得到了
x
c
x^c
xc,这是一个C*R的矩阵,C表示所以物体的类别,R是region proposals的数量。然后用下面的公式对其进行归一化
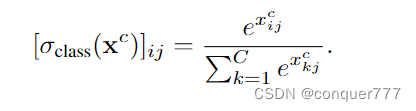
这个分支预测哪个类与一个区域相关联
检测数据流:
同样的,从fc7出来,经过fc8,得到
x
d
x^d
xd,这是一个C*R的矩阵,C表示所以物体的类别,R是region proposals的数量。然后用下面的公式对其进行归一化
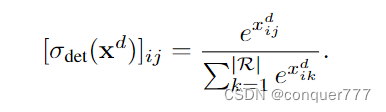
注意这两次归一化是沿不同维度进行的,分类时,我们是对同一个框的不同类别进行归一化,检测时候,我们是对同一个类别的不同框进行归一化。因此,第一个分支预测哪个类与一个区域相关联,而第二个分支选择哪些区域更可能包含一个信息图像片段。
之后通过Hadamard的方法(矩阵对应元素相乘)得到region-level的score
x
R
x^R
xR,通过下面的式子,就可以计算出image-level的类别得分

其实就是将所有框的类别得分加起来,我们得到图像的类别得分 σ_class, 检测得分σ_det, 以及整幅图像得分
y
c
y_c
yc
感觉论文当中没有明确说框是怎么来的,我的理解是从
y
c
y_c
yc中我们可以知道这幅图是哪个类别的概率最高,然后再找出该类别中得分最高的框作为其预测框(如有错误,欢迎指正)
Loss
因为没有对框的标注,也没法调整框,因此Loss只有一个分类loss,
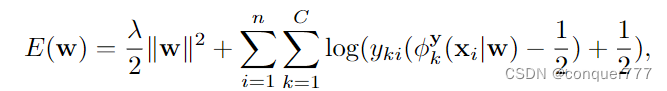
y
k
i
y_{ki}
yki为图像的类别标签属于{-1, 1},当包含目标类时为1,不包含时为-1;w为网络权重,等式右边前半部分为正则项。
1.2 Multiple Instance Detection Network with Online Instance Classifier Refinement
来源:CVPR2018
这篇文章是对上面一篇文章的改进
主要方法
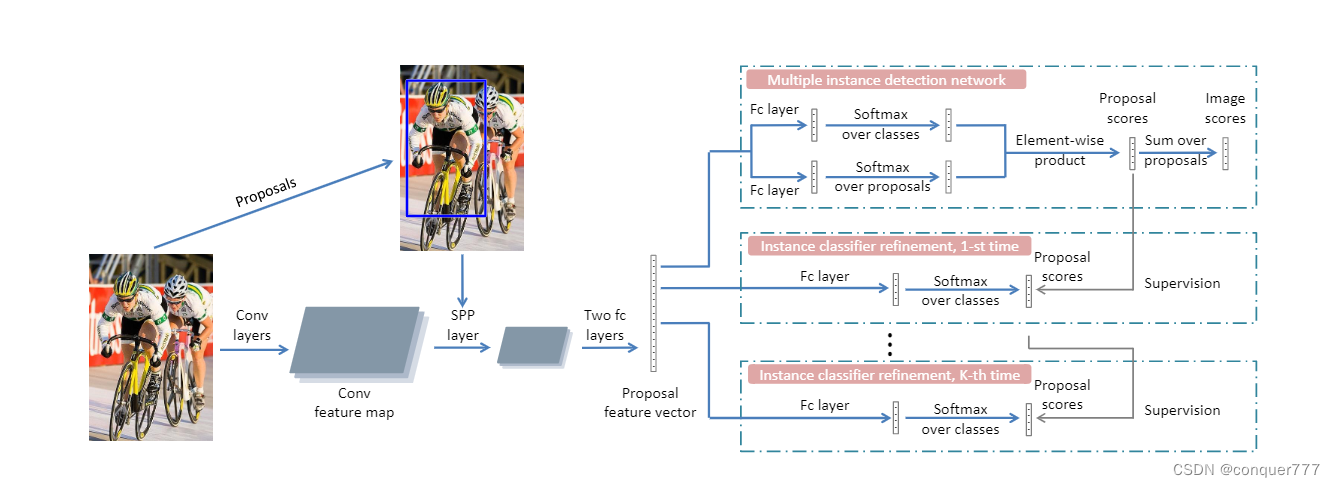
整个流程图的前半部分和WSDDN是一样的,在拿到
x
R
x^R
xR之后,我们要对instance classficer 进行refine
1.3 Weakly Supervised Region Proposal Network and Object Detection
来源:ECCV2018
这篇文章也是对第一篇文章的一个改进,主要是对前面region proposal部分做了改进
主要方法
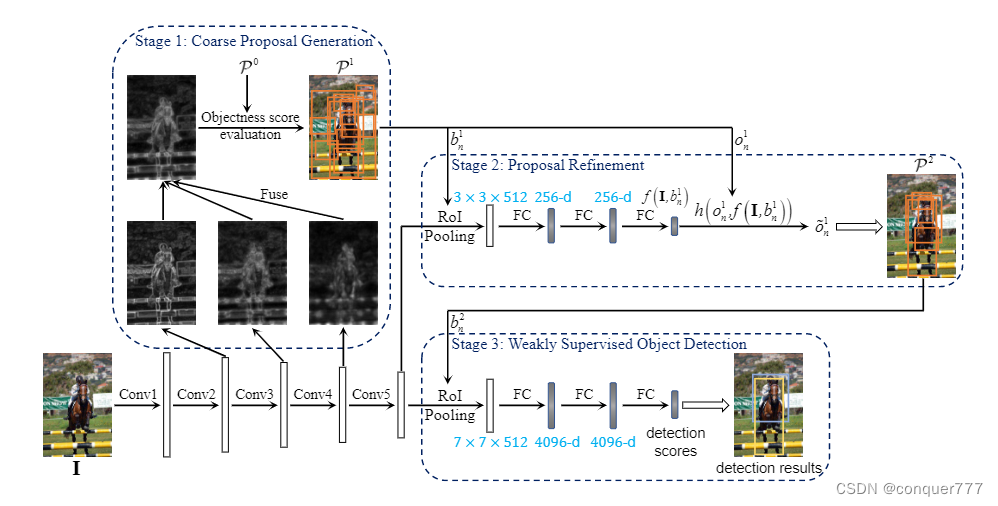
输入一张图片,我们首先可以用EB的方法来生成最开始的region proposal
P
0
P^0
P0,将图片输入到卷积神经网络中,将conv中间的feature map取出来,在channel这个维度上做平均后resize到原尺寸,然后用resize后的图,对生成的region proposal
P
0
P^0
P0进行评估,在其中选取部分得分高的组成
P
1
P^1
P1.
将
P
1
P^1
P1的bbox拿出来,和conv5后的feature map经过ROI Pooling融合在一起,经过几个全连接层后,会得到关于这几个bbox的新的评分,与原来的评分直接相乘,然后再通过评分选出一部分作为
P
2
P^2
P2.
再将 P 2 P^2 P2通过RoI Pooling和conv5后的feature map相融合,再经过几个FC得到最后的detection scores
2.CAM类
2.1 Learning Deep Features for Discriminative Localization
来源:CVPR2016
motivate
这篇文章其实也算是神经网络可解释性的一篇工作。在图像分类中,我们可以通过分析出神经网络通过关注了哪些部分,来完成最终的分类,那这个被神经网络关注的部分,就可以用于Localization。
method
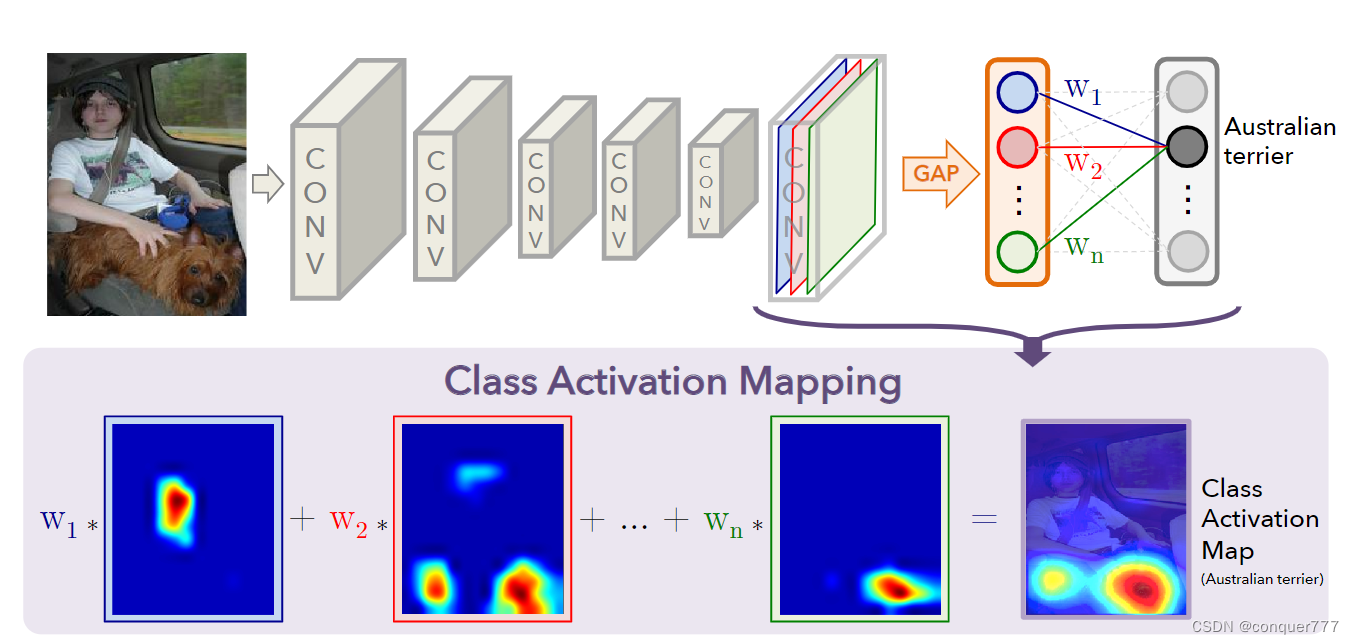
输入原始图像,经过几层conv,得到14x14x512的feature map,其实这512个channel对应了神经网络提取出的不同特征,w权重反应了该特征对某一个类别的重要成都,然后对每一个channel求一个均值,然后再乘以对应的权重,再经过softmax就会得到分类的分数。
而对于定位任务来说,首先要通过下面的式子算出Mc
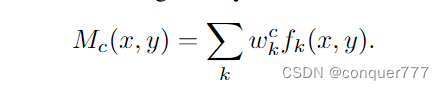
这里面
f
k
(
x
,
y
)
f_k(x,y)
fk(x,y)表示的是第k个channel在(x,y)处的值,所以
f
k
(
x
,
y
)
f_k(x,y)
fk(x,y)是一个矩阵,w是权重,Mc(x,y)直接表明了在空间网格(x, y)处激活的重要性,从而导致了图像分类的结果,再通过双线性插值的方法将Mc还原到原尺寸大小,然后再画出来就得到了CAM图。根据CAM图就可以画出检测框。
3.Point annotation类
相比于之前仅有image-level的标注,这类方法利用了点标注信息,也即在每一个要检测的物体上,都有一个点的标注信息,包含了该点的坐标和该点所属物体的类别。
3.1 Point DETR
本文针对只有point annotation的检测提出了一个三步走的框架:
- 首先训练一个通过point annotation生成检测框和类别的模型,在训练时可以用少量完整标注的数据集进行监督,这个模型被称为教师模型
- 利用教师模型,对只有点标注的数据生成伪检测框
- 利用全标记的数据和伪检测框进行监督学习,相当于是一个正常的目标检测任务了,训练出一个学生模型
method
首先第一步是训练教师模型,也就是通过下图所示的方法
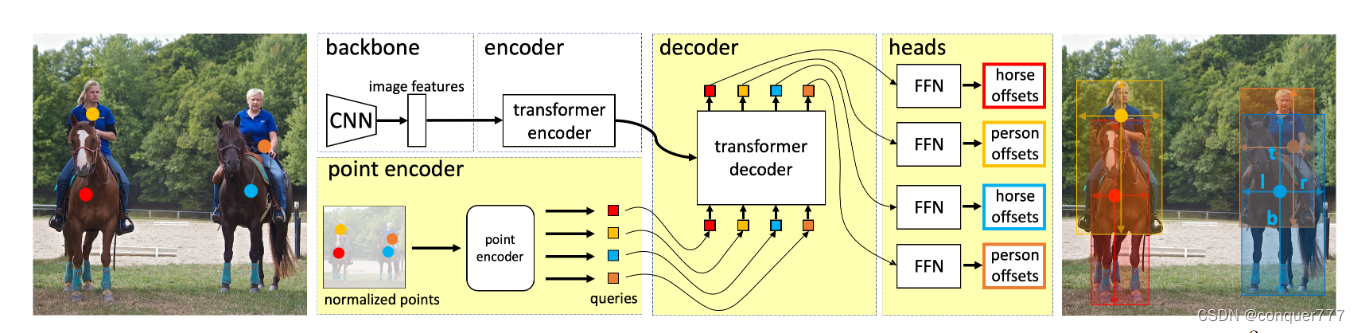
作者基本上延续了DETR的方法,但是decoder处的object query不是由postition embedding学习来的,而是由point annotations经过point encoder得到的。
point encoder
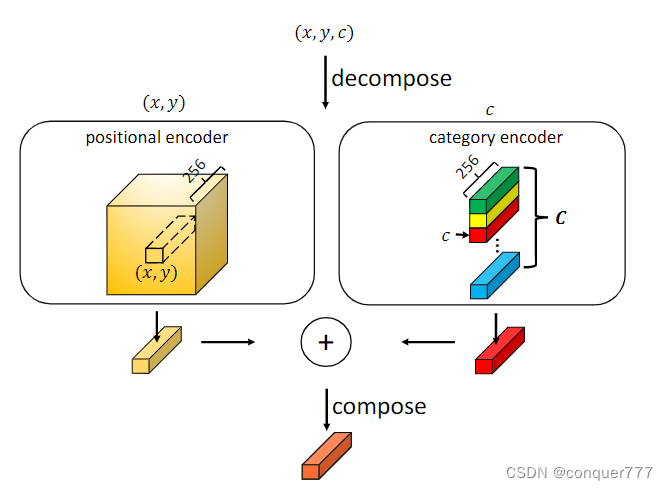
point encoder的结构如上图所示,一个point annotation首先被分为坐标位置和类别,然后分别经过postitional encoder和category encoder。postitional encoder其实就是二维的位置编码,而category encoder通过学习得到的,然后将postitional encoder和category encoder相加就得到了object query。
除了object query的生成方式不一样,其他和DETR几乎完全相同,这里因为我们已经知道了类别信息,所以只用从点预测出框即可,这样就训练好了教师模型。
有了教师模型之后,就可以通过教师模型生成伪检测框,继而训练出学生模型,这里的学生模型是用的FCOS。
3.2 Group RCNN
method
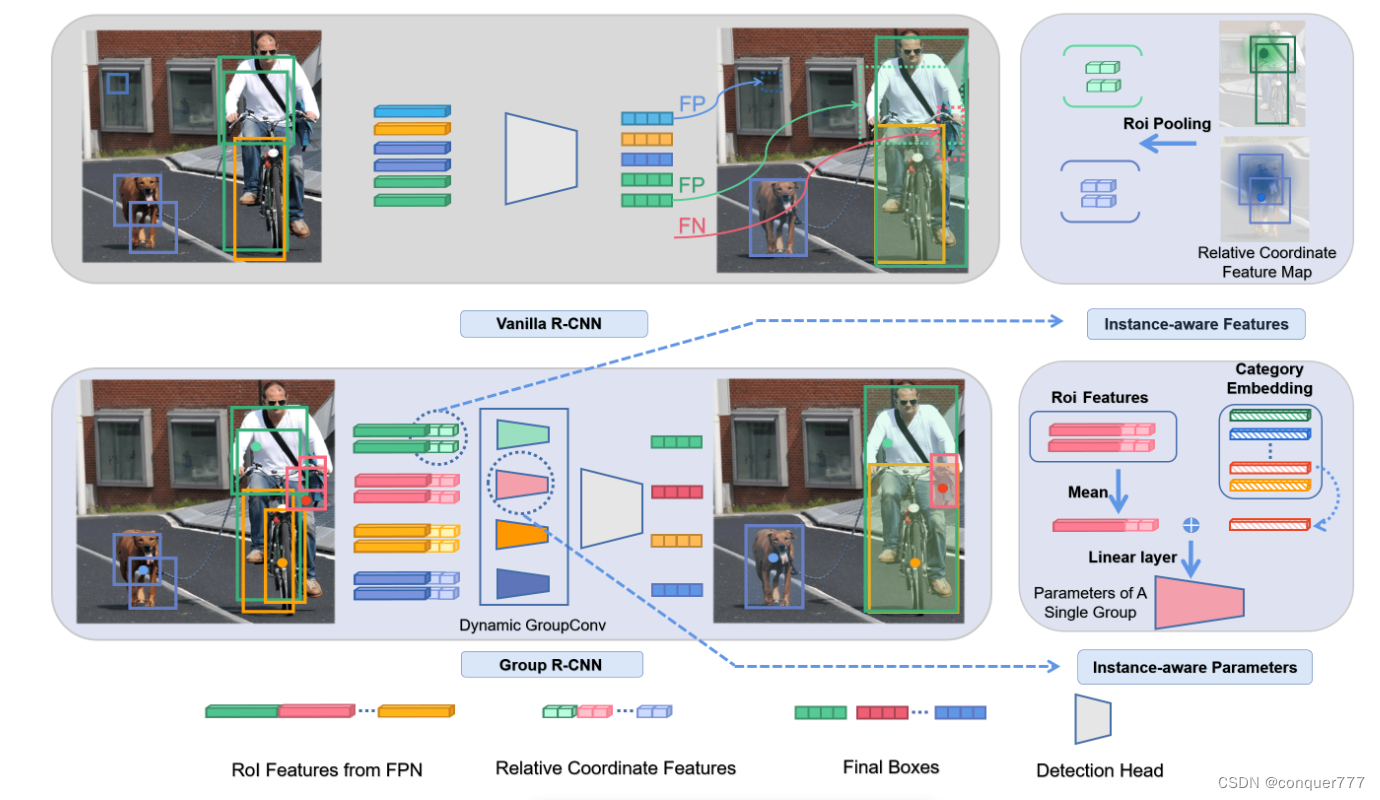
这篇文章和point detr遵循同样的方法,也是先训练出一个由点标注生成框标注的模型,后面通过这个模型生成伪标注,然后再利用伪标注和部分全标注来训练检测模型。
Group RCNN首先需要生成proposals,其做法是这样的:将标注点投影到FPN的每一层feature map中,同时在每个投影点附近的feature map上选取k个点,这样共有km个点,每个点生成n个anchor,共nkm个anchor,也即nkm个propsals.这样的生成方法是的proposals的召回率非常高。
接下来就是将生成的proposal经过refine,使其和检测框能一一对应。传统的正负样本匹配策略是:只要 proposal 与任意 GT 框的 IOU 大于一定的阈值,那就是正样本。所以一个实例组的 proposal 可能匹配到其他的实例,最后可能导致两个 Instance Group 经过 refine head 会存在同一实例的高分框。在同类拥挤的情况下,最后很容易导致多个 Instance Group 选择出来同一实例的框。而在较为拥挤的 COCO 数据集中,同类拥挤的现象是十分常见的。
所以作者想到实现 Instance 级别的正负样本匹配,即每个 Group 内的框只有与对应实例的 IOU 大于特定阈值,才会被认为是正样本。但是这样的效果反而不好,因为 CNN 具有等变性, 不同的 Instance Group 的 proposal 共享了相同的 FPN feature map 与 head 参数,这样不同 group 中较为相似的 proposal 会有较为相似的回归输出与分数,但是在 instance 级别的 assign 策略下可能会有完全相反的 assign 结果,所以作者又提出了下面的解决方案
Instance-aware Feature Enhancement
这里利用了一个先验,即靠近点注释的proposal应该有更高的机会被分配给该实例。具体的做法是:在每个 group 的 proposal 做 RoI Pooling 前,我们以这个实例的点标注为原点为其特征增加相对位置编码,这个每个group proposal的feature就是不同的了,然后再做ROI pooling。
Instance-aware Parameter Generation
对每一个group的roi feature取mean,然后与类别的embeding进行concat,然后再将其输入到检测头中得到最后的检测结果















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









