







一. 近邻搜索
从这里开始我将会对LSH进行一番长篇大论。因为这只是一篇博文,并不是论文。我觉得一篇好的博文是尽可能让人看懂,它对语言的要求并没有像论文那么严格,因此它可以有更强的表现力。
局部敏感哈希,英文locality-sensetive hashing,常简称为LSH。局部敏感哈希在部分中文文献中也会被称做位置敏感哈希。LSH是一种哈希算法,最早在1998年由Indyk在[1]上提出。不同于我们在数据结构教材中对哈希算法的认识,哈希最开始是为了减少冲突方便快速增删改查,在这里LSH恰恰相反,它利用的正式哈希冲突加速检索,并且效果极其明显。LSH主要运用到高维海量数据的快速近似查找。近似查找便是比较数据点之间的距离或者是相似度。因此,很明显,LSH是向量空间模型下的东西。一切数据都是以点或者说以向量的形式表现出来的。在细说LSH之前必须先提一下K最近邻查找 (kNN,k-Nearest Neighbor)与c最近邻查找 (cNN,c-Nearest Neighbor )。
kNN问题就不多说了,这个大家应该都清楚,在一个点集中寻找距离目标点最近的K个点。我们主要提一下cNN问题。首先给出最近邻查找(NN,Nearest Neighbor)的定义。

定义 1: 给定一拥有 n 个点的点集
这个定义很容易被理解,需要说明的是这个距离是个广义的概念,并没有说一定是欧式距离。随着需求的不同可以是不同的距离度量手段。那么接下来给出cNN问题的定义。
定义 2: 给定一拥有
cNN不同于kNN,cNN和距离的联系更加紧密。LSH本身设计出来是专门针对解决cNN问题,而不是kNN问题,但是很多时候kNN与cNN有着相似的解集。因此LSH也可以运用在kNN问题上。这些问题若使用一一匹配的暴力搜索方式会消耗大量的时间,即使这个时间复杂度是线性的。也许一次两次遍历整个数据集不会消耗很多时间,但是如果是以用户检索访问的形式表现出来可以发现查询的用户多了,每个用户都需要消耗掉一些资源,服务器往往会承受巨大负荷。那么即使是线性的复杂度也是不可以忍受的。早期为了解决这类问题涌现出了许多基于树形结构的搜索方案,如KD树,SR树。但是这些方法只适用于低维数据。自从LSH的出现,高维数据的近似查找便得到了一定的解决。
二. LSH的定义
LSH不像树形结构的方法可以得到精确的结果,LSH所得到的是一个近似的结果,因为在很多领域中并不需非常高的精确度。即使是近似解,但有时候这个近似程度几乎和精准解一致。
LSH的主要思想是,高维空间的两点若距离很近,那么设计一种哈希函数对这两点进行哈希值计算,使得他们哈希值有很大的概率是一样的。同时若两点之间的距离较远,他们哈希值相同的概率会很小。给出LSH的定义如下:
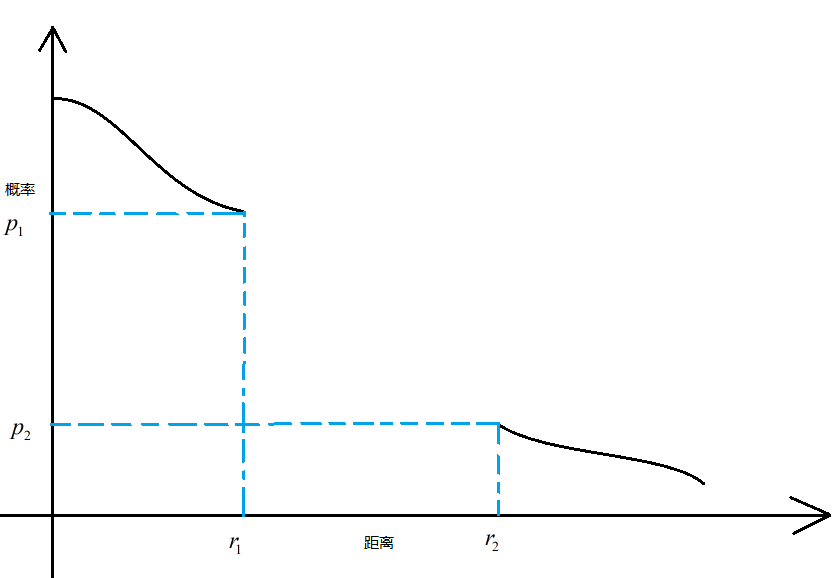
定义 3: 给定一族哈希函数
若 p∈B(q,r1) 则 PrH[h(q)=h(p)]≥p1
若 p∉B(q,r2) 则 PrH[h(q)=h(p)]≤p2
定义3中 B 表示的是以
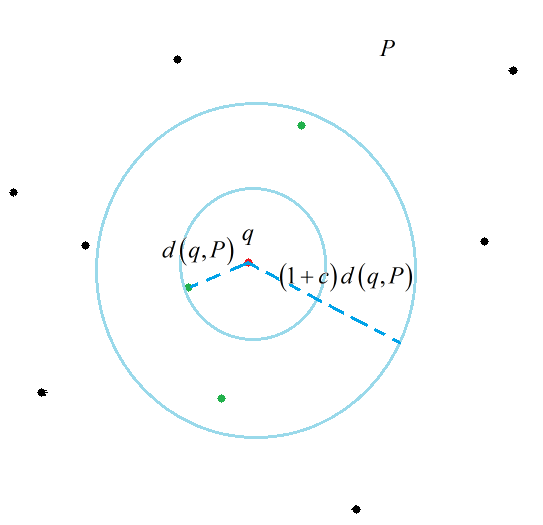
我绘制了一幅图来说明一下这个定义。
可以看出这个定义其实是更关注 p∈B(q,r1) 与 p∉B(q,r2) 两个部分的概率。从定义的角度上并没有说概率随着距离的变化一定要单调。但事实上目前所有的LSH哈希函数都是单调的。这也是我困惑的一点。
三. 曼哈顿距离转换成汉明距离
从理论讲解的逻辑顺序上来说,现在还没到非要讲具体哈希函数的时候,但是为了方便理解,必须要举一个实例来讲解会好一些。那么就以曼哈顿距离下(其实用的是汉明距离的特性)的LSH哈希函数族作为一个参考的例子讲解。
曼哈顿距离又称 L1 范数距离。其具体定义如下:
定义 4: 在 n 维欧式空间
其实曼哈顿距离我们应该并不陌生。他与欧式距离( L2 范数距离)的差别就像直角三角形两边之和与斜边的差别。文[2]介绍了具体如何构造曼哈顿距离LSH哈希函数的过程。其实在这篇论文发表的时候欧式距离的哈希函数还没有被探究出来,原本LSH的设计其实是想解决欧式距离度量下的近似搜索。所以当时这个事情搞得就很尴尬,然后我们的大牛Indyk等人就强行解释,大致意思是:不要在意这些细节,曼哈顿和欧式距离差不多。他在文[2]中提出了两个关键的问题。
1.使用 L1 范数距离进行度量。
2.所有坐标全部被正整数化。
对于第一条他解释说 L1 范数距离与 L2 范数距离在进行近似查找时得到的结果非常相似。对于第二条,整数化是为了方便进行01编码。
对数据集 P 所有的点,令
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









