







目前来看,很多对 NN 的贡献(特别是核心的贡献),都在于NN的梯度流上,比如
- sigmoid会饱和,造成梯度消失。于是有了ReLU。
- ReLU负半轴是死区,造成梯度变0。于是有了LeakyReLU,PReLU。
- 强调梯度和权值分布的稳定性,由此有了ELU,以及较新的SELU。
- 太深了,梯度传不下去,于是有了highway。
- 干脆连highway的参数都不要,直接变残差,于是有了ResNet。
- 强行稳定参数的均值和方差,于是有了BatchNorm。
- 在梯度流中增加噪声,于是有了 Dropout。
- RNN梯度不稳定,于是加几个通路和门控,于是有了LSTM。
- LSTM简化一下,有了GRU。
- GAN的JS散度有问题,会导致梯度消失或无效,于是有了WGAN。
- WGAN对梯度的clip有问题,于是有了WGAN-GP。
说到底,相对于8,90年代(已经有了CNN,LSTM,以及反向传播算法),没有特别本质的改变。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注:上述内容来在《浅析Hinton最近提出的Capsule计划》(https://zhuanlan.zhihu.com/p/29435406)
网络结构
-
- 全卷积网络结构
- ReLU Nonlinearity:饱和性问题,速度快
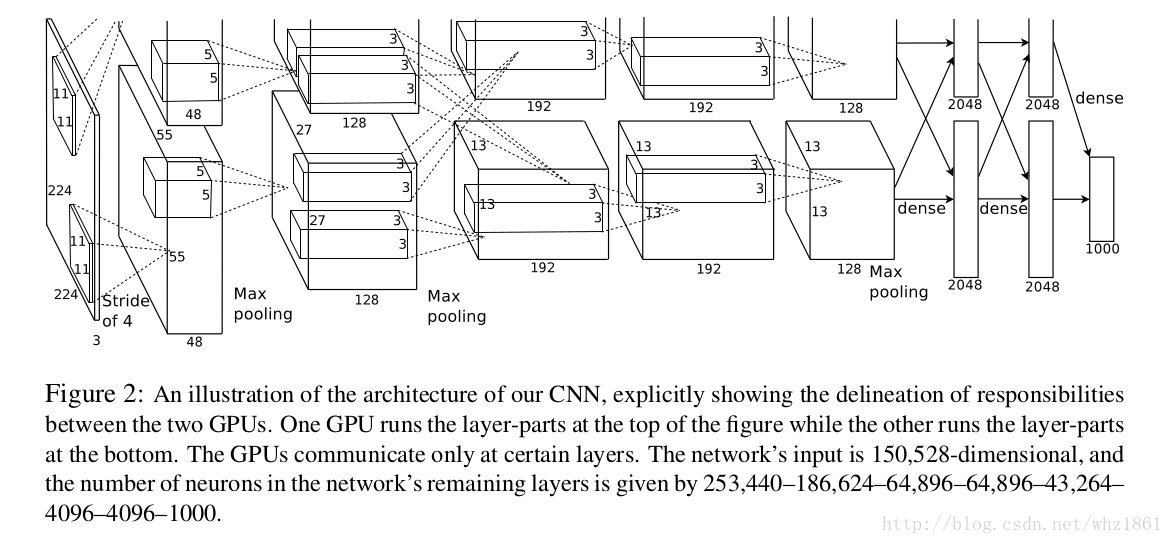
- 多GPU训练
- Local Response Normalization
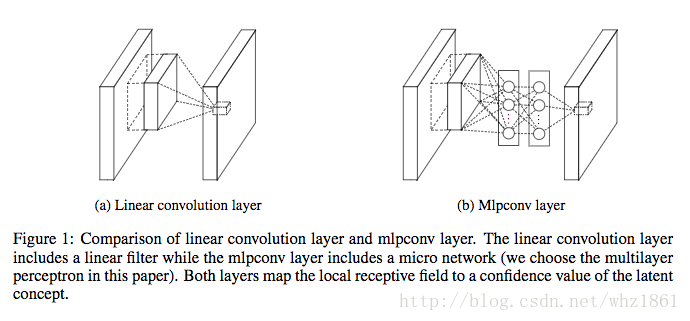
- Network in Network
- mlpconv:有效提升了局部特征提取能力【结构图】
- global average pooling: 将CNN与FC两部分有机结合【特征层与分类有强相关性】
- mlpconv:有效提升了局部特征提取能力【结构图】
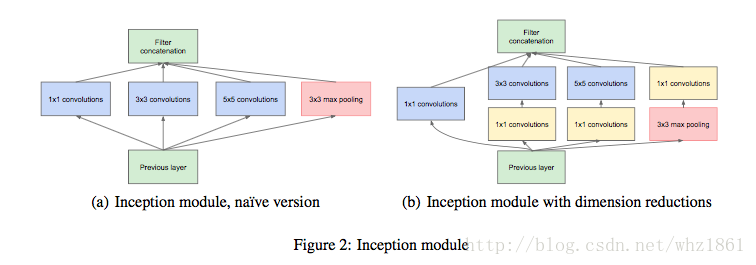
- GoogLeNet
- Inception v1
- 在深度和宽度两方面进行探索
- 中间利用辅助网络进行训练
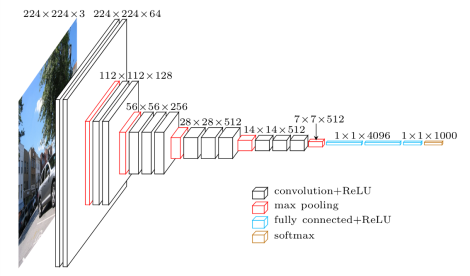
- VGG
- VGG论文给出了一个非常振奋人心的结论:卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用
- 小卷积核的大量运用
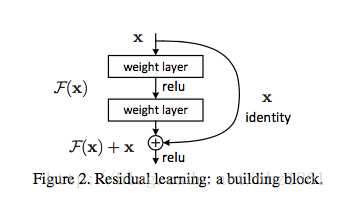
- ResNet
- 问题:网络越深,越容易出现梯度消失,导致模型训练难度变大,出现“退化”现象
- 残差模块
- Inception-v2
- 随着网络的深度加深,训练会越来越困难,改善方法
- 激活函数:sigmoid,tanh函数会存在左右饱和问题,从而Hiton推出了ReLU函数可以有效的解决反向传播过程中的梯度消失
- Batch Normalization: 归一化(本文内容)
- Residual Network:通过增加一个skip connection(Identity mapping),使得底层的信息和高层的信息能够建立起更加直接的联系
- BatchNormalization

- 随着网络的深度加深,训练会越来越困难,改善方法
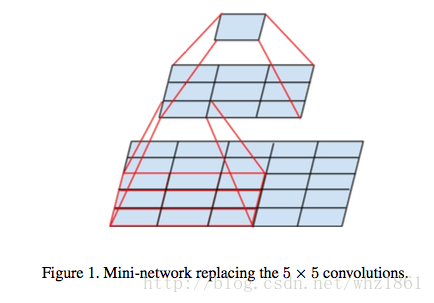
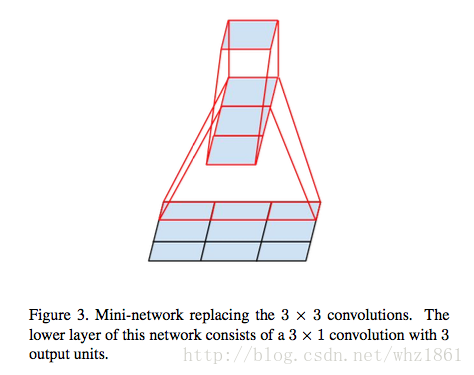
- Inception-v3
- 大卷积转小卷积
- 卷积的height与width解耦合
- 大卷积转小卷积
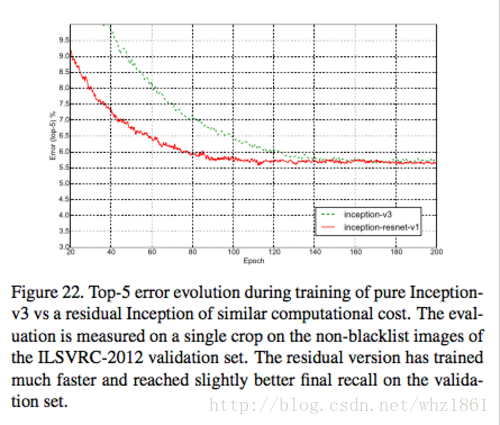
- Inception-v4
- 将残差网络与Inception进行结合,证明残差结构对网络的训练速度起到了非常关键的作用。
- 提出了3个模型结构:
- Inception V4
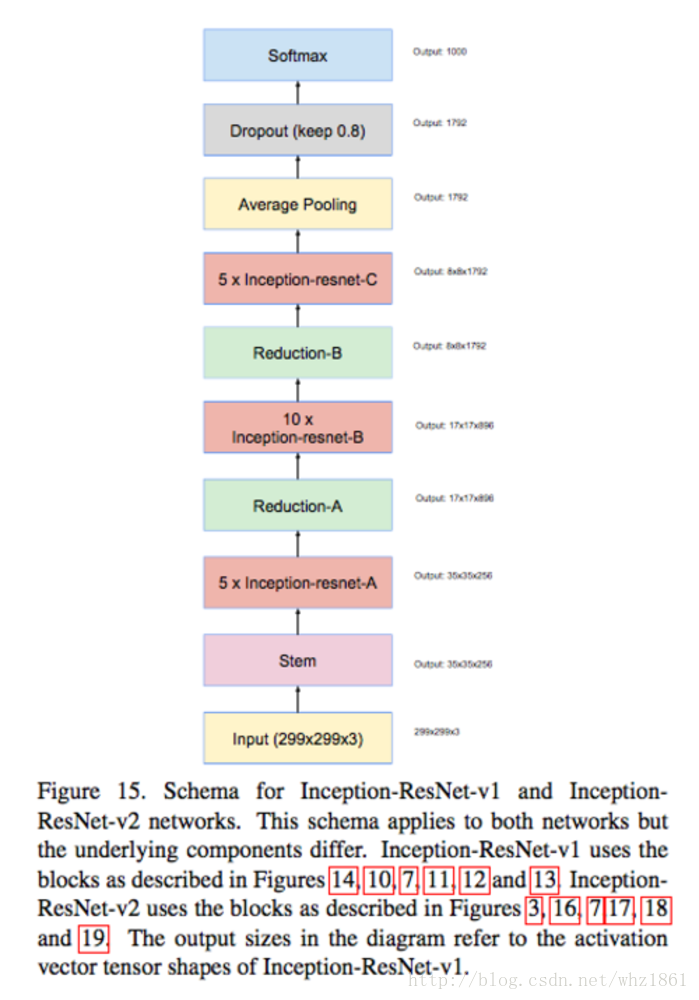
- Inception-ResNet-V1:在Inception V3基础上发展
- Inception-ResNet-V2:在Inception V4基础上发展
- 将残差网络与Inception进行结合,证明残差结构对网络的训练速度起到了非常关键的作用。
-
- 利用1x1的卷积核代替3x3卷积:可以有效降低参数
- 降低3x3卷积操作的输入
- 降采样操作延后,可以得到比较大的特征图
- 结合残差的思想
- MobileNet
- 基于depthwise separable convolution(来源于FactorizedNet)来实现
- depth-wise convolution:每一层分别作卷积
- point-wise convolution :1x1卷积,把各个层连接起来
- 基于depthwise separable convolution(来源于FactorizedNet)来实现
- Xception
- 基于Inception系列网络结构的基础上,结合depthwise separable convolution【为什么可以代替Inception module?】
- 基于Inception系列网络结构的基础上,结合depthwise separable convolution【为什么可以代替Inception module?】
- FractalNet
- 分形结构
- Regularization via Drop-path:发明了droppath训练方法
- 分形结构
- ShuffleNet
- pointwise group convolution:为了减少1x1卷积的操作带来的操作量。原先的卷积在所有通道上进行,作者把所有通道进行分组卷积,类似mobileNet中采用的depthwise separable convolution。(1x1卷积在很多基础模型上,都大量使用,作用也是用来减少计算量的,本文对1x1卷积更进一步,分组卷积,从而进一步降低计算量)
- shuffle channel操作:就是在分组卷积的基础上,打乱不同通道的排序,使得下一层的操作的输入能吸收来上一层不同组的内容,使得学习更佳均衡。(该思想早在AlexNet时,就采用过,当时分组的目的是由于当时的GPU显存不够,不得已而为之)
- 结合残差的思想
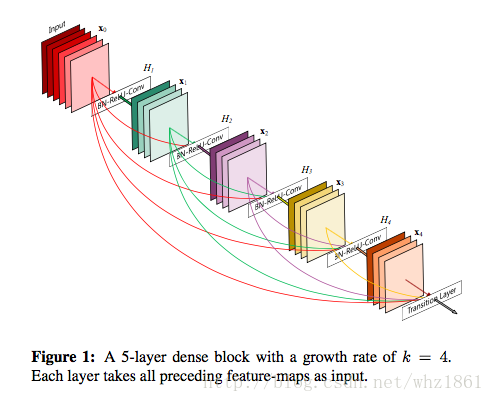
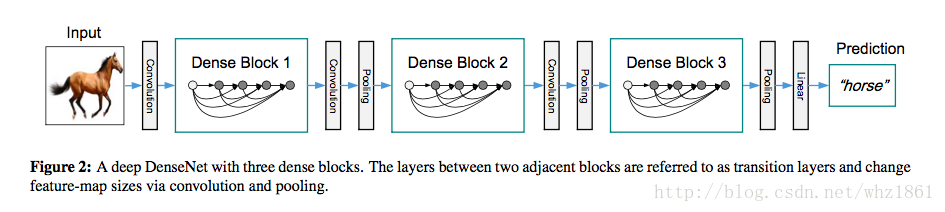
- DenseNet
- 2017 年CVPR最佳论文
- denseNet的思想来自于作者之前的工作(随机深度网络,Deep Network with Stochastic depth),其训练过程中采用随机dropout一些中间层的方法改进ResNet,发现可以显著提高ResNet的泛化能力。 【注:Deep Network with Stochastic depth,在训练过程中,随机去掉很多层,并没有影响算法的收敛性,说明了ResNet具有很好的冗余性。而且去掉中间几层对最终的结果也没什么影响,说明ResNet每一层学习的特征信息都非常少,也说明了ResNet具有很好的冗余性。(这个应该得益于ResNet的skip connections的作用)】
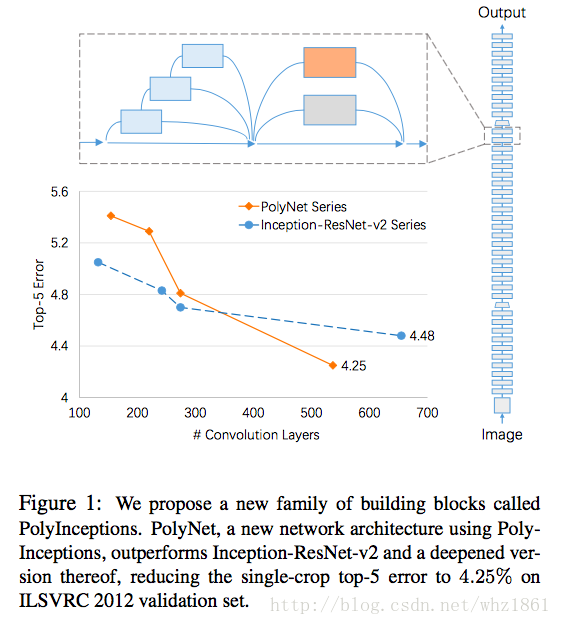
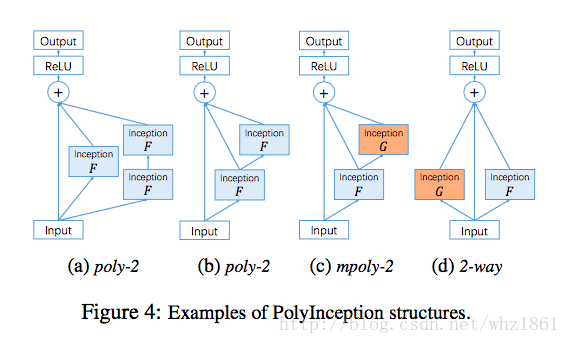
- PolyNet
- 发现当模型的深度达到一定程度的时候,深度的增加对模型的提高起到的作用大大降低。从而,这也激发了作者从另外的一个角度去探索模型的结构,那就是结构多样性【structural diversity,类似于Inception modules】
- 发现当模型的深度达到一定程度的时候,深度的增加对模型的提高起到的作用大大降低。从而,这也激发了作者从另外的一个角度去探索模型的结构,那就是结构多样性【structural diversity,类似于Inception modules】
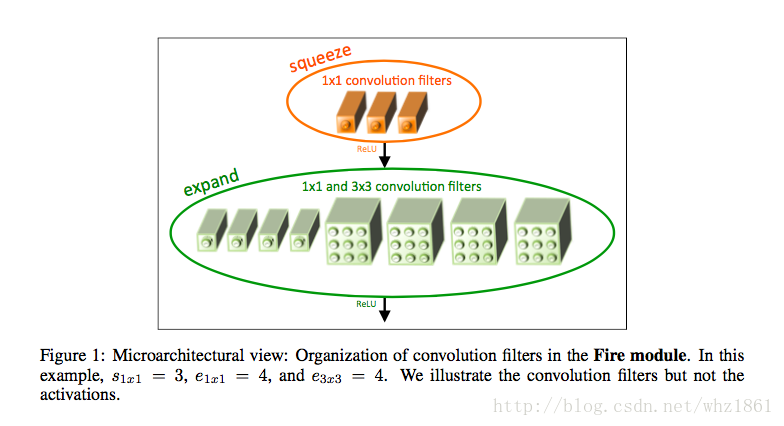
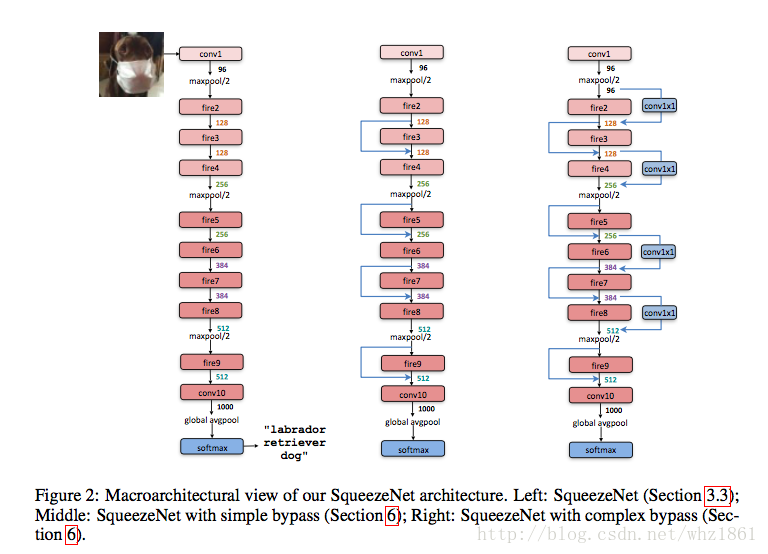
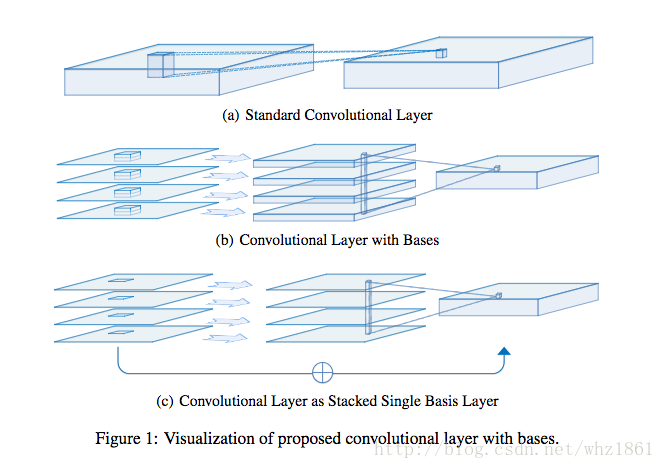
- SEP-Nets
- 怎么保证模型表达效果的前提下,不断缩小模型的参数量,模型压缩:
- quantization
- binarization
- sharing
- pruning
- hashing
- Huffman coding
- 论文考虑了减少模型参数的方法:
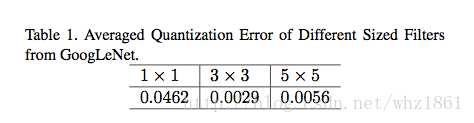
- binarizatin【二值化】:但论文只考虑kxk(k>1)的卷积核的二值化,对1x1卷积核不做处理
- binarizatin【二值化】:但论文只考虑kxk(k>1)的卷积核的二值化,对1x1卷积核不做处理
- SEP-Nets模块
- 怎么保证模型表达效果的前提下,不断缩小模型的参数量,模型压缩:


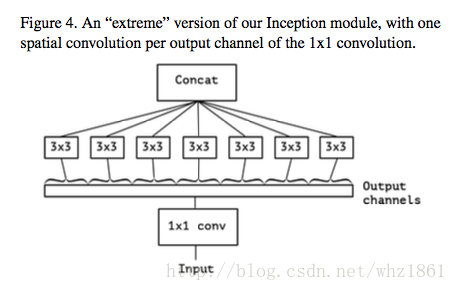
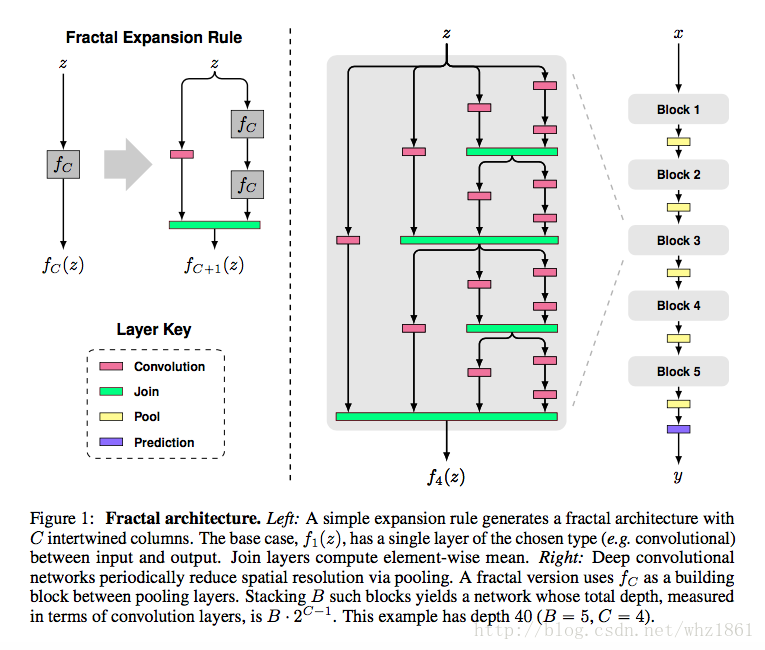
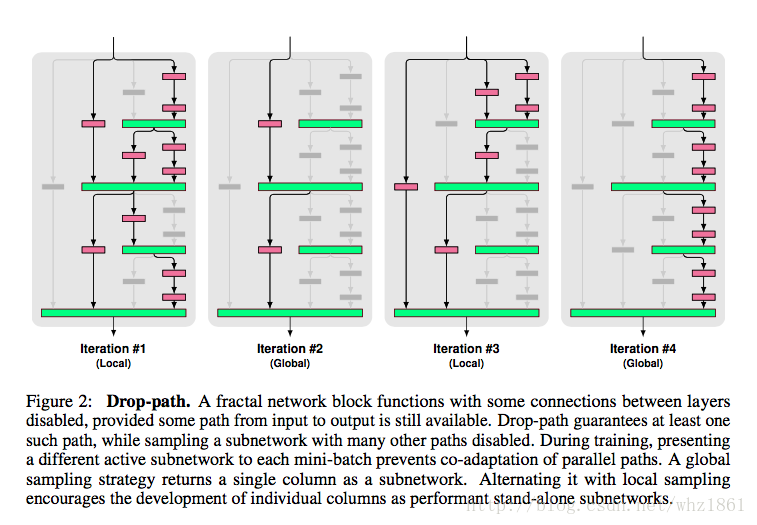
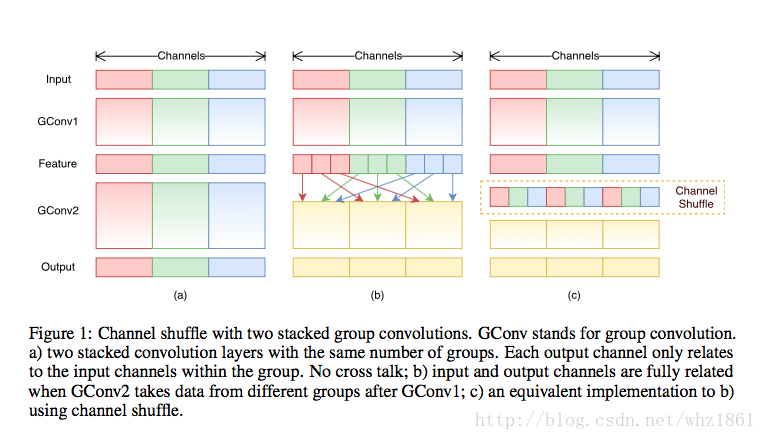
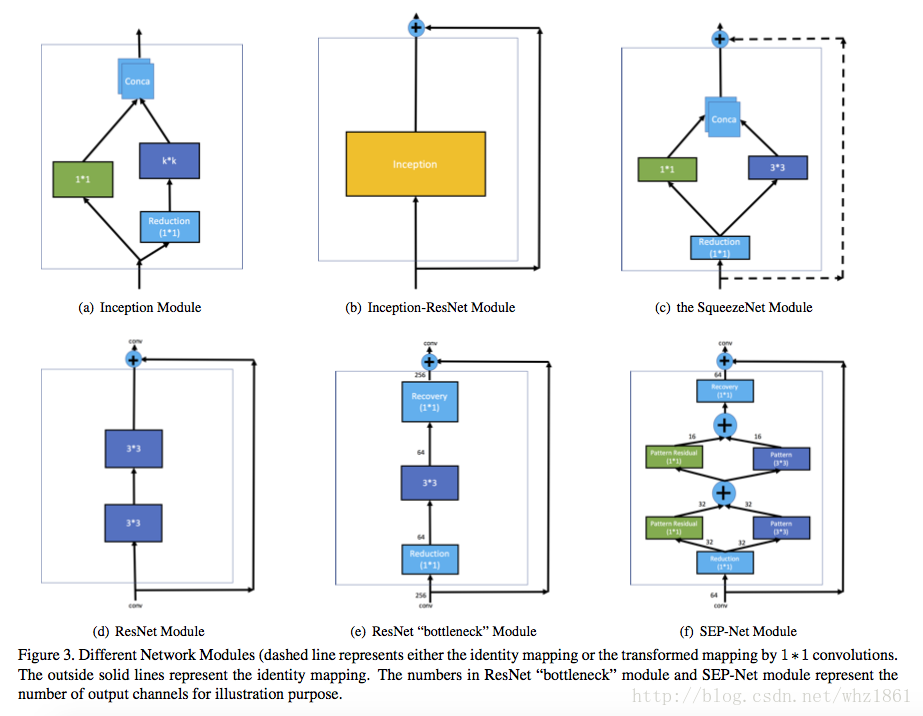

模型发展思路
在网络结构设计的发展中,存在着几个关键的路线:
- 在网络深度/宽度上进行增强【AlexNet->VGG->GoogLeNet->ResNet】
- 在卷积核上进行处理:width/height/channel解耦合【1xn,nx1,1x1,depthwise-separable conv】
- InceptionV3, SqeezeNet, MobileNet, Xception
- 多样性:structural diversity【Inception系列】
- GoogLeNet, InceptionV2, InceptionV3, InceptionV4
另一种角度,可以将网络结构设计分为:
- ensemble by structure: 结构上不断改进【shortcut path,highway】
- AlexNet ->VGG-> GoogLeNet->ResNet->DenseNet->FractalNet
- ensemble by train: 训练过程不断改进,比如droppath等技术【Stochastic depth technique, swapout】
- PolyNet, FractalNet
但是为什么当前这种方式实际效果很好?Hiton提出:
- 全参数优化,end-to-end: 反向传播(下面用BP代替)可以同时优化所有的参数,而不像一些逐层优化的算法,
下层的优化不依赖上层,为了充分利用所有权值,所以最终还是要用BP来fine-tuning;
也不像随机森林等集成算法,有相对分立的参数。很多论文都显示end-to-end的系统效果会更好。
- 形状灵活: 几乎什么形状的NN都可以用BP训练,可以搞CNN,可以搞LSTM,可以变成双向的 Bi-LSTM,可以加Attention,可以加残差,
可以做成DCGAN那种金字塔形的,或者搞出Inception那种复杂的结构。如果某个结构对NN很有利,那么就可以随便加进去;
将训练好的部分加入到另一个NN中也是非常方便的事情。这样随着时间推进,NN结构会被人工优化得越来越好。
BP的要求非常低:只要连续,就可以像一根导线一样传递梯度;
即使不连续,大部分也可以归结为离散的强化学习问题来提供Loss。
这也导致了大量NN框架的诞生,因为框架制作者知道,这些框架可以用于所有需要计算图的问题(就像万能引擎),
应用非常广泛,大部分问题都可以在框架内部解决,所以有必要制作。
- 计算高效: BP要求的计算绝大多数都是张量操作,GPU跑起来贼快,并且NN的计算图的形式天生适合分布式计算;
而且有大量的开源框架以及大公司的支持。













 5076
5076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









