







图像分析
概览
前几章学习到的图像变换,本质上是从输入图像到输出图像的映射,即输出仍是一副图像,就像输入那样。
本章中的一些新操作,将图像转换成一种可能完全不同的表现形式。
这些新的表现形式仍然是一些数组,只是这些数组中的值在含义上将与源图想中的强度值大不相同。比如,马上就要提到的方法:离散博立叶变换,它的输出图像仍然是个数组,只不过是输入图像的频域表示。在某些方法中,变换结果会是一系列成分的序列而不是一个数组,霍夫线变换就属于这种情况。
离散傅里叶变换(DFT)
(不得不承认,看到这里后,就完全被傅里叶三字给统治了!!!)
了解傅里叶变换,看这里、看这里
https://zhuanlan.zhihu.com/p/19763358
.
复数的物理意义
https://www.zhihu.com/question/23234701/answer/26017000
傅里叶分析
傅里叶最先发现,一个函数可以分解成一系列其它函数的表示,这就是后来的傅里叶分析。
快速傅里叶变换 (FFT)
高斯于1805年首次提出了快速傅里叶变换的关键步骤,但实际上是由Cooley和Tukey于1965年才发明了这个方法。
一维DFT由如下公式定义
i
=
−
1
i=\sqrt[]{-1}
i=−1:
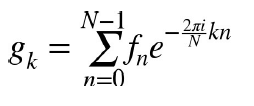
对于二维数值数组,也可以定义变换:
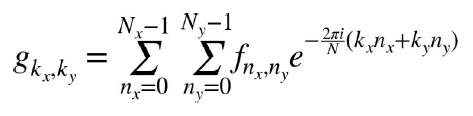
一般,计算项数为N的变换预计需要
O
(
N
2
)
O(N^2)
O(N2)次运算。实际上,有几种快速傅里叶变换(FFT)算法可以在
O
(
N
l
o
g
N
)
O(N log N)
O(NlogN)复杂度内计算这些值。
c v : : d f t ( ) cv::dft() cv::dft()离散傅里叶变换
opencv的cv::dft()函数实现了一种这样的FFT算法。函数cv::dft()可以计算一维和二维输入数组的FFT。在后一种情况下,可以计算二维变换,或者如果需要,也可以只对每一行单独进行一维变换,这样做比多次调用cv::dft()快很多。
void cv::dft(
cv::InputArray src, // Input array (real or complex)
cv::OutputArray dst, // Output array
int flags = 0, // for inverse, or other options
int nonzeroRows = 0 // number of rows to not ignore 不能忽略的行数
);
输入阵列必须是浮点型,可以是单通道或双通道。如果是单通道数组,那么数组必须是实数组,并且输出将以复数共轭对(CCS)的形式保存。如果输入是双通道的,那么两个通道分别代表实部和虚部。在这种情况下,不会出现特殊的结果,当然输入和输出数组的一些空间会被大量的0填充而浪费。
第三个参数flags说明了要完成的操作。通常把flags当作一个位数组,所以你可以将自己需要的任何标志与布尔OR组合。默认选项是前向变换,逆变换需使用
c
v
:
:
D
F
T
_
S
C
A
L
E
cv::DFT\_SCALE
cv::DFT_SCALE标志。
要进行没有比例因子的逆变换,使用标志
c
v
:
:
D
F
T
_
I
N
V
E
R
S
E
cv::DFT\_INVERSE
cv::DFT_INVERSE即可。尺度因子的标志为
c
v
:
:
D
F
T
_
S
C
A
L
E
cv::DFT\_SCALE
cv::DFT_SCALE,意味着输出的所有项尺度因子为
N
−
1
N^{-1}
N−1,如果二维变换则尺度因子是
(
N
x
N
y
)
−
1
(N_xN_y)^{-1}
(NxNy)−1。为了使正变换之后逆变换的结果与初始保持一致,尺度变换是必须的。
标识 c v : : D F T _ R O W S cv::DFT\_ROWS cv::DFT_ROWS告诉 c v : : d f t ( ) cv::dft() cv::dft()将二维数组当作一个一维数组的集合,每个数组应分别转换长度为各个不同的向量。当一次进行大量变换时,这样做可以显著减少开销。通过使用 c v : : D F T _ R O W S cv::DFT\_ROWS cv::DFT_ROWS,还可以实现三维或更高维的DFT。
前向变换默认生成CCS格式的结果(输出数组的大小与输入数组完全相同),你仍然可以通过使用标识 c v : : D F T _ C O M P L E X _ O U T P U T cv::DFT\_COMPLEX\_OUTPUT cv::DFT_COMPLEX_OUTPUT让opencv不这么做,获得一个复数组。相对而言,当对一个复数组进行逆变换时,结果也使一个复数组。如果原数组具有复共轭对称性,可以通过使用标识 c v : : D F T _ R E A L _ O U T P U T cv::DFT\_REAL\_OUTPUT cv::DFT_REAL_OUTPUT让opencv产生一个比输入数组小的纯实数组。
最后一个参数nonzerRows。一般而言,DFT算法倾向于某些特定长度的输入向量,而不是其它长度的输入向量;类似的,对于数组来说,也倾向于某些特定大小的数组,而不是其他大小的数组。大多数DFT算法,这个大小最好是2的幂(比如大小维 2 n 2^n 2n的某个整数)。在opencv使用的算法中,优先考虑的向量长度或数组维数 2 p 3 q 5 r 2^p3^q5^r 2p3q5r的整数,其中p,q,r是整数。因此常用的方法是创建一个更大的数组,然后将原数组复制至此,空白位置用0填充。为了方便起见,有一个方便的效用函数 c v : : g e t O p t i m a l D F T S i z e ( ) cv::getOptimalDFTSize() cv::getOptimalDFTSize(),它获取向量的(整数)长度后,会返回一个特定大小的值(这样的序列中,大小等于原向量的(整数)长度的第一个值)。虽然这些填充是需要的,但仍然可以指定 c v : : d f t ( ) cv::dft() cv::dft()不进行这些变换,以保留真实数据。(或者,在进行逆变换时,也可以指定哪些行是你不在意的。)无论哪种情况,你都可以使用nonzerRows指明有效数据的行数来节省计算时间。
c v : : i d f t ( ) cv::idft() cv::idft()用于离散傅里叶逆变换
虽然cv::dft()不仅可以实现离散傅里叶变换,还可以实现逆变换,但是为了代码的可读性,应当使用有专门功能的函数进行逆变换。
void cv::idft(
cv::InputArray src, // Input array (real or complex)
cv::OutputArray dst, // Output array
int flags = 0, // for variations
int nonzeroRows = 0 // number of rows to not ignore
);
调用cv::idft()等价于调用标志为cv::DFT_INVERS的cv::dft()(当然前提是不为cv::idft()提供任何标志位)。
c v : : m u l S p e c t u r m s ( ) cv::mulSpecturms() cv::mulSpecturms()频谱乘法
在大多数涉及到傅里叶变换的计算中,还必须计算两个频谱的逐元素乘积。由于傅里叶变换的结果一般都是复数,通常又是高密度的CCS格式,所以这种情况下进行解析并进行矩阵乘法是很繁琐的。幸运的是,opencv提供了函数cv::mulSpectrums()来实现这个功能。
void cv::mulSpectrums(
cv::InputArray src1, // Input array (ccs or complex)
cv::InputArray src2, // Input array (ccs or complex)
cv::OutputArray dst, // Result array
int flags, // for row-by-row computation
bool conj = false // true to conjugate src2
);
前两个参数是数组,必须同时为CCS格式单通道频谱或双通道复数频谱,这可以通过cv::dft()获取。第三个参数是目标数组,大小和类型将与输入数组保持一致。最后一个参数conj告诉cv::mulSpectrum()你的具体目的。其中,设置false实现了原数组的乘法;设置为真实现了前一个数组的元素与第二个数组的复共轭的乘法。(此参数的主要用法是傅里叶空间中的相关性的实现。事实证明,卷积核相关性之间的唯一区别是频谱乘法中的第二个阵列的共轭。)
使用傅里叶变换进行卷积
可以通过卷积定理使用DFT(离散傅里叶变换)大大提高卷积的速度,该卷积定理将空间域中的卷积与傅里叶域中的乘积相关联。为了实现这一点,我们首先计算图像的傅里叶变换,然后计算卷积滤波器的傅里叶变换;一旦完成,我们在变换空间中完成卷积的时间就能缩减到与图像像素数成线性。
// Example 12-1. Using cv::dft() and cv::idft() to accelerate
// the computation of convolutions
#include <iostream>
#include <opencv2/opencv.hpp>
using std::cout;
using std::endl;
int main(int argc, char** argv) {
if (argc != 2) {
cout << "\nExample 12-1. Using cv::dft() and cv::idft() to accelerate the"
<< "\n computation of convolutions"
<< "\nFourier Transform\nUsage: "
<< argv[0] << " <path/imagename>\n" << endl;
return -1;
}
cv::Mat A = cv::imread(argv[1], 0);
if (A.empty()) {
cout << "Cannot load " << argv[1] << endl;
return -1;
}
cv::Size patchSize(100, 100);
cv::Point topleft(A.cols / 2, A.rows / 2); //定义图像中间的点
cv::Rect roi(topleft.x, topleft.y, patchSize.width, patchSize.height); //定义矩形,大小为parthSize,位置为图像A中中间的位置(x,y)
cv::Mat B = A(roi); //根据这个在图片A上矩形roi大小的区域构建,矩阵B
//cv::getOptimalDFTSize函数返回一个随机数生成器,该生成器的范围是(矩阵A的行数+矩阵B的行数-1,A的列数+B的列数-1)
int dft_M = cv::getOptimalDFTSize(A.rows + B.rows - 1);
int dft_N = cv::getOptimalDFTSize(A.cols + B.cols - 1);
//cv::Mat::zeros构建一个全0矩阵,它的大小为dft_M行,dft_N列,数据类型为cv_32f
cv::Mat dft_A = cv::Mat::zeros(dft_M, dft_N, CV_32F);
cv::Mat dft_B = cv::Mat::zeros(dft_M, dft_N, CV_32F);
//从矩阵dft_A中位置(0,0)的位置,取大小为 A.cols, A.rows的部分
cv::Mat dft_A_part = dft_A(cv::Rect(0, 0, A.cols, A.rows));
cv::Mat dft_B_part = dft_B(cv::Rect(0, 0, B.cols, B.rows));
//将A转换为dft_A_part.type()类型,输出到dft_A_part中,比例为1保持不变,对缩放后的值求平均,取第一个使用
//将数组转换为具有可选缩放功能的其他数据类型。
A.convertTo(dft_A_part, dft_A_part.type(), 1, -mean(A)[0]);
B.convertTo(dft_B_part, dft_B_part.type(), 1, -mean(B)[0]);
//进行离散傅里叶变换
cv::dft(dft_A, dft_A, 0, A.rows);
cv::dft(dft_B, dft_B, 0, B.rows);
// set the last parameter to false to compute convolution instead of correlation
//
cv::mulSpectrums(dft_A, dft_B, dft_A, 0, true); //返回给定向量大小的最优DFT大小。
cv::idft(dft_A, dft_A, cv::DFT_SCALE, A.rows + B.rows - 1); //离散傅里叶逆变换
cv::Mat corr = dft_A(cv::Rect(0, 0, A.cols + B.cols - 1, A.rows + B.rows - 1));
cv::normalize(corr, corr, 0, 1, cv::NORM_MINMAX, corr.type()); //机器学习--神经网络---优化器方法中的标准化(归一化),这里使用的是最大最小值归一
cv::pow(corr, 3.0, corr); //计算每个数组元素的指数
B ^= cv::Scalar::all(255); //按位异或,对B中的每一个值进行操作。
cv::imshow("Image", A);
cv::imshow("ROI", B);
cv::imshow("Correlation", corr);
cv::waitKey();
return 0;
}

cv::dct()离散余弦变换
对于实数数据,通常很容易计算其离散傅里叶变换。实际上这一过程实际需要的计算量只有表面看起来的一半。离散余弦变换(DCT)与完全离散傅里叶变换定义类似。
注意:按照惯例,余弦变换及其逆变换都应该采用归一化因子(而在离散傅里叶变换中则没有此要求)
DFT的基本思想同样适用于DCT,只是所有系数都变成了实数。(不能将余弦变换用于非偶数的向量,cv::dct()简单用镜像的方式将向量在负数上进行扩展,使其变成偶数)
void cv::dct(
cv::InputArray src, // Input array (even size)
cv::OutputArray dst, // Output array
int flags = 0 // for row-by-row or inverse ,标志位,逐行或反向
);
由于结果是实数值,因此没必要对结果数组或输入数组进行特别的打包。与cv::dft()不同的是,输入数组的大小必须是偶数。如果不是,可以在数组最后补0使其变成偶数。
参数flags可以设置为cv::DCT_INVERSE以进行逆变换,并且可以与cv::DCT_ROWS组合使用,与cv::dft()具有相同的效果。由于归一化方式的不同,余弦变换的前向变换和逆变换都包含它们对变换的全局归一化的贡献;因此,cv::dct()没有cv::DFT_SCALE选项。
与cv::dft()一样,cv::dct()的性能很大程度上依赖数组大小。其实,如果深入分析,cv::dct()的实现实际上是在一个数组上调用cv::dft(),这个数组大小恰恰就是输入数组的一半。因此,cv::dct()所需数组的最佳大小刚好是cv::dft()所需的两倍。综合考虑,计算cv::dct()的最佳大小的最好方式如下:
s
i
z
e
_
t
o
p
t
i
m
a
l
_
d
c
t
_
s
i
z
e
=
2
∗
c
v
:
:
g
e
t
O
p
t
i
m
a
l
D
F
T
S
i
z
e
(
(
N
+
1
)
/
2
)
size\_t optimal\_dct\_size = 2 * cv::getOptimalDFTSize( (N+1)/2 )
size_toptimal_dct_size=2∗cv::getOptimalDFTSize((N+1)/2)
其中的N是要转换的数据的实际大小。
cv::idct()离散余弦逆变换
虽然可以通过在cv::dct()函数中设置flags(标志)位,实现逆变换,但是为了更好的代码可读性,独立定义了函数cv::idct()
void cv::idct(
cv::InputArray src, // Input array
cv::OutputArray dst, // Output array
int flags = 0, // for row-by-row computation
);
调用cv::idct()等价于调用标志为cv::DCT_INVERSE的cv::dct()(前提是不向cv::idct()传递其他标志)。
积分图
通过cv::integral()函数,可以轻松的计算积分图。积分图是一种允许子区域快速求和的数据结构。这种求和在很多方面都很有用,例如Harr小波的计算,它用于人脸识别和类似算法。
opencv支持积分图的三种变体,分别是总和、平方求和以及倾斜求和。每种情况的结果图像在图像的每个方向上都加1之后,与原始图像的大小相同。
cv::integral()标准求和积分
在C++的API中,不同形式的积分通过参数来区分。计算基本总和的形式只有三个。
void cv::integral(
cv::InputArray image, // Input array
cv::OutputArray sum, // Output sum results
int sdepth = -1 // Results depth (e.g., cv::F32)
);
第一个参数和第二个参数是输入和输出图像,如果输入图像的大小是 W × H W\times H W×H,输出图像的大小就是 ( W + 1 ) × ( H + 1 ) (W+1)\times(H+1) (W+1)×(H+1)。第三个参数sdepth指明求和图像(结果图像)需要的深度。sdepth可以是cv::S32,cv::F32或cv::F64。
cv::integral()平方求和积分
使用的函数与计算标准求和积分一样,不同的是还增加了一个额外的输出参数用于保存平方求和。
void cv::integral(
cv::InputArray image, // Input array
cv::OutputArray sum, // Output sum results
cv::OutputArray sqsum, // Output sum of squares results
int sdepth = -1 // Results depth (e.g., cv::F32)
);
cv::OutputArray类型的参数sqsum告诉cv::integral()除了标准求和还要计算平方和。
sdepth指明求和图像(结果图像)需要的深度。sdepth可以是cv::S32,cv::F32或cv::F64。
cv::integral()倾斜求和积分
与平方求和类似,求倾斜求和积分有着同样的函数,还需要一个附加的参数来得到一个附加的结果。
void cv::integral(
cv::InputArray image, // Input array
cv::OutputArray sum, // Output sum results
cv::OutputArray sqsum, // Output sum of squares results
cv::OutputArray tilted, // Output tilted sum results
int sdepth = -1 // Results depth (e.g., cv::F32)
);
除了其它的和,cv::OutputArray类型的附加参数titled作为一个附加的项由函数cv::integral()计算而来,除此之外,其它的参数相同。
Canny边缘检测
在Canny边缘检测算法中,现在x和y方向上求得一阶导,然后将它们组合成为四个方向的导数。其中方向导数是局部最大值的点是组成边缘的候选项。canny算法最明显的创新点,就是将单个的边缘候选像素加入轮廓。
opencv中的cv::Canny()函数实际上并不返回轮廓类型的对象,如果需要,必须使用cv::findContours()从cv::Canny()的输出结果构建它们。
算法通过对像素应用滞后阈值来形成这些轮廓,也就是说算法采用了两个阈值,一个较大值和一个较小值。如果一个像素的梯度大于较大值,就接受;如果小于较小值,就抛弃;但如果介于两者之间,那么只有当它连接到一个高于阈值的像素时,才接受。Canny算法建议高阈值:低阈值介于2:1和3:1之间。
cv::Canny()
Canny边缘检测算法的opencv实现将输入图像转换成“边缘图像”
void cv::Canny(
cv::InputArray image, // Input single channel image
cv::OutputArray edges, // Output edge image
double threshold1, // "lower" threshold
double threshold2, // "upper" threshold
int apertureSize = 3, // Sobel aperture
bool L2gradient = false // true=L2-norm (more accurate)
);
输入图像必须是单通道图像,
输出图像是灰度图(实际上是一副布尔图)
接下来的两个参数是低阈值和高阈值。
最后两个参数中,apertureSize是cv::Canny()内部调用的Sobel导数算子所用的aperture的大小;
最后一个参数L2gradient用于选择是使用适当的
L
2
L_2
L2范数“正确”计算方向梯度,还是速度更快但精度更低的基于
L
1
L_1
L1范数的方法。如果L2gradient取true,就使用公式:
∣
g
r
a
d
(
x
,
y
)
∣
L
2
=
(
d
I
d
x
)
2
+
(
d
I
d
y
)
2
|grad(x,y)|_{L_2}=\sqrt[]{(\frac{dI}{dx})^2+(\frac{dI}{dy})^2}
∣grad(x,y)∣L2=(dxdI)2+(dydI)2
否则使用:
∣ g r a d ( x , y ) ∣ L 2 = ∣ d I d x ∣ + ∣ d I d y ∣ |grad(x,y)|_{L_2}=|\frac{dI}{dx}|+|\frac{dI}{dy}| ∣grad(x,y)∣L2=∣dxdI∣+∣dydI∣
Hough变换
Hough(霍夫)变换是一种用于检测线、圆或者图像中其它简单形状的方法。最初Hough变换是一种线变换,这是一种相对较快的检测二值图像中直线的方法,可以进一步推广到除简单线之外的情况。
Hough线变换
基本理论:二进制图像中的任何点都可能属于某些可能的线。如果我们将每一条线参数化,如斜率为a,截距为b,原始图像中的点就可以转换为对应于通过该点的所有线在平面(a,b)中的点的轨迹,当然可能只是一部分轨迹。如果我们将原图中每个非零像素都转换成输出图像中这样的一系列点,并将所有这些贡献相加,那么原图((x,y)平面)中的线将显示为输出图像((a,b))中局部最大值。由于我们对每个点的贡献进行求和,所以(a,b)平面通常称为“累加器平面”
opencv支持三种Hough线变换:标准Hough变换(SHT)、多尺度Hough变换(MHT)和渐进概率Hough变换(PPHT)。MHT是对SHT算法的细化,对线的匹配精度更高。PPHT是一种改进算法,这种算法除了计算一条独立直线的方向外还计算它的延长线。是“概率性的”,因为它没有对平面中的每一个可能点都进行累积,它只累积其中的一小部分。这个方法的思想是:如果峰值足够高,那么只需要花很少的时间就足够获得结果,这个猜想的结果可以大幅度减少计算时间。
cv::HoughLines():标准和多尺度Hough变换
标准和多尺度Hough变换都由函数cv::HoughLines()实现,两种不同的用法由两个可选参数区分。
void cv::HoughLines(
cv::InputArray image, // Input single channel image
cv::OutputArray lines, // N-by-1 two-channel array
double rho, // rho resolution (pixels)
double theta, // theta resolution (radians)
int threshold, // Unnormalized accumulator threshold
double srn = 0, // rho refinement (for MHT)
double stn = 0 // theta refinement (for MHT) );
第一个参数是输入图像,它必须是一副8位图像,同时输入图像被当作是二值图(即非0像素含义全部一样)。
第二个参数是结果存放位置,是一个N*1的双通道浮点数组(列数N是返回的直线数目)。两个通道分别包含每条线的
r
h
o
(
ρ
)
rho(\rho)
rho(ρ)和
t
h
e
t
a
(
θ
)
theta(\theta)
theta(θ)值。
接下来的两个参数rho和theta设置直线所需的分辨率(即累加平面的分辨率)。rho的单位是像素,而theta的单位是弧度,因而,累加平面可以考虑成一个由 θ \theta θ弧度大小为 ρ \rho ρ像素的单元组成的二维直方图。threshold是累加平面中算法用于判断线条属于一条直线的阈值。
最后一个参数在使用的时候有些麻烦,它不是归一化的,所以你应该用图像大小对它进行缩放。这个参数实际上指明了轮廓图返回的直线至少应包含的点的数量。
参数srn和stn用于控制称为“多尺度Hough变换”(MHT)的SHT算法的扩展,不用于标准Hough变换。在MHT中,这两个参数指明了没条直线所应达到的分辨率。MHT首先以rho和theta参数给出的精度计算线的位置,然后通过参数srn和stn来细化这些结果(rho的最终分辨率是 ρ \rho ρ除以srn,theta的最终分辨率是 θ \theta θ除以stn)。将这些参数设为0时,函数将采用SHT算法。
用cv::HoughLinesP()渐进概率Hough变换
void cv::HoughLinesP(
cv::InputArray image, // Input single channel image
cv::OutputArray lines, // N-by-1 4-channel array
double rho, // rho resolution (pixels)
double theta, // theta resolution (radians)
int threshold, // Unnormalized accumulator threshold
double minLineLength = 0, // required line length
double maxLineGap = 0 // required line separation
);
函数cv::HoughLinesP()与cv::HoughLines()相似,但有两个重要的区别。第一个是lines参数变成四通道(或者一个Vec4i类型的向量)。四通道分别是找出的线段两个端点的坐标 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)和 ( x 1 , y 1 ) (x_1,y_1) (x1,y1)(按顺序)。第二个重要的区别是两个参数的含义。PPHT中,minLineLength和maxLineGap参数设置了返回线段的最小长度,以及共线线段之间的最小间隔,防止算法把他们连结成一条。
Hough圆变换
Hough圆变换的方法与之前描述的线变换方法相似。粗略解释,如果尝试用完全类似的方法去做,就要从累加平面变成累加三维的体积,三维坐标分别是圆心的位置x、y和圆的半径r。但是这样做意味着更大的内存需求和更慢的速度。opencv中圆变换的实现通过采用一种称为Hough梯度法的较为复杂的方法来避免了这个问题。
Hough梯度法的工作过程
首先,对图像进行边缘检测;
然后,对每个轮廓图像中的非零点,考虑局部梯度(首先通过cv::Sobel()计算一阶Sobel x-导数和y-导数来计算梯度)。通过这个梯度,我们沿着这个斜率表示的线在累加器内从一个最小值到一个最大值遍历每个点,同时记录轮廓图像中每个非零像素所在的位置。然后候选圆心就从这些(二维)累加器中分离出来,这些点都高于一个阈值且同时大于其所有直接相邻的点。这些点根据其累加器值的降序排列,使得最有可能是圆心的点排在前面。然后对于每个圆心,考虑所有非零像素点(之前已经构建好该列表),将这些像素根据离圆心的距离排序。从最小距离到最大半径中选择一个最好的值作为圆的半径。如果有足够数量的点组合成一个圆并且圆心与之前选中圆心的距离足够大,就保留这个圆心。
这个算法需要注意的地方:
第一,用Sobel导数计算局部梯度——伴随的假设是这可以被认为相当于一个局部切线——不是一个数值稳定的命题,甚至“大部分时间”都是这样,但是你应该期望在输出中产生一些噪音。
第二,对每个候选圆心进行判断时要考虑轮廓图像中所有非零像素。因此,如果累加器阈值过低,算法就会很慢。
第三,因为对每个圆心都只能选择一个圆,所以如果出现同心圆,最终将只能得到一个。
最后,由于圆心根据累加器值升序排列,并且圆心距离先前被接受的圆心太近会被舍去,因而出现同心或近似同心圆时,算法更倾向于保留大圆。(由于Sobel导数产生的噪声,它只是一种“倾向”,但在无限分辨率下的平滑图像中,它就是必然的了。)
用cv::HoughCircles()进行Hough圆变换
Hough圆变换函数cv::HoughCircles()的参数与线变换函数类似。
void cv::HoughCircles(
cv::InputArray image, // Input single channel image
cv::OutputArray circles, // N-by-1 3-channel or vector of Vec3f
int method, // Always cv::HOUGH_GRADIENT
double dp, // Accumulator resolution (ratio)
double minDist, // Required separation (between lines)
double param1 = 100, // Upper Canny threshold
double param2 = 100, // Unnormalized accumulator threshold
int minRadius = 0, // Smallest radius to consider
int maxRadius = 0 // Largest radius to consider
);
输入图像是一副8位图像,cv::HoughCircles()和cv::HoughLines()最大的区别就是后者需要的是二值图像。cv::HoughCircles()内部调用的是cv::Sobel()而不是cv::Canny(),其原因是cv::HoughCircles()需要估计每个像素的梯度方向,这在二值轮廓图中很难做到,因此可以使用更普遍的灰度图。
结果数组circles是一个矩阵数组或向量,取决于传入cv::HouhgCircles()的内容。如果是个矩阵,他将是cv::F32c3类型的一维数组;三个通道分别是圆的坐标及半径。如果是个向量,那么它的类型是std::vector。method参数的值实际设置为cv::HOUGHGRADIENT.
参数dp是所使用的累加图像的分辨率。这个参数允许我们创建一副分辨率比输入图像更低的累加器。这样做是有意义的,因为我们不能一直保证图中的圆会自然落入与图像本身的宽度或高度相同数量的分区。如果dp设置为1,那么分辨率不发生变化,如果设置一个较大的数比如2,累加器的分辨率会减小一半。dp的值不能小于1。
参数minDist是两个圆之间必须存在的最小距离,以便算法可以判断出它们是两个圆。
cv::HOUGH_GRADIENT后面的两个参数param1和param2分别是边阈值和累加器阈值。在内部调用cv::Canny()时,第一个(较高)阈值设置成传入cv::HoughCircles()的param1,第二个(较低)阈值设置成它的一半。参数param2用于阈值化累加器,和cv::HoughLines()的threshold相似。
最后两个参数是可以找到的圆的最小、最大半径,这意味着它们是累加器能够表示的圆的半径。
#include<opencv2/opencv.hpp>
#include<iostream>
#include<math.h>
#include<vector>
using namespace cv;
using namespace std;
using std::cout;
using std::endl;
using std::vector;
void help(char** argv) {
cout << "\nExample 12-1. Using cv::dft() and cv::idft() to accelerate the computation of convolutions"
<< "\nHough Circle detect\nUsage: " << argv[0] << " <path/imagename>\n"
<< "Example:\n" << argv[0] << " ../stuff.jpg\n" << endl;
}
int main(int argc, char** argv) {
help(argv);
if (argc != 2) {
return -1;
}
cv::Mat src, image;
src = cv::imread(argv[1], 1);
if (src.empty()) {
cout << "Cannot load " << argv[1] << endl;
return -1;
}
//将图像从一个颜色空间转换为源图像所在的另一个颜色空间存储在两个平面中。
cv::cvtColor(src, image, cv::COLOR_BGR2GRAY);
cv::GaussianBlur(image, image, cv::Size(5, 5), 0, 0); //使用5*5的窗口进行高斯模糊
vector<cv::Vec3f> circles; //定义一个3维浮点型向量
//进行霍夫圆变换,根据输入对象类型的不同,函数输出的circles也不同,这里因为输入的是一个图像矩阵,
//所以输出是一个CV::F32C3类型的一维数组,数组中放置的是三维向量(三通道),三个通道分别是圆的坐标、半径
cv::HoughCircles(image, circles, cv::HOUGH_GRADIENT, 2, image.cols / 4);
//遍历这个数组中的每一个圆,将其画出来
for (size_t i = 0; i < circles.size(); ++i) {
cv::circle(src,
cv::Point(cvRound(circles[i][0]), cvRound(circles[i][1])), //圆心的坐标
cvRound(circles[i][2]), //圆的半径
cv::Scalar(0, 0, 255), //颜色
2, //轮廓的宽度
cv::LINE_AA);
}
cv::imshow("Hough Circles", src);
cv::waitKey(0);
return 0;
}















 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









