






目录
前言
本文记录梅科尔工作室深度学习培训的第三讲-KNN算法学习笔记,感谢义哥的讲解!
1. 什么是KNN算法
KNN(K-Nearest Neighbor)算法,意思是K个最近的邻居。K个最近邻居,毫无疑问,K的取值肯定是至关重要的。KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。
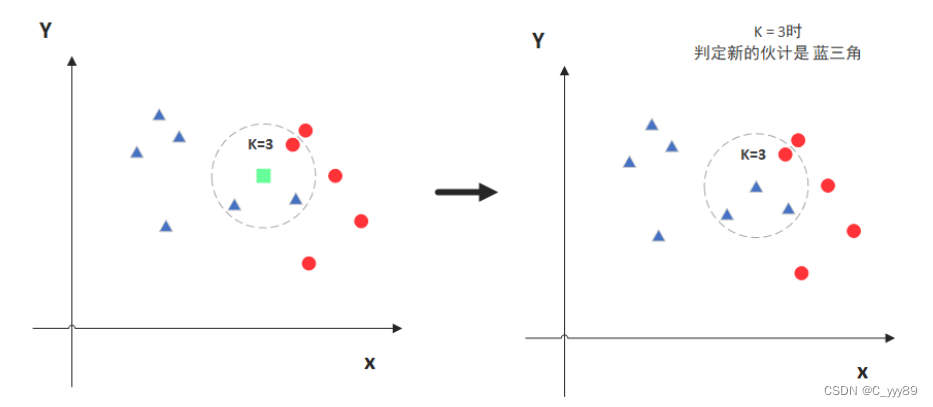
图中绿色的点就是我们要预测的那个点,假设K=3,那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
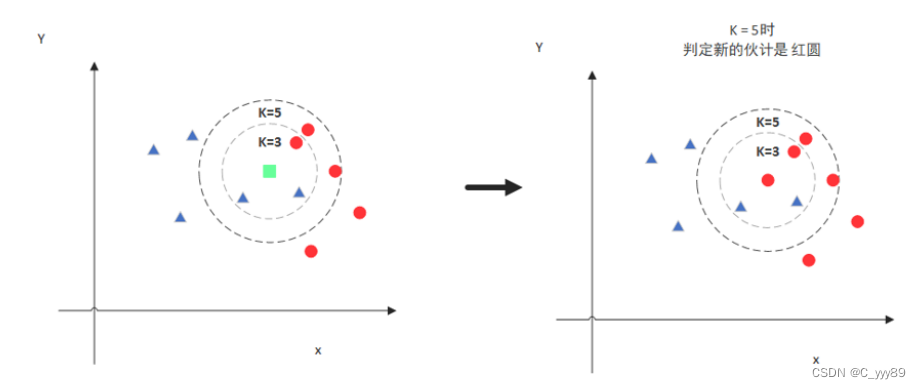
但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。 (K值一般取值为3-7)
2.KNN算法的实现步骤
2.1.计算距离(欧几里得距离或者马氏距离)

2.2.升序排序
2.3.取前K个
K太大:导致分类模糊
K太小:受个例影响,波动较大
2.4.加权平均
经验判断
3.实战应用
Sklearn库参考这里:(55条消息) 非常详细的sklearn介绍_机器学习算法那些事的博客-CSDN博客_sklearn
KNN算法求病人癌症检测的正确率
import csv
import random
# 读取数据为字典格式
with open(".\Prostate_Cancer.csv","r") as f:
render = csv.DictReader(f)
datas = [row for row in render]
# 分组,打乱数据
random.shuffle(datas)
n = len(datas)//3 # 划分数据为3:7
test_data = datas[0:n] # 测试集为3份
train_data = datas[n:] # 训练集为7份
# print (train_data[0])
# print (train_data[0]["id"])
# 计算对应的距离(欧几里得距离)
def distance(x, y):
res = 0
for k in ("radius", "texture", "perimeter", "area", "smoothness", "compactness", "symmetry", "fractal_dimension"):
res += (float(x[k]) - float(y[k]))**2 # 需要将字符串形式数据转为float形式
return res ** 0.5
# K=6
def knn(data,K):
# 1. 计算距离
res = [
{"result": train["diagnosis_result"], "distance":distance(data, train)}
for train in train_data
]
# 2. 排序
sorted(res, key=lambda x: x["distance"])
# print(res)
# 3. 取前K个
res2 = res[0:K]
# 4. 加权平均
result = {"B": 0, "M": 0}
# 4.1 总距离
sum = 0
for r in res2:
sum += r["distance"]
# 4.2 计算权重
for r in res2 :
result[r['result']] += 1-r["distance"]/sum
# 4.3 得出结果
if result['B'] > result['M']: # 看B与M的比例大小,谁大属于谁
return "B"
else:
return "M"
# print(distance(train_data[0],train_data[1]))
# 预测结果和真实结果对比,计算准确率
for k in range(1,11):
correct = 0
for test in test_data:
result = test["diagnosis_result"]
result2 = knn(test,k)
if result == result2:
correct += 1
print("k="+str(k)+"时,准确率{:.2f}%".format(100*correct/len(test_data)))运行结果
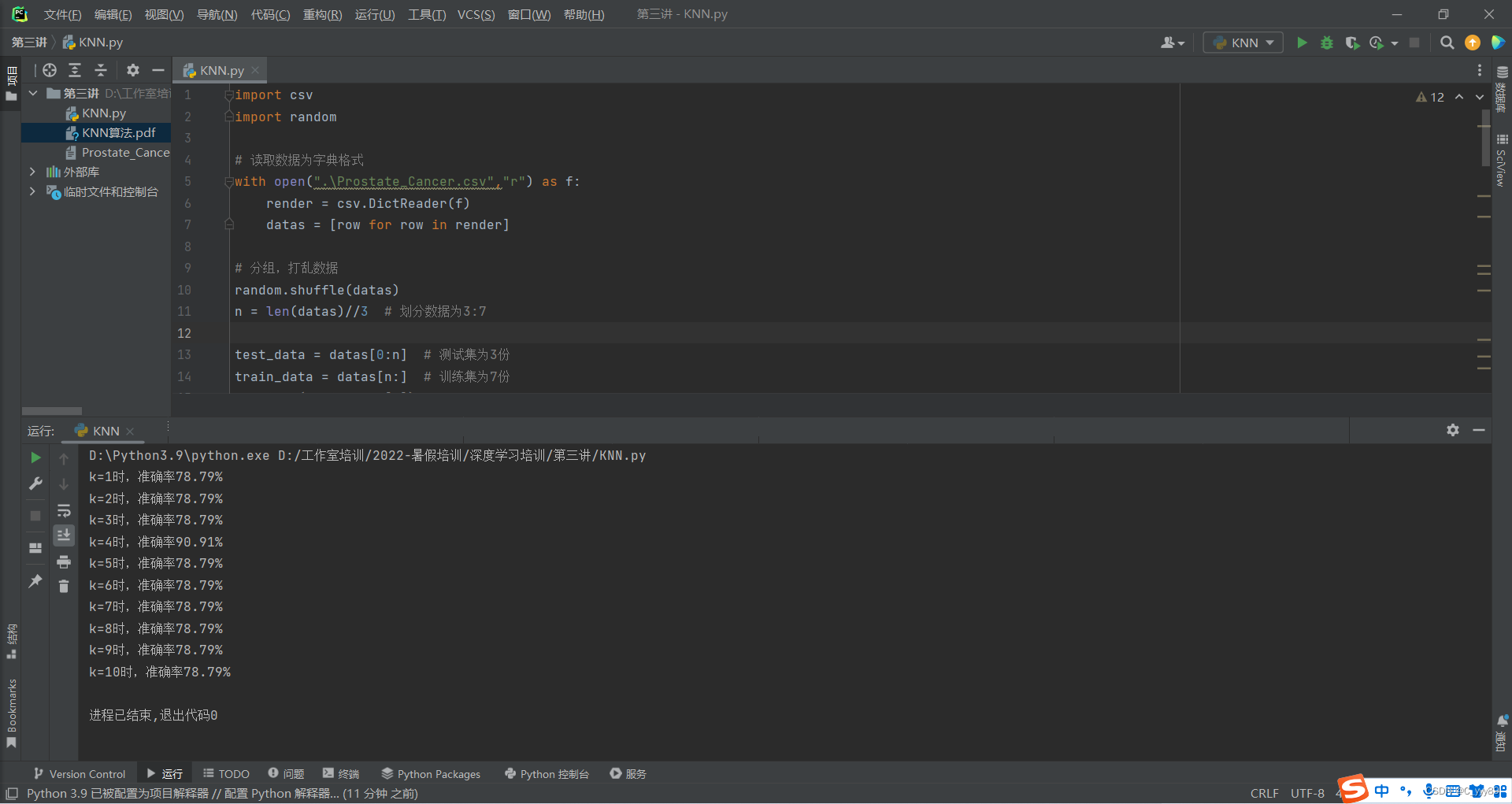
可以看到,当k=4时,准确率最高。
总结
第三讲-KNN算法学习笔记到这里就结束了,感谢义哥!















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









