







1、前言
ChatTTS-Forge 是一款基于先进的 ChatTTS 模型开发的语音合成项目。它不仅提供了一个强大的 API 服务器,还配备了直观易用的 Gradio Web 用户界面 (WebUI),使得无论是开发者还是非技术用户都能轻松地利用 ChatTTS-Forge 进行高质量的语音合成。本文将详细介绍如何快速地实现私有化部署。
主要特性
1、多平台支持:提供在线体验、一键启动、容器部署和本地部署等多种使用方式。
2、强大的 WebUI 功能:支持 ChatTTS 模型原生的 Refiner/Generate 功能
- 原生 Batch 合成,高效处理超长文本;
- 风格化控制;
- SSML 支持,包括编辑器、分割器和播客脚本创建;
- 丰富的说话人(Speaker)功能,内置众多 speaker 可以使用;
- Prompt Slot 和文本标准化;
- 音质增强和降噪提高输出质量;
- 实验性功能如微调和 ASR;
3、API 服务器:提供独立的 API 服务,方便与其他应用集成。
4、灵活的 GPU 资源利用:根据不同的配置和需求,可以在不同规格的 GPU 上运行。
5、多角色多情感合成:支持在一段文本中实现多个角色和情感的切换。
6、长文本生成:能够处理并生成长篇幅的语音内容
2、安装依赖项
2.1 下载仓库代码
执行以下命令将本仓库代码克隆到本地:
git clone https://github.com/lenML/ChatTTS-Forge.git --depth=1
2.2 下载后处理工具链
音频后处理操作(如加速、减速、提高音量等)依赖以下库:ffmpeg 或 libav(推荐使用 ffmpeg)
脚本安装
执行此脚本即可自动安装后音频后端
python -m scripts.download_audio_backend
手动安装
若安装脚本失效,可参考下面的指南自行手动安装(Windows)
若你已经安装有 ffmpeg,并可以在命令行中调用,那么无需进行下面的下载和安装
- 下载 ffmpeg
- 从此处下载并解压 ffmpeg 的 Windows 二进制文件;
- 将 ffmpeg 的/bin文件夹中的 .exe 文件解压到 项目目录/ffmpeg 文件夹内
- 下载 rubberband
- 从此处下载并解压 rubberband 的 Windows 二进制文件;
- 将 压缩包中 rubberband-3.3.0-gpl-executable-windows 文件夹下的 .exe/.dll 文件解压到 项目目录/ffmpeg 文件夹内
文件 (window) 目录应该如下
./ffmpeg
├── ffmpeg.exe
├── ffprobe.exe
├── ffplay.exe
├── ffplay.exe
├── rubberband.exe
├── rubberband-r3.exe
├── sndfile.dll
└── put_ffmpeg_here
2.3 安装Python依赖
2.3.1 pytorch
由于 pytroch 安装与你的本机环境有关,请自行安装对应版本,下面是一个简单的安装脚本
(如果直接运行某些情况可能会安装 cpu 版本,具体应该指定什么版本请自行确定)
# conda 安装
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
# pip 安装
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 -f https://mirror.sjtu.edu.cn/pytorch-wheels/torch_stable.html
如果上面无法安装 cuda 版本,可以参考下面的指令安装指定版本 torch
pip3 install https://mirror.sjtu.edu.cn/pytorch-wheels/cu121/torch-2.3.1%2Bcu121-cp310-cp310-linux_x86_64.whl
pip3 install https://mirror.sjtu.edu.cn/pytorch-wheels/cu121/torchaudio-2.3.1%2Bcu121-cp310-cp310-linux_x86_64.whl
pip3 install https://mirror.sjtu.edu.cn/pytorch-wheels/cu121/torchvision-0.18.1%2Bcu121-cp310-cp310-linux_x86_64.whl
验证torch的版本
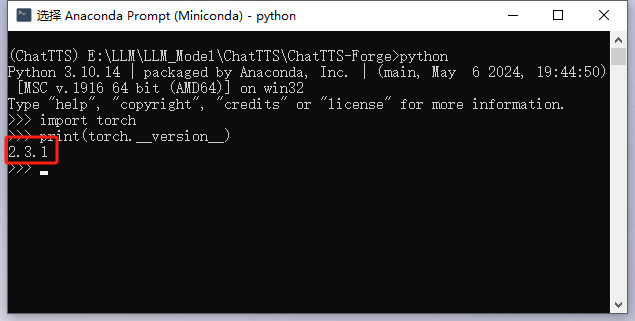
2.3.2 lash attn (可选)
详见: https://github.com/Dao-AILab/flash-attention
2.3.3 其余依赖
注意:
源码中有4个版本的requirements文件,其中的依赖项有所不同,按需安装。
requirements文件中不能有中文,注释中也不能有。
requirements文件中可能还缺少某些库,如modelscope等,可以先添加进去再安装,也可以后面遇到了再pip安装。
安装指令1:
pip install -r requirements.txt
报错:找不到指定的版本
:::tips
ERROR: Could not find a version that satisfies the requirement numpy1.26.4 (from versions: none)
ERROR: No matching distribution found for numpy1.26.4
:::
安装指令2:
pip install -r requirements.txt -i [https://pypi.tuna.tsinghua.edu.cn/simple](https://pypi.tuna.tsinghua.edu.cn/simple)
报错:不能从清华镜像源中找到 lightning依赖包
:::tips
ERROR: HTTP error 404 while getting https://pypi.tuna.tsinghua.edu.cn/packages/a3/2c/85eaf42c983b0cd81bcda5876da2c8e2a9fd347908666ea9855724369171/lightning-2.4.0-py3-none-any.whl (from https://pypi.tuna.tsinghua.edu.cn/simple/lightning/)) (requires-python:>=3.9)
ERROR: Could not install requirement lightning from https://pypi.tuna.tsinghua.edu.cn/packages/a3/2c/85eaf42c983b0cd81bcda5876da2c8e2a9fd347908666ea9855724369171/lightning-2.4.0-py3-none-any.whl (from -r requirements.txt (line 43)) because of HTTP error 404 Client Error: Not Found for url: https://pypi.tuna.tsinghua.edu.cn/packages/a3/2c/85eaf42c983b0cd81bcda5876da2c8e2a9fd347908666ea9855724369171/lightning-2.4.0-py3-none-any.whl for URL https://pypi.tuna.tsinghua.edu.cn/packages/a3/2c/85eaf42c983b0cd81bcda5876da2c8e2a9fd347908666ea9855724369171/lightning-2.4.0-py3-none-any.whl (from https://pypi.tuna.tsinghua.edu.cn/simple/lightning/)) (requires-python:>=3.9)
:::
安装指令3:
pip install -r requirements.txt -i [https://mirrors.aliyun.com/pypi/simple/](https://mirrors.aliyun.com/pypi/simple/)
下载速度比清华源慢很多,速度稳定在200+kB/s,但是胜在安装过程丝滑。
2.4 下载模型文件
- 从 HuggingFace 下载:
python -m scripts.download_models --source huggingface
没有科学上网,此路难行!!!
- 从 ModelScope 下载:
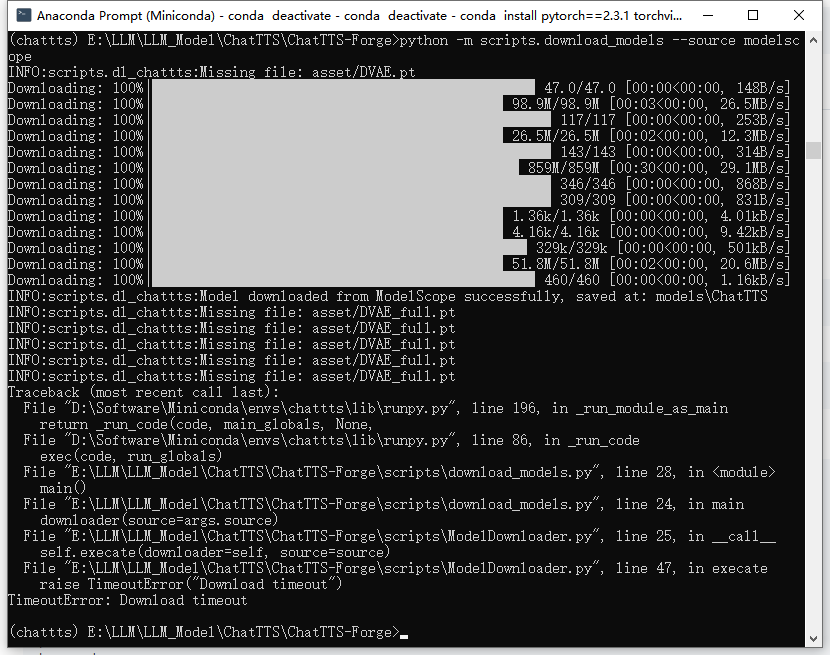
python -m scripts.download_models --source modelscope
报错下载超时,并提示:
INFO:scripts.dl_chattts:Missing file: asset/DVAE.pt
INFO:scripts.dl_chattts:Missing file: asset/DVAE_full.pt
重新执行上面的指令下载,若不能下载成功,这里我为大家提供百度网盘下载
安装完成之后 models 文件夹应该如下:
./models
├── ChatTTS
│ ├── asset
│ │ ├── DVAE.pt
│ │ ├── DVAE_full.pt
│ │ ├── Decoder.pt
│ │ ├── GPT.pt
│ │ ├── Vocos.pt
│ │ ├── spk_stat.pt
│ │ └── tokenizer.pt
│ └── config
│ ├── decoder.yaml
│ ├── dvae.yaml
│ ├── gpt.yaml
│ ├── path.yaml
│ └── vocos.yaml
├── put_model_here
└── resemble-enhance
├── hparams.yaml
└── mp_rank_00_model_states.pt
3、 启动服务
根据需求启动服务:
- webui:
python webui.py - api:
python launch.py
启动后会自动打开如下web界面,现在就可以尝试ChatTTS Forge的强大功能了。
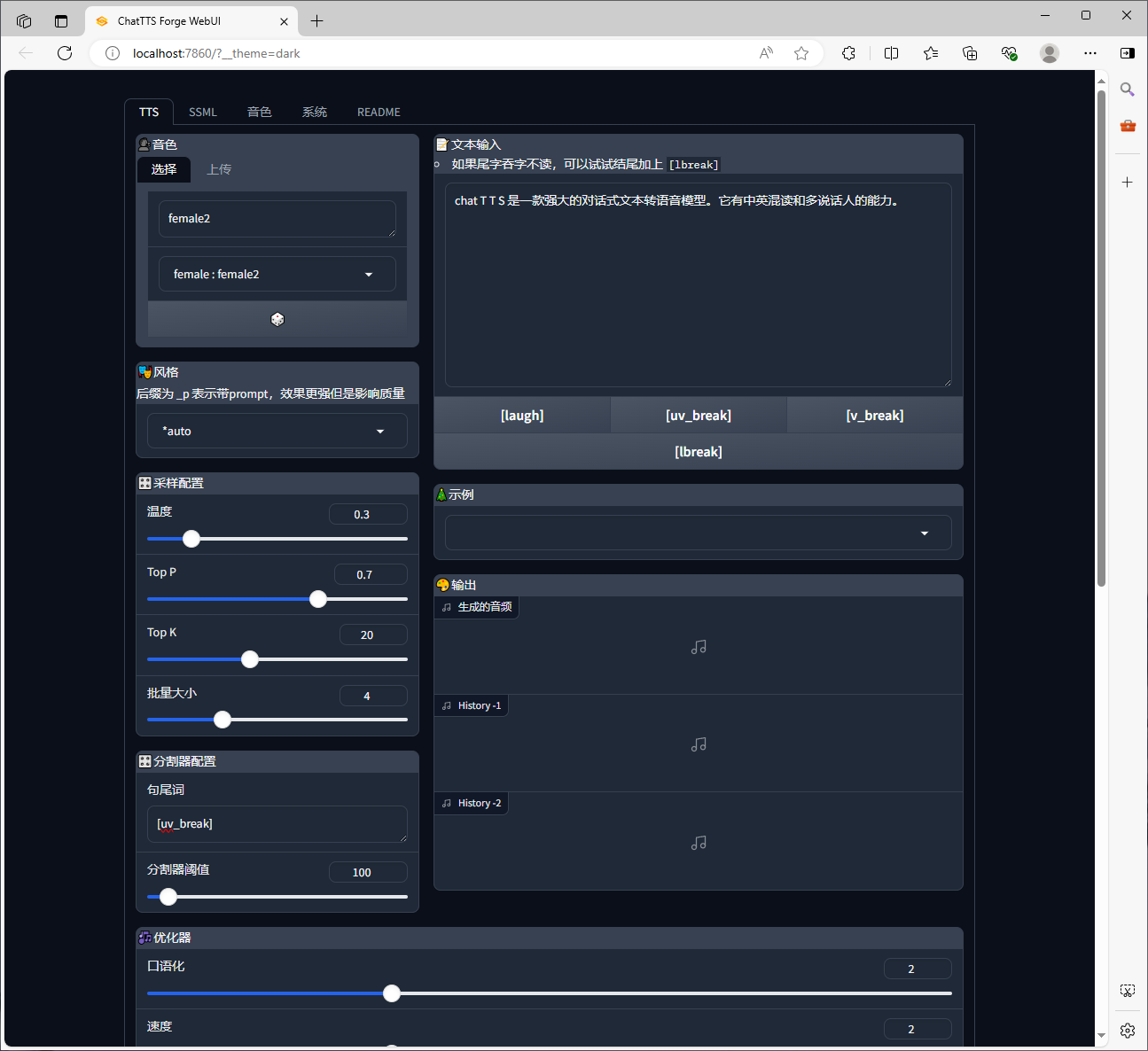
4、参数说明
4.1 启动服务参数
WebUI.py 是一个用于配置和启动 Gradio Web UI 界面的脚本。以下参数有一套默认值,如要自己修改,切记在启动服务之前修改,或直接在启动命令行中加入设置值。
| 选项 | 描述 |
|---|---|
-h, --help | 显示帮助信息并退出。 |
--server_name SERVER_NAME | 服务器名称。 |
--server_port SERVER_PORT | 服务器端口。 |
--share | 共享 Gradio 界面。 |
--debug | 启用调试模式。 |
--auth AUTH | 用户名和密码进行身份验证。格式为 username:password。 |
--tts_max_len TTS_MAX_LEN | 文本转语音(TTS)的最大文本长度。 |
--ssml_max_len SSML_MAX_LEN | SSML(语音合成标记语言)的最大文本长度。 |
--max_batch_size MAX_BATCH_SIZE | TTS 的最大批次大小。 |
--webui_experimental | 启用实验性 WebUI 功能。 |
--language LANGUAGE | 设置 WebUI 的默认语言。 |
--api | 使用 api=True与 WebUI 一起启动 API,或者单独运行 API 服务器。 |
--compile | 启用模型编译。 |
--no_half | 禁用模型推理中的半精度计算。 |
--off_tqdm | 禁用 tqdm 进度条。 |
--device_id DEVICE_ID | 选择默认的 CUDA 设备。可能需要设置环境变量 CUDA_VISIBLE_DEVICES。 |
--use_cpu {all,chattts,enhancer} | 指定模块使用 CPU 作为 torch 设备。可选值为 all, chattts, enhancer。 |
--lru_size LRU_SIZE | 设置请求缓存池的大小,设置为 0 将禁用缓存。 |
--debug_generate | 启用音频生成的调试模式。 |
--preload_models | 在启动时预加载所有模型。 |
--cors_origin CORS_ORIGIN | 允许的 CORS 原点。使用 * |
| 表示允许所有原点。 | |
--no_playground | 禁用 Playground 入口。 |
--no_docs | 禁用文档入口。 |
--exclude EXCLUDE | 从服务器中排除指定的 API。 |
- 所有参数均可在 .env.webui 中以大写形式配置 (比如 no_docs => NO_DOCS)
- 在命令行之后的参数优先级高于 .env 参数
- 从 webui.py 入口启动, 可与 api 同时启动,api 的配置在下方 launch.py 脚本参数中说明, 开启后可在
http://localhost:7860/docs查看 api - 由于
MKL FFT doesn't support tensors of type: Half所以--use_cpu="all"时需要开启--no_half
4.2 TTS参数
页面提供了一个强大的对话式文本转语音(TTS)模型接口,支持中英文混读和多说话人能力。用户可以通过调节各种参数生成高质量的语音输出。以下参数可以在页面中修改,修改后直接生效,不用重启服务。
下面是根据提供的信息整理的一个表格,概括了各个参数设置及其功能说明:
| 参数名称 | 范围/选项 | 默认值 | 功能描述 |
|---|---|---|---|
| 温度 (Temperature) | 0.01 - 2.0 | 0.3 | 模型生成内容的随机性。温度越低,生成的结果越倾向于最可能的选择;温度越高,生成的结果越随机。 |
| Top P | 0.1 - 1.0 | 0.7 | 生成内容时采用的核采样阈值。Top P 核采样会考虑概率总和达到指定 P 值的词汇集合。 |
| Top K | 1 - 50 | 20 | 在生成内容时考虑的最高概率词汇的数量。Top K 采样会在最高的 K 个概率词汇中随机选择下一个词汇。 |
| 批处理大小 (Batch Size) | 1 - 最大批处理大小 | 4 | 同时处理的样本数量。较大的批处理大小可以提高效率,但可能需要更多的内存。 |
| 样式 (Style) | 预设样式 | *auto | 从下拉菜单中选择预设样式。默认为自动选择。 |
| 说话人 | 预设说话人或自定义名称/种子 | N/A | 从下拉菜单中选择预设说话人,或手动输入说话人名称或种子。也可以通过上传文件来定制说话人。 |
| 推理种子 (Inference Seed) | 手动输入或随机生成 | N/A | 设置用于语音生成的随机种子,确保生成的一致性。可以手动输入或点击按钮随机生成。 |
| Prompt 1 | 自由文本输入 | N/A | 输入用于生成音频的第一部分提示。 |
| Prompt 2 | 自由文本输入 | N/A | 输入用于生成音频的第二部分提示。 |
| 前缀 (Prefix) | 自由文本输入 | N/A | 输入用于引导生成音频的前缀。 |
| 音频提示 | 文件上传 | N/A | 如果启用了实验性功能,可以通过上传音频文件来作为提示。 |
| 文本输入 | 自由文本输入 | N/A | 输入需要转换为语音的文本。需要注意字数限制和英文文本的特殊标记。 |
| 示例文本 | 从下拉菜单中选择 | N/A | 从预设的示例文本中选择一项来快速填充文本输入框。 |
| 生成音频 | 按钮 | N/A | 点击此按钮以生成语音输出。可以启用增强 (Enhance) 和去噪 (De-noise) 功能。 |
| 优化提示 (Refine Prompt) | 自由文本输入 | N/A | 输入用于优化原始文本的提示。 |
| 优化文本 | 按钮 | N/A | 点击此按钮以优化文本,可能会修正语法错误、调整语气等。 |
请注意,表格中的某些字段如“范围/选项”和“默认值”对于非数值型的设置没有固定值,因此标注为“N/A”。此外,“功能描述”列提供了每个设置的简要说明。
4.3 styles参数
文件 ./data/styles.csv 中包含所有风格,下面是具体的设定
风格名带有
_p结尾的是注入上下文的风格,可能导致质量下降但是控制更强一点
| 风格 | 说明 |
|---|---|
| advertisement_upbeat | 用兴奋和精力充沛的语气推广产品或服务。 |
| affectionate | 以较高的音调和音量表达温暖而亲切的语气。说话者处于吸引听众注意力的状态。说话者的个性往往是讨喜的。 |
| angry | 表达生气和厌恶的语气。 |
| assistant | 数字助理用的是热情而轻松的语气。 |
| calm | 以沉着冷静的态度说话。语气、音调和韵律与其他语音类型相比要统一得多。 |
| chat | 表达轻松随意的语气。 |
| cheerful | 表达积极愉快的语气。 |
| customerservice | 以友好热情的语气为客户提供支持。 |
| depressed | 调低音调和音量来表达忧郁、沮丧的语气。 |
| disgruntled | 表达轻蔑和抱怨的语气。这种情绪的语音表现出不悦和蔑视。 |
| documentary-narration | 用一种轻松、感兴趣和信息丰富的风格讲述纪录片,适合配音纪录片、专家评论和类似内容。 |
| embarrassed | 在说话者感到不舒适时表达不确定、犹豫的语气。 |
| empathetic | 表达关心和理解。 |
| envious | 当你渴望别人拥有的东西时,表达一种钦佩的语气。 |
| excited | 表达乐观和充满希望的语气。似乎发生了一些美好的事情,说话人对此满意。 |
| fearful | 以较高的音调、较高的音量和较快的语速来表达恐惧、紧张的语气。说话人处于紧张和不安的状态。 |
| friendly | 表达一种愉快、怡人且温暖的语气。听起来很真诚且满怀关切。 |
| gentle | 以较低的音调和音量表达温和、礼貌和愉快的语气。 |
| hopeful | 表达一种温暖且渴望的语气。听起来像是会有好事发生在说话人身上。 |
| lyrical | 以优美又带感伤的方式表达情感。 |
| narration-professional | 以专业、客观的语气朗读内容。 |
| narration-relaxed | 为内容阅读表达一种舒缓而悦耳的语气。 |
| newscast | 以正式专业的语气叙述新闻。 |
| newscast-casual | 以通用、随意的语气发布一般新闻。 |
| newscast-formal | 以正式、自信和权威的语气发布新闻。 |
| poetry-reading | 在读诗时表达出带情感和节奏的语气。 |
| sad | 表达悲伤语气。 |
| serious | 表达严肃和命令的语气。说话者的声音通常比较僵硬,节奏也不那么轻松。 |
| shouting | 表达一种听起来好像声音在远处或在另一个地方的语气,努力让别人听清楚。 |
| sports_commentary | 表达一种既轻松又感兴趣的语气,用于播报体育赛事。 |
| sports_commentary_excited | 用快速且充满活力的语气播报体育赛事精彩瞬间。 |
| whispering | 表达一种柔和的语气,试图发出安静而柔和的声音。 |
| terrified | 表达一种害怕的语气,语速快且声音颤抖。听起来说话人处于不稳定的疯狂状态。 |
| unfriendly | 表达一种冷淡无情的语气。 |
参考
[1]:https://github.com/lenML/ChatTTS-Forge/blob/main/docs/dependencies.md
















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











