






这几天花时间完成了标记-清除算法、标记-整理算法、标记-复制算法,还算顺利。今天准备动手写G1,整理思路过程中发现G1涉及到的概念相当多而且还难以理解,网上的文章、相关书籍对相关概念的解释相对比较孤立、比较简洁,需要结合很多资料串起来想才能想明白。防止后面忘记,也为了保证G1的顺利完成,码点文字把这点明白记录下来。
JVM的内存结构是由垃圾回收算法决定的。
Region
G1及其后出现的垃圾收集器ZGC、Shenandoah,它们都是基于Region的内存布局形式。它们垃圾收集的目标范围不再是整个新生代(Minor GC)、老年代(Majon GV)、整个堆(Full GC),而是一个一个的Region。因为这样的内存布局,所以G1能做到面向局部收集。
每个Region都可以被标记为E(Eden)、S(Survivor)、O(Old)、H(Humongous),但一个Region同一时刻只能是这四个中的一个。H表示巨型对象,即超过Region大小的一半的对象,会直接进入老年代由多个连续的Region存储。
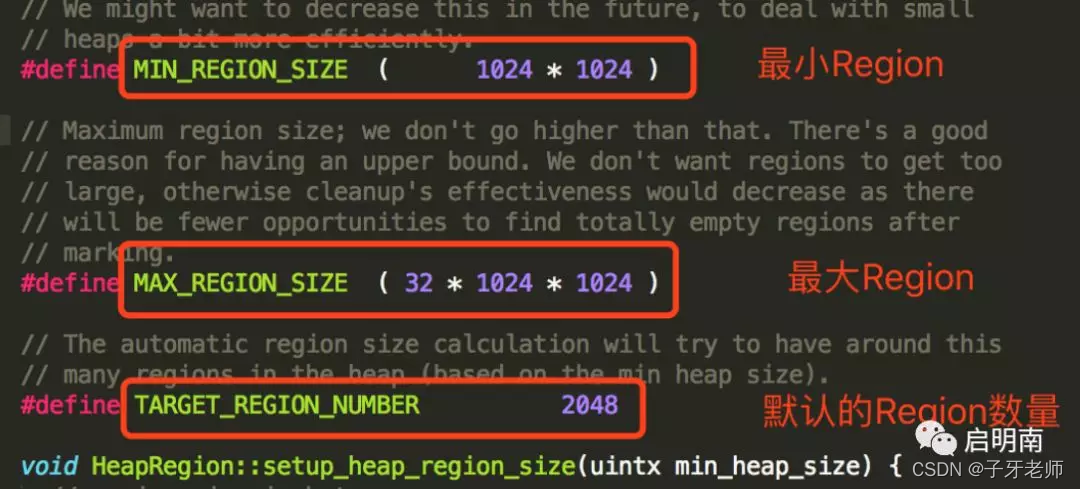
Region的大小可以通过-XX:G1HeapRegionSize参数指定,如果没有显示指定,则G1会计算出一个合理的大小。Region的取值范围为1M~32M,且应为2的N次幂,所以Region的大小只能是1M、2M、4M、8M、16M、32M。比如-Xmx=16g -Xms=16g,则Region的大小等于16G / 2048=8M。也可以推理出G1推荐的管理的最大堆内存是64G。
RSet(Remembered Set、记忆集)
在垃圾收集过程中,会存在一种现象,即跨代引用,在G1中,又叫跨Region引用。如果是年轻代指向老年代的引用我们不用关心,因为即使Minor GC把年轻代的对象清理掉了,程序依然能正常运行,而且随着引用链的断掉,无法被标记到的老年代对象会被后续的Major GC回收。如果是老年代指向年轻代的引用,那这个引用在Minor GC阶段是不能被回收掉的,那如何解决这个问题呢?
最简单的实现方式当然是每个对象中记录这个跨Region引用记录,GC时扫描所有老年代的对象,显然这是一个相当大的Overhead。为什么呢?因为IBM做过这样的实验,发现绝大多数对象都是“朝生夕灭”,等不到进入老年代,能进入老年代的对象最多不到5%。JVM的新生代内存比例是8:1:1也是基于这个结论设定的。
最合理的实现方式自然是记录哪些Region中的老年代的对象有指向年轻代的引用。GC时扫描这些Region就行了。这就是RSet存在的意义。RSet本质上是一种哈希表,Key是Region的起始地址,Value是一个集合,里面存储的元素是卡表的索引号(第几个Card的第几个元素)。
Card Table(卡表)
每个Region又被分成了若干个大小为512字节的Card,这些Card都会记录在全局卡表中。Card中的每个元素对应着其标识的内存区域中一块特定大小的内存块,这个内存块被称为卡页。一个卡页的内存中通常不止一个对象,只有卡页中有一个及以上对象的字段存在着跨Region引用,这个对应的元素的值就标识为1。
比如G1默认的Region有2048个,默认每个Region为2M,那每个Region对应的Card的每个元素对应的卡页的大小为2M / 512=4K,即这4K内存中只要有一个或一个以上的对象存在着跨Region对年轻代的引用,这个卡页对应的Card的元素值为1。
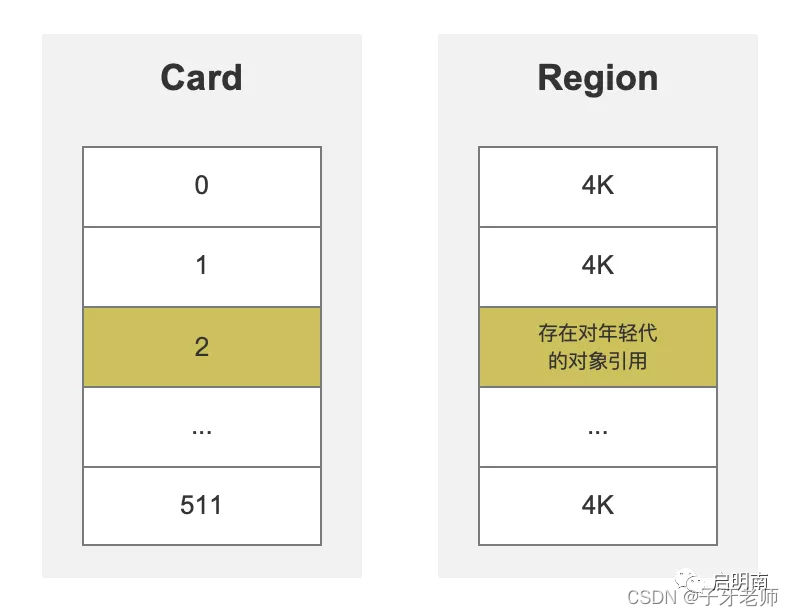
这样在Minor GC时,只需要将变脏的Region中的那个卡页加入GC Roots一并扫描即可。比起扫描老年代的所有对象,大大减少了扫描的数据量,提升了效率。
思路已经理清楚,开始敲代码实现…感觉会很有意思。
结语
我是子牙老师,如果你也喜欢研究底层,喜欢硬核知识,欢迎关注我的公众号:硬核子牙

















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









