






简介
本推文主要介绍了来自新加坡国立大学的Peng Qi、Zehong Yan、Wynne Hsu等共同提出的一种多模态大语言模型,用于判断新闻中的图像是否被错误利用。他们在论文《SNIFFER: Multimodal Large Language Model for ExplainableOut-of-Context Misinformation Detection》中提出了SNIFFER框架,通过两阶段指令调优和外部知识增强,显著提升了模型在跨模态虚假信息检测中的准确性和解释性。实验结果表明,SNIFFER在检测性能上超越了当前现有方法,并能够提供精确且有说服力的解释。
论文链接:https://arxiv.org/abs/2403.03170
代码链接:https://github.com/MischaQI/Sniffer
推文作者为韩煦,审校为邓镝和黄星宇。
一、研究背景
近年来,随着生成式人工智能技术的发展,假新闻的传播造成了极大的危害。例如GPT系列模型等大规模语言模型,快速生成看似真实且语言流畅的虚假新闻内容;生成对抗网络(GAN)可以制造虚假的新闻图片,如自然灾害、战争场景等。这些技术依赖于深度学习和生成模型,能够自动生成逼真的虚假内容,但通常需要较高的技术水平。相比之下,一些低成本但高效的手段正成为虚假新闻的主要来源,这类方法以低成本但高效的方式制造虚假新闻:将真实图片或视频放置在不相关或错误的新闻背景中。这种形式的虚假信息也被称为“脱离上下文”(OOC)。这种形式的虚假信息广泛存在于社交媒体和新闻报道中,它利用了图像的直观性和真实性,使传统检测方法难以有效识别。
现有的检测方法主要集中在图像与文本的一致性评估,但往往缺乏提供清晰解释的能力,难以有效地揭示虚假信息的来源和逻辑(如图1中的InstructBLIP与GPT-4V),为此,研究团队提出了新模型SNIFFER,以解决这一问题。

图1 SNIFFER检测不实信息示例
二、研究方法
2.1 两阶段微调
SNIFFER模型通过两个阶段的指令调优来适应新闻领域和图文不一致假新闻检测任务。第一阶段为了新闻领域对齐,第二阶段为任务特定调优。
该团队观察到InstructBLIP倾向于使用粗粒度的名词(例如“人”,“女人”和“男人”)而不是细粒度的、特定的名称,如“唐纳德·特朗普”。考虑到不同领域在词汇使用上的差异,该团队构建了一个专门面向新闻领域的指令数据集,以优化通用领域的InstructBLIP模型,使其更适应新闻任务。该指令数据集由NewsCLIPpings数据集精心策划而成,包含368,013个独特的新闻图像-字幕配对,涵盖了多样化且具有代表性的新闻领域概念。然后,论文又进行了一次微调。主要挑战在于缺乏包含解释的监督数据。对于由cap1和img2组成的样本,通过调用ChatGPT分析cap1和img2所对应的cap2中的多处不一致,并从中挑选出最可能体现在图片上的一处不一致作为真实标注,然后将其填入设定的模板中,生成解释。在这一过程中,主要关注三个关键信息点:图文不一致的实体类型(如人物、地点、事件等),以及在cap1和img2中呈现的具体实体名称。
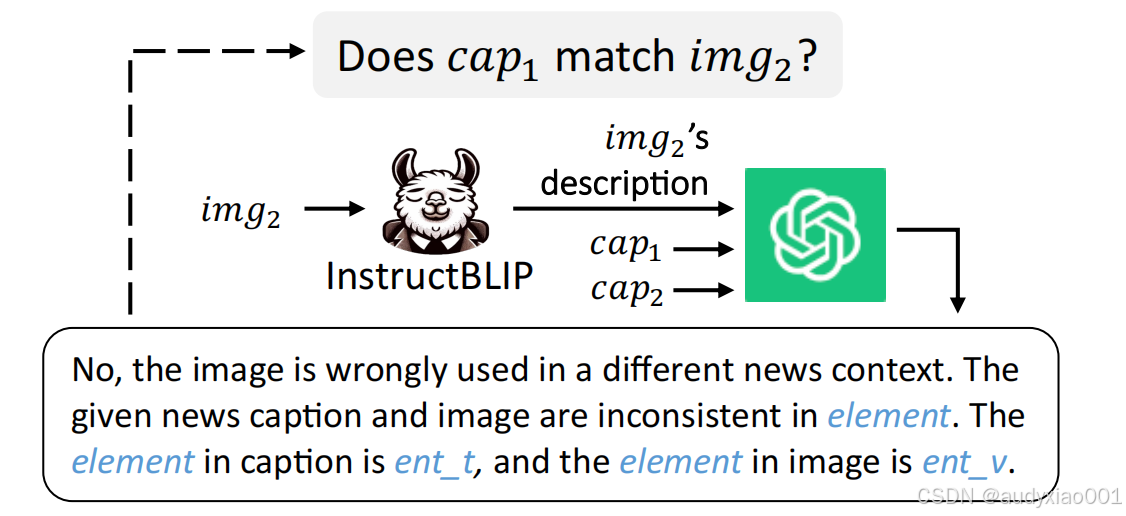
图2 第二阶段的微调过程
在第一阶段,模型通过图像字幕数据来细化对通用对象与新闻领域实体的概念对齐。这个过程使用了37万个样本进行训练,目的是让模型更好地理解和处理新闻领域的语言和视觉信息。第二阶段,模型在OOC检测任务上进行训练,使用了7.1万个样本进行10个周期的训练。这个阶段的目的是让模型专门识别和解释OOC假新闻。通过这两步训练,实现了大模型从通用到新闻领域的转换。

图3 模型训练细节
2.2 内外检查机制
在该研究中,推理过程是假新闻检测的核心步骤。SNIFFER框架通过两种验证方法:内部检查和外部验证结合生成最终的检测结果与解释。以下是推理过程的详细描述:
1.内部一致性检查(蓝色线条):SNIFFER对图像和文本之间的跨模态一致性进行全面检查。在这一过程中,通过深度分析图像和文本的内容,识别它们在关键元素上的不一致之处。借助指令调优后的模型训练,SNIFFER能够精准地捕捉文本与图像之间的细微差异,从而判断是否存在虚假信息的迹象。
2.外部验证(橙色线条):通过调用外部工具对图片进行逆向检索获取其原始上下文作为“证据”,利用大模型再将它与当前文本进行比较,得到外部决策。
3.最终判断(黑色线条):结合前两步的推理结果,产生最终判断及解释。
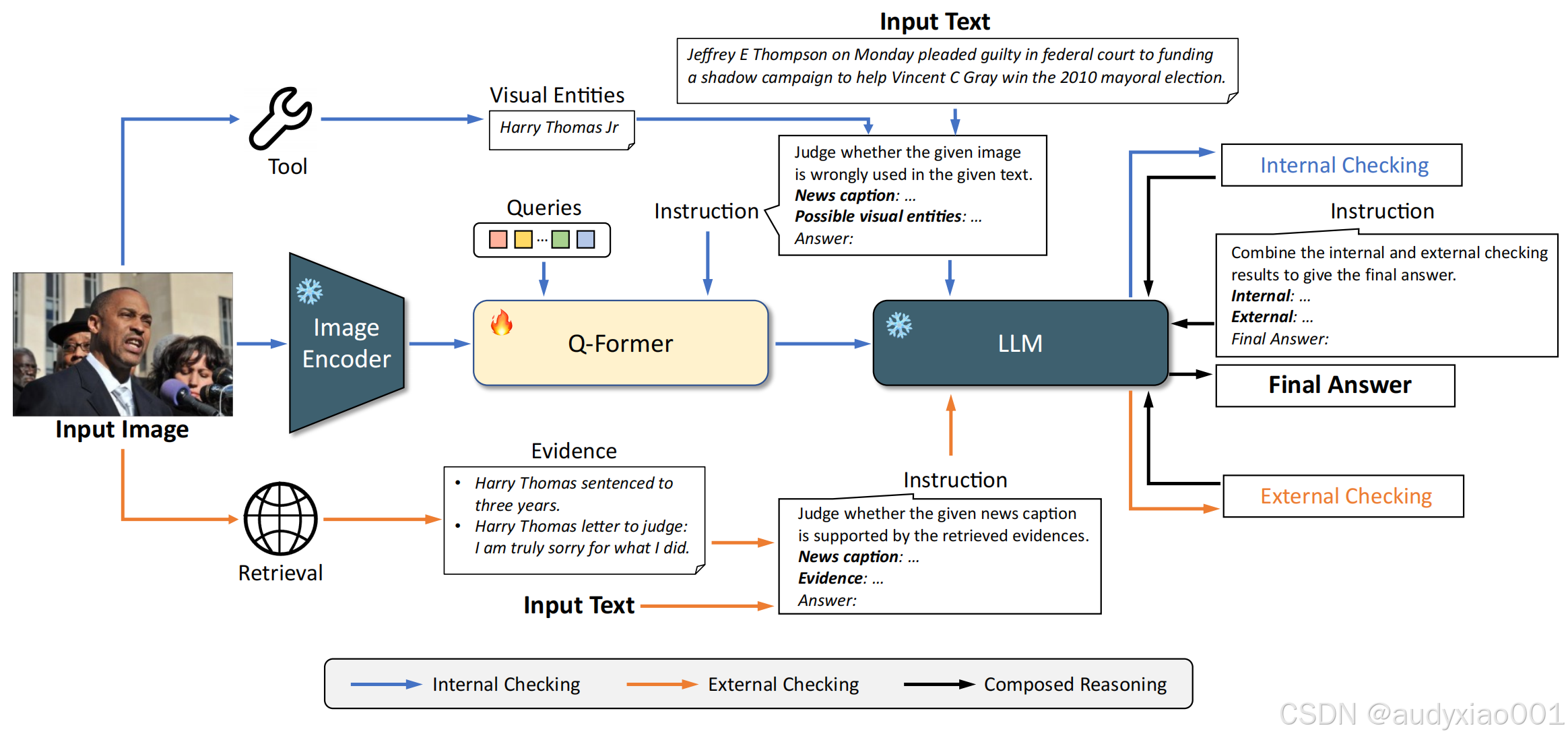
图4 SNIFFER推理框架
三、实验结果
3.1 性能比较
SNIFFER在所有基线方法中表现最佳,验证了其有效检测上下文虚假信息样本的能力。即使只考虑部分文本证据,SNIFFER仍优于CCN超过3.7%,表1证明了SNIFFER与其他baseline方法相比的优越性。
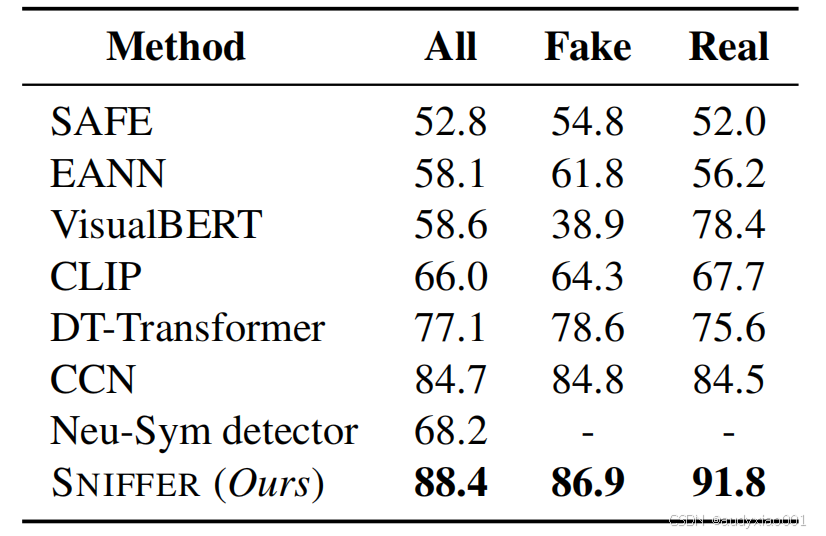
表1 对比试验
论文通过消融实验分析了SNIFFER中每个组件的重要性。如表2所示,所有组件对实现最佳性能都至关重要,特别是任务特定调优显著提高了模型的性能

表2 消融实验
此外,如表3所示,与GPT-4V相比,SNIFFER在分类准确性上高出11%。这表明在特定任务中,相对较小的模型完全有能力超越通用的大型模型。
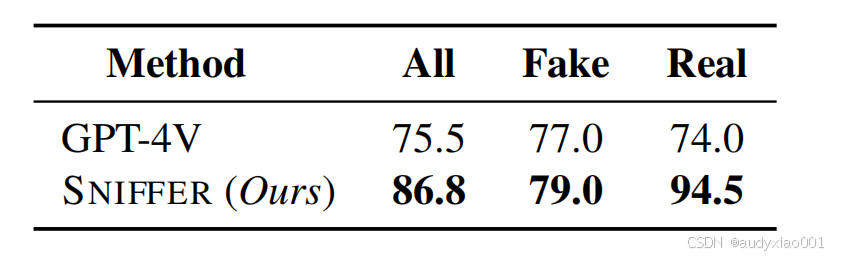
表3 分类准确率对比
3.2 解释准确性
准确性上,论文主要关注三个信息点:不一致的实体类型(element)、对应的文本实体(ent_t)以及视觉实体(ent_v):
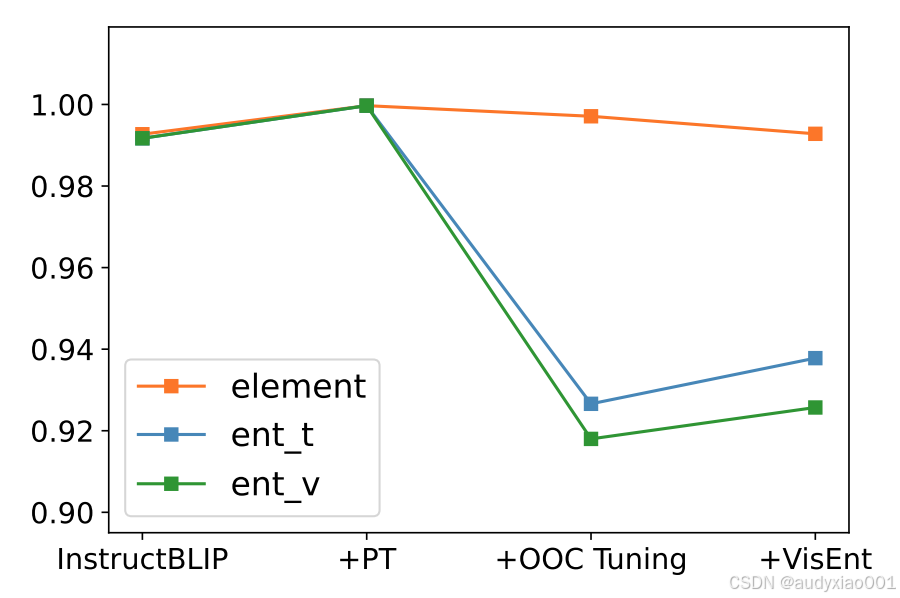
图5 响应比率
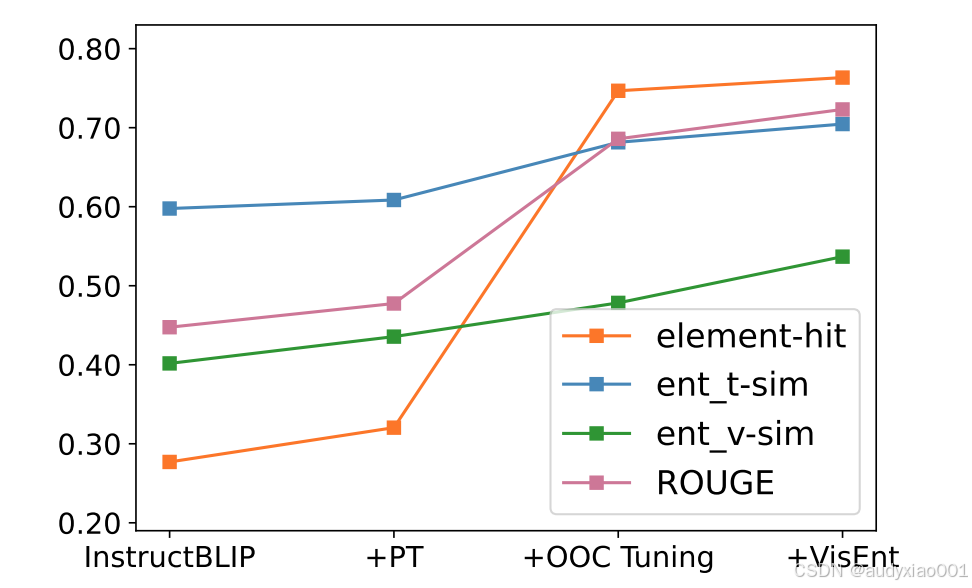
图6 解释准确性
图5展示了模型训练不同阶段的响应比率的变化。可以看到,在经过脱离上下文调优(OOC Tuning)以后,回答率明显变低,这说明模型变得保守了。图6展示了这三个信息点的准确率变化。可以看到所有衡量指标都是上升趋势,说明模型的解释能力是逐步提升的。
四、总结
论文提出了SNIFFER,一个针对脱离上下文虚假信息检测的多模态大语言模型框架。通过两阶段指令调优和外部知识增强,SNIFFER显著提升了检测准确性和可解释性。模型结合内部一致性检查与外部知识验证,全面分析图像和文本的一致性,并提供清晰的解释。实验结果表明,SNIFFER在准确性上超越了现有模型,并能够有效生成令人信服的解释,为虚假信息检测提供了新的解决方案。
EN

















 360
360

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









