






目录
说明:本内容为个人自用学习笔记,整理自b站西湖大学赵世钰老师的 【强化学习的数学原理】课程,特别感谢老师分享讲解如此清楚的课程。
一个概念(state value)+ 一个工具(the bellman equation)
1. return 的重要性
- return could be used to evaluate policies
- return 的计算,bootstrapping:从自己出发迭代计算(bellman equation)
2. state value
- signal-step process
S t ⟶ A t R t + 1 , S t + 1 S_t \overset{A_t}{\longrightarrow} R_{t+1}, S_{t+1} St⟶AtRt+1,St+1
在 t t t 时刻处于状态 S t S_t St,采取行动 A t A_t At 跳转到状态 S t + 1 S_{t+1} St+1,得到的收益为 R t + 1 R_{t+1} Rt+1,有时也记作 R t R_{t} Rt,含义相同,只是习惯问题。

-
multi-step trajectory
S t ⟶ A t R t + 1 , S t + 1 ⟶ A t + 1 R t + 2 , S t + 2 ⟶ A t + 2 R t + 3 , S t + 3 ⋯ S_t \overset{A_t}{\longrightarrow} R_{t+1}, S_{t+1}\overset{A_{t+1}}{\longrightarrow} R_{t+2}, S_{t+2}\overset{A_{t+2}}{\longrightarrow} R_{t+3}, S_{t+3} \cdots St⟶AtRt+1,St+1⟶At+1Rt+2,St+2⟶At+2Rt+3,St+3⋯
discounted return( G t G_t Gt 是随机变量):
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ G_t = R_{t+1}+\gamma R_{t+2} +\gamma ^2 R_{t+3}+\cdots Gt=Rt+1+γRt+2+γ2Rt+3+⋯ -
G t G_t Gt 的期望被定义为 state-value function,简称为 state value
v π ( s ) = E [ G t ∣ S t = s ] v_\pi (s) = \mathbb{E} [G_t|S_t=s] vπ(s)=E[Gt∣St=s]- 关于s的函数
- 基于策略 π \pi π的函数, v ( π , s ) v(\pi, s) v(π,s)记为 v π ( s ) v_\pi (s) vπ(s)
- v π ( s ) v_\pi (s) vπ(s) 越大,代表策略越好!
-
return 和 state value 的区别
- return 针对单个 trajectory,state value 针对多个 trajectory 求平均。
- 当 π ( a ∣ s ) , p ( r ∣ s , a ) , p ( s ′ ∣ s , a ) \pi(a|s), p(r|s, a), p(s'|s, a) π(a∣s),p(r∣s,a),p(s′∣s,a) 是确定的时候,return = state value
3. bellman equation
Bellman equation 描述了所有的values和state之间的关系!
3.1 Bellman equation 的推导
对于一个随机的trajectory,
S
t
⟶
A
t
R
t
+
1
,
S
t
+
1
⟶
A
t
+
1
R
t
+
2
,
S
t
+
2
⟶
A
t
+
2
R
t
+
3
,
S
t
+
3
⋯
S_t \overset{A_t}{\longrightarrow} R_{t+1}, S_{t+1}\overset{A_{t+1}}{\longrightarrow} R_{t+2}, S_{t+2}\overset{A_{t+2}}{\longrightarrow} R_{t+3}, S_{t+3} \cdots
St⟶AtRt+1,St+1⟶At+1Rt+2,St+2⟶At+2Rt+3,St+3⋯
return
G
t
G_t
Gt
G
t
=
R
t
+
1
+
γ
R
t
+
2
+
γ
2
R
t
+
3
+
⋯
=
R
t
+
1
+
γ
G
t
+
1
G_t = R_{t+1}+\gamma R_{t+2} +\gamma ^2 R_{t+3}+\cdots=R_{t+1}+\gamma G_{t+1}
Gt=Rt+1+γRt+2+γ2Rt+3+⋯=Rt+1+γGt+1
so
v
π
(
s
)
=
E
[
G
t
∣
S
t
=
s
]
=
E
[
R
t
+
1
+
γ
G
t
+
1
∣
S
t
=
s
]
=
E
[
R
t
+
1
∣
S
t
=
s
]
+
γ
E
[
G
t
+
1
∣
S
t
=
s
]
\begin{aligned} v_\pi (s)&= \mathbb{E} [G_t|S_t=s] \\ &= \mathbb{E} [R_{t+1}+\gamma G_{t+1}|S_t=s] \\ &= \mathbb{E} [R_{t+1}|S_t=s] + \gamma \mathbb{E} [G_{t+1}|S_t=s]\\ \end{aligned}
vπ(s)=E[Gt∣St=s]=E[Rt+1+γGt+1∣St=s]=E[Rt+1∣St=s]+γE[Gt+1∣St=s]
分别计算上述两项,有,
-
E [ R t + 1 ∣ S t = s ] \mathbb{E} [R_{t+1}|S_t=s] E[Rt+1∣St=s]
E [ R t + 1 ∣ S t = s ] = ∑ a π ( a ∣ s ) E [ R t + 1 ∣ S t = s , A t = a ] = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r \begin{aligned} \mathbb{E} [R_{t+1}|S_t=s] &= \sum\limits_{a} \pi(a|s)\mathbb{E}[R_{t+1}|S_t=s, A_t=a] \\ & = \sum\limits_{a} \pi(a|s) \sum\limits_{r} p(r|s, a)r \end{aligned} E[Rt+1∣St=s]=a∑π(a∣s)E[Rt+1∣St=s,At=a]=a∑π(a∣s)r∑p(r∣s,a)r- 在状态s可以采取多个action,采取 a 的概率为 π ( a ∣ s ) \pi(a|s) π(a∣s),获得的value为 E [ R t + 1 ∣ S t = s , A t = a ] \mathbb{E}[R_{t+1}|S_t=s, A_t=a] E[Rt+1∣St=s,At=a],从状态s出发采取action a获得的 return 为 p ( r ∣ s , a ) r p(r|s, a)r p(r∣s,a)r
- This is the mean of immediate rewards
-
E [ G t + 1 ∣ S t = s ] \mathbb{E} [G_{t+1}|S_t=s] E[Gt+1∣St=s]
E [ G t + 1 ∣ S t = s ] = ∑ s ′ E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ E [ G t + 1 ∣ S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) ∑ a p ( s ′ ∣ s , a ) π ( a ∣ s ) \begin{aligned} \mathbb{E} [G_{t+1}|S_t=s] &= \sum\limits_{s'}\mathbb{E}[G_{t+1}|S_t = s, S_{t+1}=s']p(s'|s)\\ &=\sum\limits_{s'}\mathbb{E}[G_{t+1}|S_{t+1}=s']p(s'|s)\\ &=\sum\limits_{s'} v_\pi (s')p(s'|s)\\ &=\sum\limits_{s'} v_\pi (s') \sum\limits_{a} p(s'|s,a)\pi (a|s) \end{aligned} E[Gt+1∣St=s]=s′∑E[Gt+1∣St=s,St+1=s′]p(s′∣s)=s′∑E[Gt+1∣St+1=s′]p(s′∣s)=s′∑vπ(s′)p(s′∣s)=s′∑vπ(s′)a∑p(s′∣s,a)π(a∣s)- 从状态 s 出发得到的下一时刻 return 的mean,也就是future rewards
- E [ G t + 1 ∣ S t + 1 = s ′ ] \mathbb{E}[G_{t+1}|S_{t+1}=s'] E[Gt+1∣St+1=s′] 去掉 S t = s S_t =s St=s是因为已经知道下一时刻的状态是s’,用到了Markov 属性,得到的值为state value
- 从s到s’同样有多种action,采取action a的概率为 π ( a ∣ s ) \pi(a|s) π(a∣s),选择该action从s跳到s’的概率为 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a)
因此,得到 bellman equation
v
π
(
s
)
=
E
[
R
t
+
1
∣
S
t
=
s
]
+
γ
E
[
G
t
+
1
∣
S
t
=
s
]
=
∑
a
π
(
a
∣
s
)
∑
r
p
(
r
∣
s
,
a
)
r
⏟
m
e
a
n
o
f
i
m
m
e
d
i
a
t
e
r
e
w
a
r
d
s
+
γ
∑
s
′
v
π
(
s
′
)
∑
a
p
(
s
′
∣
s
,
a
)
π
(
a
∣
s
)
⏟
m
e
a
n
o
f
f
u
t
u
r
e
r
e
w
a
r
d
s
=
∑
a
π
(
a
∣
s
)
(
∑
r
p
(
r
∣
s
,
a
)
r
+
γ
∑
s
′
p
(
s
′
∣
s
,
a
)
v
π
(
s
′
)
)
,
∀
s
∈
S
.
\begin{aligned} v_\pi (s) &= \mathbb{E} [R_{t+1}|S_t=s] + \gamma \mathbb{E} [G_{t+1}|S_t=s]\\ &=\underbrace{ \sum\limits_{a} \pi(a|s) \sum\limits_{r} p(r|s, a)r }_{mean\,of\,immediate\,rewards} + \underbrace{ \gamma \sum\limits_{s'} v_\pi (s') \sum\limits_{a} p(s'|s,a)\pi (a|s)}_{mean\,of\,future\,rewards}\\ & = \sum\limits_{a} \pi(a|s) \left( \sum\limits_{r} p(r|s, a)r + \gamma \sum\limits_{s'} p(s'|s,a) v_\pi (s') \right), \quad \forall s \in S. \end{aligned}
vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s]=meanofimmediaterewards
a∑π(a∣s)r∑p(r∣s,a)r+meanoffuturerewards
γs′∑vπ(s′)a∑p(s′∣s,a)π(a∣s)=a∑π(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)),∀s∈S.
- 描述了不同 state 的 state-value 之间的关系;
- 包含 immediate 和 future 两部分
- 是方程组,每个 state 都有一个方程。
- π ( a ∣ s ) \pi (a|s) π(a∣s) 是给定的策略,求解方程组叫做 policy evaluation
- p ( r ∣ s , a ) p(r|s,a) p(r∣s,a) 和 p ( s ′ ∣ s , a ) p(s'|s,a) p(s′∣s,a) is dynamic model,存在可知和不可知两种情况!
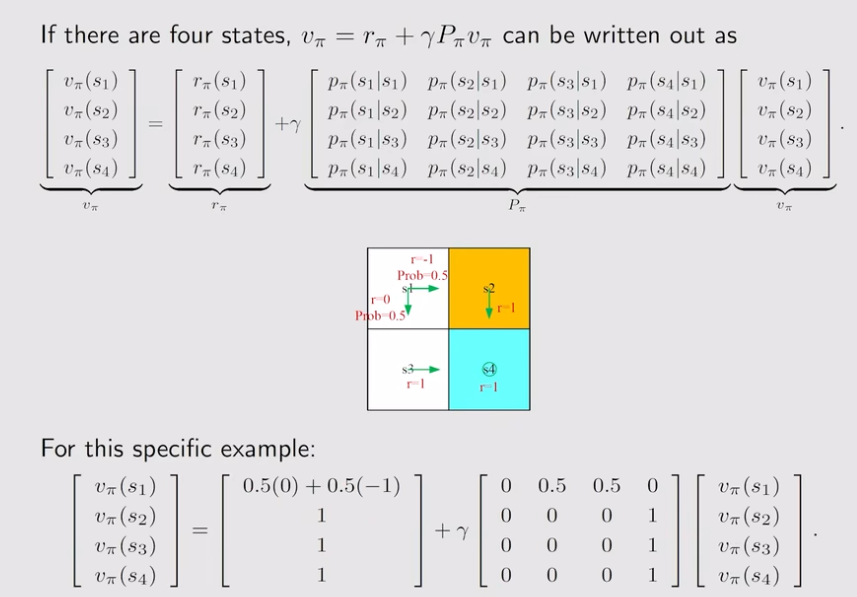
一个例子

直观上不用贝尔曼公式也可以直接写出上述结果!
计算出 state values 之后通过该值可以改进策略,最终得到最优策略。
3.2 Matrix-vector form of the Bellman Equation
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ v π ( s ′ ) ∑ a p ( s ′ ∣ s , a ) π ( a ∣ s ) = d e f r π ( s ) + γ ∑ s ′ p ( s ′ ∣ s ) v π ( s ′ ) \begin{aligned} v_\pi (s) &= \mathbb{E} [R_{t+1}|S_t=s] + \gamma \mathbb{E} [G_{t+1}|S_t=s]\\ &=\sum\limits_{a} \pi(a|s) \sum\limits_{r} p(r|s, a)r + \gamma \sum\limits_{s'} v_\pi (s') \sum\limits_{a} p(s'|s,a)\pi (a|s) \\ &\xlongequal{def}r_{\pi}(s)+\gamma \sum\limits_{s'} p(s'|s) v_\pi (s') \end{aligned} vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s]=a∑π(a∣s)r∑p(r∣s,a)r+γs′∑vπ(s′)a∑p(s′∣s,a)π(a∣s)defrπ(s)+γs′∑p(s′∣s)vπ(s′)
对于
∀
s
i
∈
S
\forall s_{i} \in S
∀si∈S ,
v
π
(
s
i
)
=
r
π
(
s
i
)
+
γ
∑
s
j
p
(
s
j
∣
s
i
)
v
π
(
s
j
)
v_{\pi}(s_i)= r_{\pi}(s_i)+\gamma \sum\limits_{s_j} p(s_j|s_i) v_\pi (s_j)
vπ(si)=rπ(si)+γsj∑p(sj∣si)vπ(sj)
Matrix-vector form
v
π
=
r
π
+
γ
P
π
v
π
v_{\pi} = r_{\pi} + \gamma P_{\pi}v_{\pi}
vπ=rπ+γPπvπ
其中,
v
π
∈
R
n
,
r
π
∈
R
n
,
P
π
∈
R
n
×
n
,
[
P
π
]
i
j
=
p
π
(
s
j
∣
s
i
)
v_{\pi} \in R^n,\quad r_{\pi} \in R^n, \quad P_{\pi} \in R^{n \times n} ,\quad [P_{\pi}]_{ij} = p_{\pi}(s_j|s_i)
vπ∈Rn,rπ∈Rn,Pπ∈Rn×n,[Pπ]ij=pπ(sj∣si)
3.3 利用 Bellman Equation 求解 State values
给定一个策略,求解出对应的 state values 叫做 policy evaluation,这是找出更优策略的基础。
方法一:涉及到矩阵求逆,计算复杂,不使用。
v
π
=
(
I
−
γ
P
π
)
−
1
r
π
v_{\pi} = (I-\gamma P_{\pi})^{-1}r_{\pi}
vπ=(I−γPπ)−1rπ
方法二:利用迭代策略解决
v
k
+
1
=
r
π
+
γ
P
π
v
k
v_{k+1} = r_{\pi} + \gamma P_{\pi} v_{k}
vk+1=rπ+γPπvk
随机给定初值,从
v
0
v_0
v0 开始不断迭代,可以证明,当 $k \rightarrow \infty $ 时,$ v_{k}$ 就会收敛到
v
π
v_{\pi}
vπ

4. Action value
State value: 从一个状态出发,agent得到的average return。
Action value: 从一个状态出发,采取一个action得到的average return。
关注action value 的目的在于评估action的好坏。action value 值越大,说明该采取action越好。
定义:
q
π
(
s
,
a
)
=
E
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
q_{\pi}(s, a) = \mathbb{E}[G_t|S_t=s,A_t= a]
qπ(s,a)=E[Gt∣St=s,At=a]
- q π ( s , a ) q_{\pi}(s, a) qπ(s,a) 是关于 s , a s, a s,a 的函数
- q π ( s , a ) q_{\pi}(s, a) qπ(s,a) 基于策略 π \pi π
Action value 和 State value 在数学表达式之联系:
v
π
(
s
)
=
E
[
G
t
∣
S
t
=
s
]
=
∑
a
E
[
G
t
∣
S
t
=
s
,
A
t
=
a
]
=
∑
a
q
π
(
s
,
a
)
π
(
a
∣
s
)
=
∑
a
[
∑
r
p
(
r
∣
s
,
a
)
r
+
γ
∑
s
′
p
(
s
′
∣
s
,
a
)
v
π
(
s
′
)
]
π
(
a
∣
s
)
\begin{aligned} v_{\pi}(s) &= \mathbb{E}[G_t|S_t=s] \\ &= \sum\limits_{a}\mathbb{E}[G_t|S_t=s,A_t= a] \\ &= \sum\limits_{a}q_{\pi}(s,a) \pi(a|s)\\ &= \sum\limits_{a} \left[ \sum\limits_{r} p(r|s, a)r + \gamma \sum\limits_{s'} p(s'|s,a) v_\pi (s') \right]\pi(a|s) \end{aligned}
vπ(s)=E[Gt∣St=s]=a∑E[Gt∣St=s,At=a]=a∑qπ(s,a)π(a∣s)=a∑[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)]π(a∣s)
从而有,
q
π
(
s
,
a
)
=
∑
r
p
(
r
∣
s
,
a
)
r
+
γ
∑
s
′
p
(
s
′
∣
s
,
a
)
v
π
(
s
′
)
q_{\pi}(s,a) =\sum\limits_{r} p(r|s, a)r + \gamma \sum\limits_{s'} p(s'|s,a) v_\pi (s')
qπ(s,a)=r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)
上式给出了计算action value的一种方法!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









