






最近在看着篇论文,想要把已经读懂的地方记录下来,至于我读懂的地方对不对,我目前也不能确定,只能先写上。思路大致是按照论文来的,但是会用我自己的语言讲述出来,不会一句一句的翻译。另外我不会的地方就先空着,等我懂了,会再来补上。
论文目标
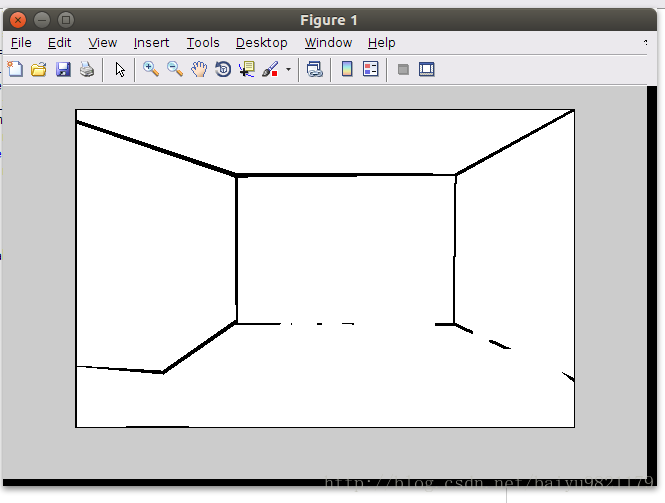
先说说这篇论文想要实现的效果吧,对于给定的一个室内场景图片,要能画出房间布局的线(即墙的交界),就如论文图1里一样。

图中的绿线,就是这篇论文想要得到的效果。
大致流程
在论文里,最后生成的线叫做box layouts(即论文中Fig 1),要得到box layouts,1,先用FCN(或者是structured forest)去训练,获得Informative Eage Maps(论文中的Fig 3)

每一组有3张图片,最左边是原图,中间的是用structured Forest获得的Edge Maps,最后边是用FCN训练得到的Edge Maps,论文中提到了,FCN的训练效果是要优于用structured Forest的效果的。得到了Edge Maps,就要根据给出的图片,进行灭点的估计,根据估计出来的灭点,生成若干个候选的layouts。然后对生成的若干个layouts,结合前面得到的Edge Maps,对这些候选的layouts进行评分,得分最高的那个layout,就是我们最后要找的layout。当然,我在大致流程中省略了很多细节,接下来将一步一步的解释。
预测Informative Edges
这部分对应论文中的第三部分。该论文提供了两种方法,第一种是用structured forest,一种是FCN,我只看了FCN的部分,所以我就只讲讲FCN的训练吧。因为FCN这篇论文我还没看J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. CVPR (to appear), 2015,所以FCN的工作原理我还不清楚,只能先把大概流程说一下。
Informative Edges和Geometric Context Labels
先说一下什么是Informative Edges,在该论文中,Informative Edges被定义为一个房间内,墙和墙之间,墙和天花板之间,墙和地板之间的交界处,也就是房间里各种边界(即论文中Fig1里面,被绿线画出来的边)。
另外还有一个概念是Geometric Context labels, 这个label总共有7个值middle wall, right wall, right wall, left wall, ceiling, floor, object, edges。
训练数据
首先是训练数据,训练数据(hedau+)总共被分成了3类,被存储到了.mat文件了,用matlab打开,可以看到每个.mat文件里,都有3个变量fields, gtPolyg, labels。先用来解释最简单的gtPloyg变量吧,gtPloyg变量是一个cell数组,里面每个cell存了一组坐标,把这些坐标依次按照顺序连接起来,就是一个多边形,不一定是几条边的,但一定是多边的,而把这些坐标链接起来以后的多边形,就把一个物体给框起来了,比如说一个沙发,一个床等等。再看看fields变量,是一个二维数组,大小和图片大小一样,读取以后,发现都是1-6之间的整数值,这代表什么呢?原来,hedau+把每张图片的每个像素都做了标记,1-6分别代表floor,middle wall, left wall, right wall, ceiling, edges。另外一个变量labels,也是一个二维数组,大小也图片一样,不同的是,每个元素的取值范围是1-7,比fields多了一个值,多出来的这个值,是用来表示object的,比如沙发,床之类的家具,如果像素点在一个沙发内,就会被标记为6,其中1-5代表的label和fields一样,而6变成了object,edges变成了7。只说对于理解不太只观,下面上图:
原图:

labels变量中:
object标签
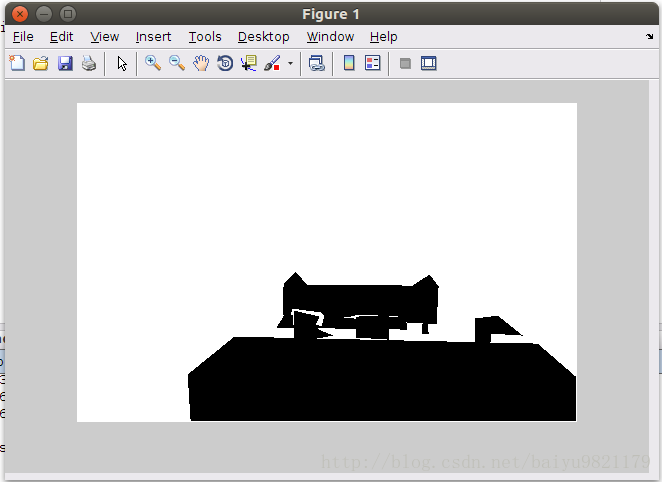
middle wall标签
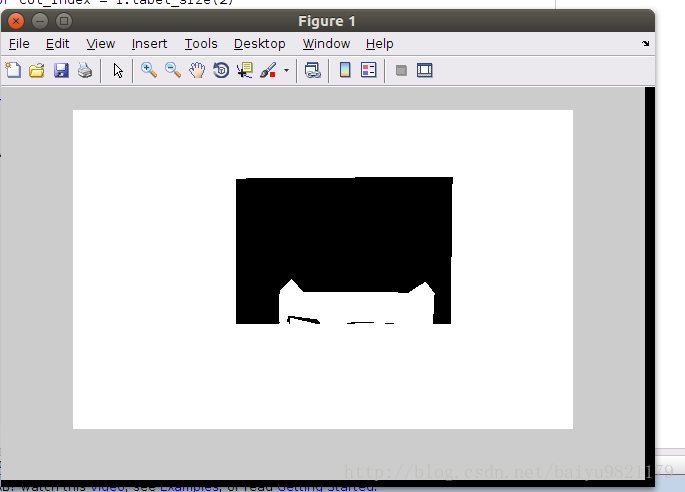
edges标签
fields变量中:
floor标签
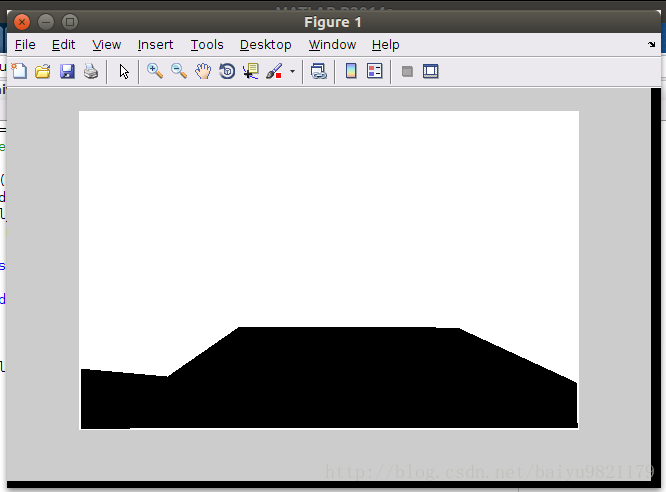
edges标签
可以看到,fields和labels的区别,就是有没有object标签,以及object标签是否遮挡了别的标签。之所以这样,我认为是由于需要joint training edge maps和GC labels,才有两种标签,不含object的标签用来训练edge maps,另一个用来训练GC labels。
生成box layout
这部分对应文论的第四部分。该部分基于文献[10]V. Hedau, D. Hoiem, and D. Forsyth. Recovering the spatial layout of cluttered rooms. In CVPR, 2009.总共分成三步:(1)估计灭点(2)根据估计的灭点,生成几个候选的layouts,这一步要用到前面生成的edge maps。(3)用structured svm 来训练,获得最合适的那个layout。
生成灭点
这个步骤,用到了文献10的方法,















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









