







DAMO yolo在提出前阿里就推出了一个叫GIRAFFEDET的模型,主推轻backbone重neck的网络结构,使得网络更关注于高分辨率特征图中空间信息和低分辨率特征图中语义信息的信息交互。同时这个设计范式允许检测网络在网络早期阶段就以相同优先级处理高层语义信息和低层空间信息,使其在检测任务上更加有效。
感兴趣的可以看一下GIRAFFEDET的原文:
不过这里主要讲的不是 GiraffeDet,而是将这一思想应用在yolov5中。
先看一下DAMO yolo中Giraffe Neck的结构:
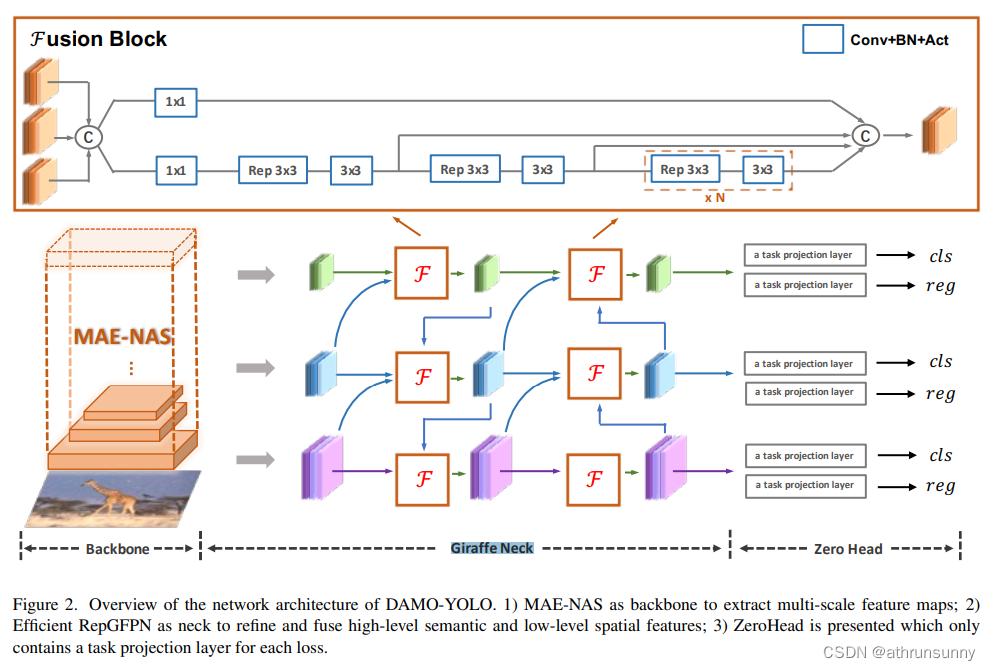
上重点:
在yolov5的工程中的models文件夹创建yolov5s-GFPN.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# DAMO-YOLO GFPN Head
head:
[[-1, 1, Conv, [512, 1, 1]], # 10
[6, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]],
[-1, 3, CSPStage, [512]], # 13
[-1, 1, nn.Upsample, [None, 2, 'nearest']], #14
[4, 1, Conv, [256, 3, 2]], # 15
[[14, -1, 6], 1, Concat, [1]],
[-1, 3, CSPStage, [512]], # 17
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]],
[-1, 3, CSPStage, [256]], # 20
[-1, 1, Conv, [256, 3, 2]],
[[-1, 17], 1, Concat, [1]],
[-1, 3, CSPStage, [512]], # 23
[17, 1, Conv, [256, 3, 2]], # 24
[23, 1, Conv, [256, 3, 2]], # 25
[[13, 24, -1], 1, Concat, [1]],
[-1, 3, CSPStage, [1024]], # 27
[[20, 23, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]在common.py中添加如下代码:
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
'''Basic cell for rep-style block, including conv and bn'''
result = nn.Sequential()
result.add_module(
'conv',
nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepConv(nn.Module):
'''RepConv is a basic rep-style block, including training and deploy status
Code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
'''
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
padding=1,
dilation=1,
groups=1,
padding_mode='zeros',
deploy=False,
act='relu',
norm=None):
super(RepConv, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
self.out_channels = out_channels
assert kernel_size == 3
assert padding == 1
padding_11 = padding - kernel_size // 2
if isinstance(act, str):
self.nonlinearity = get_activation(act)
else:
self.nonlinearity = act
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=True,
padding_mode=padding_mode)
else:
self.rbr_identity = None
self.rbr_dense = conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=stride,
padding=padding_11,
groups=groups)
def forward(self, inputs):
'''Forward process'''
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(
self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(
kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3),
dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(
branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(
in_channels=self.rbr_dense.conv.in_channels,
out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size,
stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding,
dilation=self.rbr_dense.conv.dilation,
groups=self.rbr_dense.conv.groups,
bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
class Swish(nn.Module):
def __init__(self, inplace=True):
super(Swish, self).__init__()
self.inplace = inplace
def forward(self, x):
if self.inplace:
x.mul_(F.sigmoid(x))
return x
else:
return x * F.sigmoid(x)
def get_activation(name='silu', inplace=True):
if name is None:
return nn.Identity()
if isinstance(name, str):
if name == 'silu':
module = nn.SiLU(inplace=inplace)
elif name == 'relu':
module = nn.ReLU(inplace=inplace)
elif name == 'lrelu':
module = nn.LeakyReLU(0.1, inplace=inplace)
elif name == 'swish':
module = Swish(inplace=inplace)
elif name == 'hardsigmoid':
module = nn.Hardsigmoid(inplace=inplace)
elif name == 'identity':
module = nn.Identity()
else:
raise AttributeError('Unsupported act type: {}'.format(name))
return module
elif isinstance(name, nn.Module):
return name
else:
raise AttributeError('Unsupported act type: {}'.format(name))
def get_norm(name, out_channels, inplace=True):
if name == 'bn':
module = nn.BatchNorm2d(out_channels)
else:
raise NotImplementedError
return module
class ConvBNAct(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block"""
def __init__(
self,
in_channels,
out_channels,
ksize,
stride=1,
groups=1,
bias=False,
act='silu',
norm='bn',
reparam=False,
):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
if norm is not None:
self.bn = get_norm(norm, out_channels, inplace=True)
if act is not None:
self.act = get_activation(act, inplace=True)
self.with_norm = norm is not None
self.with_act = act is not None
def forward(self, x):
x = self.conv(x)
if self.with_norm:
x = self.bn(x)
if self.with_act:
x = self.act(x)
return x
def fuseforward(self, x):
return self.act(self.conv(x))
class BasicBlock_3x3_Reverse(nn.Module):
def __init__(self,
ch_in,
ch_hidden_ratio,
ch_out,
act='relu',
shortcut=True):
super(BasicBlock_3x3_Reverse, self).__init__()
assert ch_in == ch_out
ch_hidden = int(ch_in * ch_hidden_ratio)
self.conv1 = ConvBNAct(ch_hidden, ch_out, 3, stride=1, act=act)
self.conv2 = RepConv(ch_in, ch_hidden, 3, stride=1, act=act)
self.shortcut = shortcut
def forward(self, x):
y = self.conv2(x)
y = self.conv1(y)
if self.shortcut:
return x + y
else:
return y
class SPP(nn.Module):
def __init__(
self,
ch_in,
ch_out,
k,
pool_size,
act='swish',
):
super(SPP, self).__init__()
self.pool = []
for i, size in enumerate(pool_size):
pool = nn.MaxPool2d(kernel_size=size,
stride=1,
padding=size // 2,
ceil_mode=False)
self.add_module('pool{}'.format(i), pool)
self.pool.append(pool)
self.conv = ConvBNAct(ch_in, ch_out, k, act=act)
def forward(self, x):
outs = [x]
for pool in self.pool:
outs.append(pool(x))
y = torch.cat(outs, axis=1)
y = self.conv(y)
return y
class CSPStage(nn.Module):
def __init__(self,
ch_in,
ch_out,
n,
block_fn='BasicBlock_3x3_Reverse',
ch_hidden_ratio=1.0,
act='silu',
spp=False):
super(CSPStage, self).__init__()
split_ratio = 2
ch_first = int(ch_out // split_ratio)
ch_mid = int(ch_out - ch_first)
self.conv1 = ConvBNAct(ch_in, ch_first, 1, act=act)
self.conv2 = ConvBNAct(ch_in, ch_mid, 1, act=act)
self.convs = nn.Sequential()
next_ch_in = ch_mid
for i in range(n):
if block_fn == 'BasicBlock_3x3_Reverse':
self.convs.add_module(
str(i),
BasicBlock_3x3_Reverse(next_ch_in,
ch_hidden_ratio,
ch_mid,
act=act,
shortcut=True))
else:
raise NotImplementedError
if i == (n - 1) // 2 and spp:
self.convs.add_module(
'spp', SPP(ch_mid * 4, ch_mid, 1, [5, 9, 13], act=act))
next_ch_in = ch_mid
self.conv3 = ConvBNAct(ch_mid * n + ch_first, ch_out, 1, act=act)
def forward(self, x):
y1 = self.conv1(x)
y2 = self.conv2(x)
mid_out = [y1]
for conv in self.convs:
y2 = conv(y2)
mid_out.append(y2)
y = torch.cat(mid_out, axis=1)
y = self.conv3(y)
return y同时在yolo.py中的parse_model函数中添加:
if m in (Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, CSPStage):
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost, C3x, CSPStage]:
args.insert(2, n) # number of repeats
n = 1在yolo.py中找到 BaseModel()在其中的fuse函数中添加:
if isinstance(m, RepConv):
# print(f" fuse_repvgg_block")
m.switch_to_deploy()以上步骤即完成模块的添加。
在conda环境中执行如下指令即可开始训练:
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5s-GFPN.yaml --batch-size 32















 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











