






Person Re-identification overview
这是一篇关于person re-ID(行人重识别)的综述性文章,原文名:Person Re-identification:Past, Present and Future由于文章篇幅过长(page 20),所以本人在阅读这篇文献时,对文章中觉得比较重要的部分进行选择性的翻译,以期能对person re-ID快速了解。以下是原文主要内容:
从技术上讲,实际视频监控系统中的person re-ID系统可以分为三个模块:person detection,person tracking,以及person retrieval。通常来说前两个模块是独立的计算机视觉任务,所以大多数re-ID工作主要聚焦于最后一个模块person retrieval。如果没有特指的话,person re-ID指的都是person retrieval。从计算机视觉的角度来看,re-ID的主要难点在于如何实现在外观剧烈变化比如光照、姿态以及视角等变化的情况下实现同一个人在两张不同的图像中的正确匹配。
1.2 A Brief History of Person Re-ID
Person Re-ID的研究始于多目视觉跟踪(multi-camtracking),下面是Person Re-ID发展中具有里程碑式的意义的几个milestone。
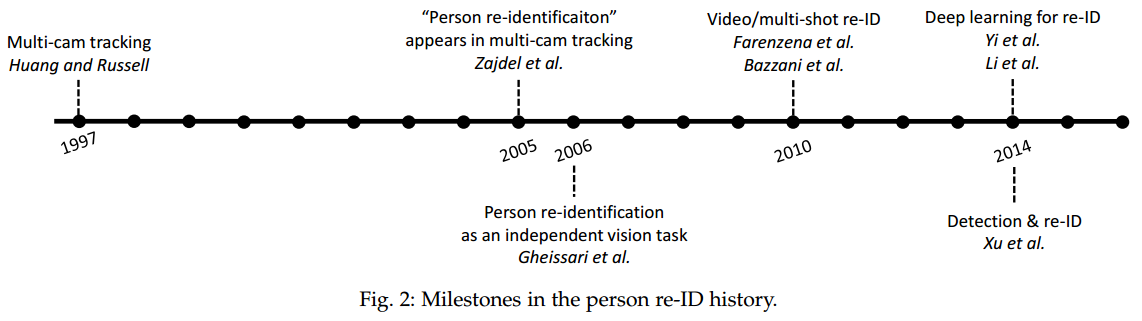
1)Multi-cameratracking:在相邻的两个摄像头之间利用外观模型进行几何校正。外观模型包括颜色,宽,高,速度,观察时间等等。
2)Multi-cameratracking with explicit “re-identification”
3) Theindependence of re-ID (image-based);
4)Video-basedre-ID;
5)Deep learningfor re-ID.;
6)End-to-endimage-based re-ID。
1.3 Relationship withClassification and Retrieval

至于Classification和Retrieval的区别关系,上面的表格就说明了,而person re-ID 却是结合了二者的优势。一方面,在训练阶段,可以从person space学习到区别能力强的distance metrics或者feature embedding。另一方面,在检索阶段,有效的indexing structures和hashing techniques(哈希)将有助于大large gallery中的re-ID。
2. IMAGE-BASED PERSON RE-ID

注:如果不理解gallery和probe(query)是什么,可以看一下下文的figure5图
2.1Hand-crafted Systems
从上面的等式中可以看出,re-ID非常重要的两个部分:imagedescription和distancemetrics。
2.1.1 Pedestrian description
在行人描述中使用的最多的特征就是color,而texturefeature则使用的相对较少。考虑到人体的构造的特点,一般都是计算weighted color histogram (WH),the maximallystablecolor regions (MSCR), and the recurrent high-structured patches (RHSP)这三种特征。WH对处于symmetrical axis赋予更高的权重,然后对每个parts计算color histogram。MSCR检测stable color regions以及提取特征包括color, area, and centroid。RHSP是一种纹理特征用于提取recurrenttexture patches。
相比上面所说的一些早期工作之外,近年来的研究的handcrafted feature或多或少都差不多。比如LOMO,SCNCD等等。除了直接使用low-level colorand texture features,另外一种好的选择就是使用attribute-based features,这个可以看作是一种mid-level representations。简单的来说就是使用低层color和texture特征训练attribute分类器,然后提取mid-level feature。
2.1.2 Distance Metric Learning
在handcrafted re-ID系统中,一个好的distance metric十分重要。因为在样本方差一致的情况下,高维视觉特征通常不会提取不变因素(the high-dimensional visual features typically do not capture theinvariant factors under sample variances)。当前已经有一些文章对度量学习方法进行了分类,监督学习/非监督学习,全局学习/局部学习等等,在person re-ID系统中,大部分的工作主要还是属于监督全局距离度量学习(supervisedglobal distance metric learning)。

基于马氏距离的基础上,涌现出了一大批距离度量学习方法。在早期一些经典的距离度量学习方法主要目标在于最近邻分类。比如the large margin nearest neighbor Learning (LMNN)以及为避免LMNN过拟合问题而改善之后方法information-theoreticmetric learning (ITML)。而近年来,Hirzer提出了relaxingthe positivity constraint的方法,使得计算开销大大减少。Chen在马氏距离的基础上附加了bilinearsimilarity使得cross-patchsimilarities得以建模。除了学习距离度量之外,还有一些方法是聚焦于learning discriminative subspaces,比如融合LDA或PCA的方法等。
除了使用马氏距离的方法之外,还有一些使用SVM和boosting的方法。这里不予叙述。
2.2Deeply-learned Systems
自从Krizhevsky et al. [14] 以a large margin的优势赢得ILSVRC12比赛之后,基于CNN的模型就开始被广泛的使用。通常来说,被广泛使用的CNN模型有两种:一是用于图像分类和目标检测的classification model;二是以images pair或triplet作为输入的Siamese model。在person re-ID中使用深度学习方法的主要bottleneck在于训练数据的缺乏,所以当前大多数基于CNN模型的re-ID方法都是使用Siamese model。
Siamese model的一个缺点就是它不能充分利用re-ID annotations。事实上Siamese model模型仅仅只需要考虑pairwise (or triplet)labels(两种图像相似与否),在re-ID中,只告诉图像pair相似与否这是属于一种弱标签(weak label)。另一种有效的策略就是使用classification/identificationmode,这种组合形式可以充分利用re-IDlabels。
在大型数据集,比如PRW,MARS,这个classification model可以不考虑训练样本的选择就能实现很好的效果,然而identificationloss 的应用要求每一个ID需要更多的训练样例才能保证模型收敛。为了对了各类模型在re-ID的实验效果,文章展示了一些各种类型的models的baseline实验结果,如下表格所示
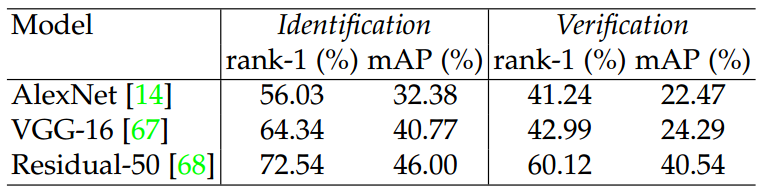
除了上述以end-to-end 的形式学习deep feature之外,文章还提及了可以采用lower-level feature作为输入。
2.3 Datasets and Evaluation
2.3.1 Datasets
以下是person re-ID中经常被使用的数据集。测试做多的benchmark就是VIPeR数据集。

近几年的数据集的变化主要在于这么几个方面:
首先,数据集的规模正在逐渐扩大,早期的数据集都相对来说较小,但是最近的数据集都比较大,比如CUHK03和Market-1501都是拥有1000+的IDs和1000+的boundingboxes。
其次,bounding boxes开始倾向于通过行人检测器(比如,DPM,ACF)来给出,而不是手工标注。
第三,在收集数据集时将会采用更多的摄像头。例如数据集Market-1501每个人多达6个摄像头。这就要求metriclearning 方法拥有很好的泛化能力。
2.3.2 Evaluation Metrics
评估re-ID算法,采用的比较多的就是累计匹配曲线(cumulative matching characteristics ,CMC)。CMC曲线表示一个query identity出现在不同大小的candidate lists 的概率值。不管在gallery中有多少ground truth匹配上,CMC始终只计算第一个被匹配的ground truth。所以,总的来说,只有当每个query只有一个ground truth时,CMC作为评估方法是非常准确有效。
然而,随着研究的深入,当gallery中存在多个ground truths时,文章中提到也有人提出使用平均准确率(mean average precision ,mAP)进行评估。
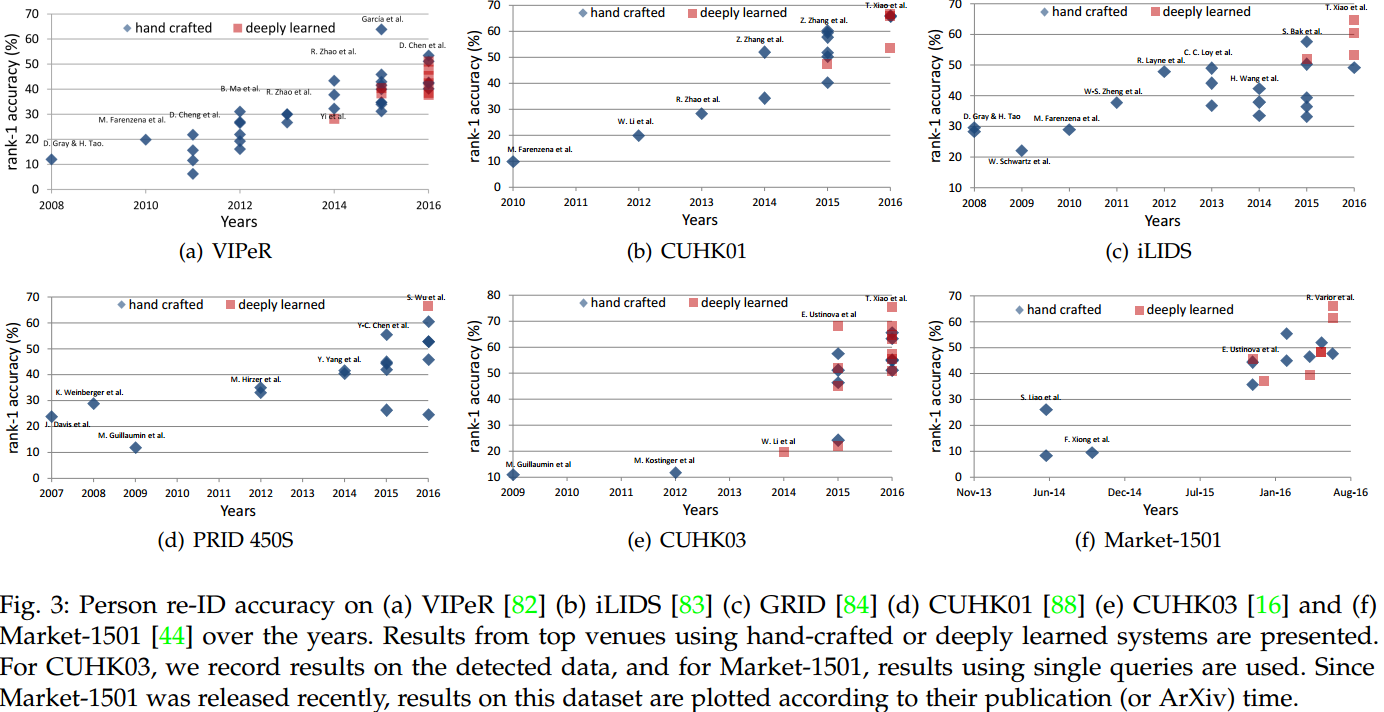
2.3.3 Re-ID Accuracy over the Years
作者对当前广泛采用的re-ID方法进行大致的分类:handcrafted and deeply learned。下面是这两种方法近年来在一些数据集测试的准确率的情况。
3 VIDEO-BASED PERSON RE-ID

image-based re-ID关注的是single shot matching 而video-based则关注的是multi-shot matching和temporal information的结合。video-based re-ID也可以分为hand-crafted和deeply learned 两种方法,具体的可以参阅作者原文。
4 FUTURE: DETECTION,TRACKING AND PERSON RE-ID
4.1previous works
尽管re-ID当前被当作是一个独立的研究任务,但作者看来,与行人检测、跟踪相结合会是未来的主要发展方向。确切的来说,一个end-to-end的re-ID系统是以raw videos作为输入,结合行人检测和跟踪,然后在进行重识别re-identification。
目前,大多数re-ID工作都是基于这两个假设的基础上开展的:1)gallery中行人的bounding boxes是给定的;2)bounding boxes是手工的hand-drawn。在这样的假设下,person re-ID才会有很好的检测精度。然而,在实际中这两个假设都是不存在的。
一方面,gallery 的大小会受检测阈值的影响。一个小的检测阈值会产生超多的bounding boxes(a larger gallery, higher recall, and lower precision),反之亦然。当检测的召回率/准确率由于阈值不同而发生变化时,re-ID精度会不稳定。另一方面,当使用行人检测器pedestriandetectors时,boundingboxes 检测误差/错误是不可避免的。比如误对齐misalignment,漏检Miss-detection以及误检false alarm等。另外,当使用行人跟踪器pedestrian trackers时,跟踪错误会导致在一个tracklet中产生异常帧(outlier frames)。
所以行人检测和跟踪的质量会直接影响到re-ID的准确率,而这却是在re-ID中很少会被考虑到的。基于上面几个点,所以有很多数据集比如CUHK03、Market-1501和MARS等开始就提供the detected bounding boxes和hand-drawn bounding boxes进行训练和测试。这些工作更贴近实际应用。
尽管当前有部分数据集开始引入detection/tracking errors ,但却并没有明确的估计detection/tracking是如何影响re-ID,因此在end-to-endre-ID系统中如何选取一个合适的detectors/trackers十分重要。Xu et al在2014年首次提出end-to-end person re-ID系统。在2016年Xiao et al和Zheng et al同时提出基于大规模数据集的end-to-end re-ID系统。这两个工作都是以raw video frames 和 a query bounding boxes作为输入。如图figure5所示。

在给定同样一组re-ID feature的条件下,一个好的pedestrian detector往往能产生更高的re-ID精度。此外,在所谓的“end-to-end”系统中,并没有人去提及并处理pedestrian tracking对re-ID的影响,而这个工作却被视为将detection、tracking和retrieval整合成为一个完整框架的终极目标“ultimate goal”
由于原文篇幅过长,后面都是关于person re-ID的future issue/works,有兴趣的话可以去直接阅读原文,这里暂不予以介绍。















 2124
2124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









