






Lift Splat Shoot算法是一种用于自动驾驶感知的算法,它由NVIDIA提出。该算法通过将多视角相机图像转换为3D空间中的特征表示。其主要思想是将每个相机的图像通过"抬升(Lift)"的方式生成3D特征,然后将这些3D特征通过"拍扁(Splat)"的方式投射到光栅化的鸟瞰图网格中。最后,通过将模板运动轨迹"投射(Shoot)"到网络输出的BEV Cost Map中,实现可解释的端到端的运动规划。
对于感知算法而言,Lift Splat Shoot算法的关键在于对BEV(鸟瞰图)的感知范围、BEV单元格大小和深度估计范围的设置。感知范围可以决定x轴和y轴方向的感知距离,BEV单元格大小决定了BEV下的单位大小,深度估计范围则决定了Lift Splat Shoot算法需要估计的离散深度范围。
通过Lift Splat Shoot算法,可以将多个相机的2D信息转换为3D信息,并将多个摄像头的3D信息进行拼接,从而得到对整个场景的统一表示。该算法在目标分割、地图分割等任务上取得了优于基线方法和之前工作的结果。
总体流程
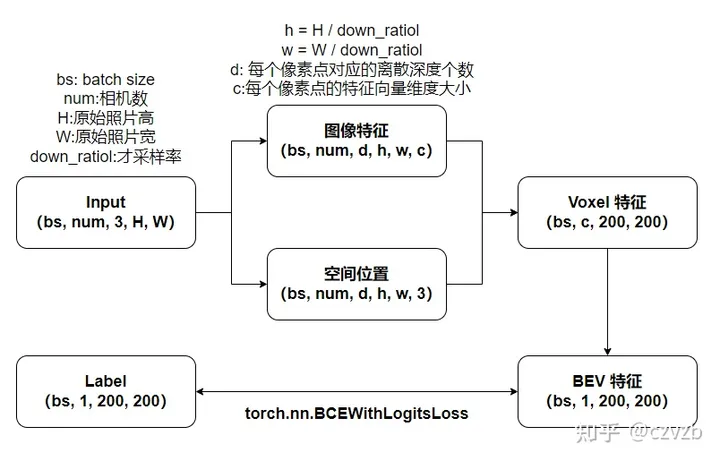
总体流程
获取空间位置
构造frustum
frustum是LiftSplatShoot的一个用nn.Parameter(frustum, requires_grad=False)包裹的成员,是参与梯度与更新的。

frustum是一个4维矩阵,代表了在41×8×22的伪点云中,每个点的x,y,z三个坐标

部分x坐标的实际值

部分y坐标的实际值

z坐标(深度)的实际值
将相机坐标系转换至自车坐标系
geom = self.get_geometry(rots, trans, intrins, post_rots, post_trans)
geom的shape任然为(41,8,22,3),但是转换到了自车坐标系下

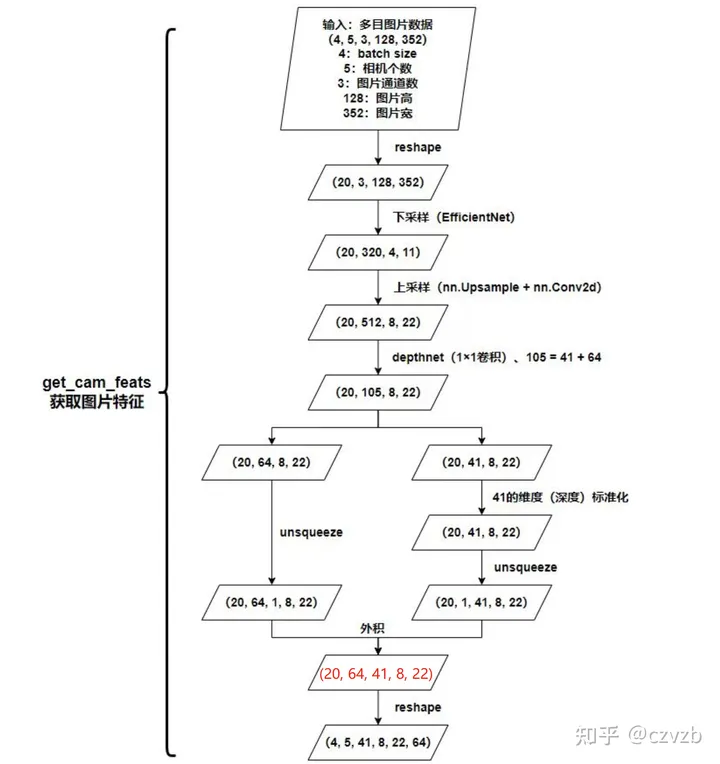
获取相机特征(CamEncode)
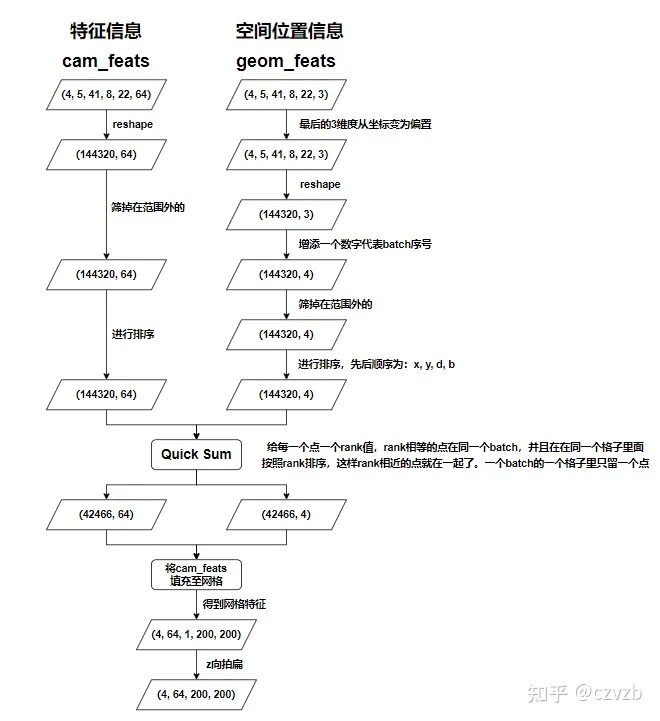
voxel_pooling

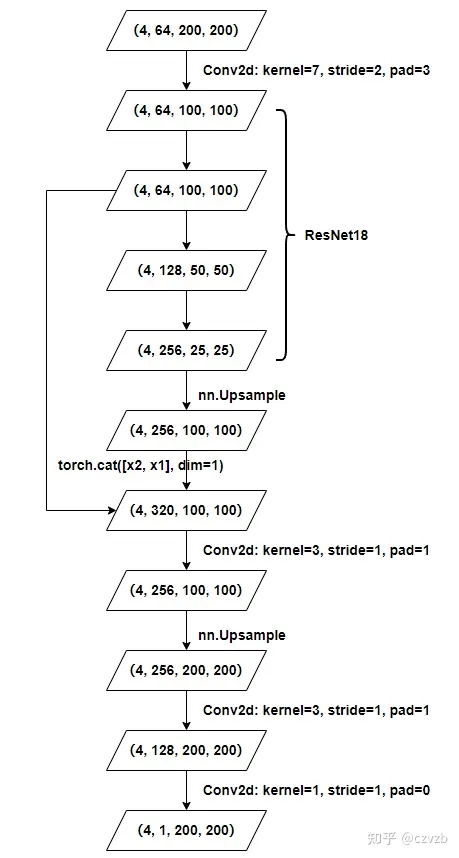
获取BEV特征(BevEncode)
第二篇:BEV经典之作Lift, Splat, Shoot解析 - 知乎
本文的主要内容:
- BEV感知
- LSS贡献
- LSS工作流程
- Lift & Splat 原理以及相关源码解析
BEV感知
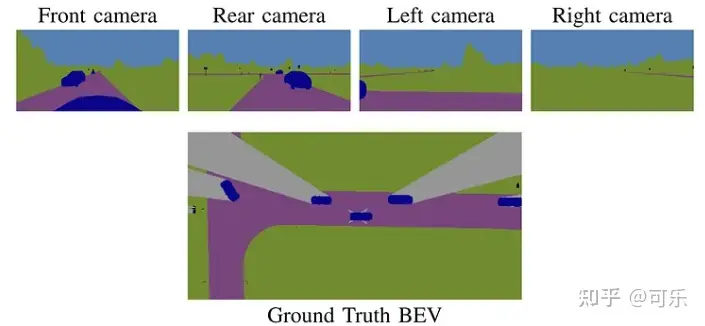
自动驾驶汽车为了感知周围的环境,会在车身周围安装多个传感器,每个传感器都有自己的坐标系。为了使得后续处理更加方便,我们通常将不同传感器的感知数据转换到一个统一的坐标系。比如目前最流行的鸟瞰图BEV("bird's-eye-view")感知范式,就是从来自不同传感器的数据中提取特征,然后将这些特征转换到统一的BEV坐标系下,再进行后续的感知任务,比如检测、分割等。如下图所示,上方为车上前、后、左、右4个相机拍摄到的画面,下方为转换后的BEV表示。
LSS的贡献
LSS算是BEV感知的开山之作,其主要贡献有以下几点:
- 提出了一种将图像从2d转换到3d的方法(Lift);
- 提出了一种end-to-end模型,可以将来自多个相机的图像特征转换到统一的BEV空间;
- LSS是纯视觉模型,为后续的纯视觉BEV感知算法研究奠定了基础。

上图左边是不同相机拍摄的图像,右边是将这些不同视角的图像转换到BEV空间后,在BEV空间直接进行语义分割的结果。(左边图像中的着色点,代表将BEV空间中的预测结果反投影到了图像上)
LSS工作流程

LSS的整个工作流如上图,模型的输入是来自不同相机拍摄的 � 张图像,以及每个相机的外参矩阵 �� 和内参矩阵 �� ,其中 �∈[1,2,...,�] ;模型首先对每张图像(实际上是特征图)进行 "Lift" 操作,将图像从2d平面提升到3d空间,生成3d视锥(frustum)点云,并对点云上所有的点预测context特征,生成context特征点云;然后对视锥点云和context特征点云进行 “Splat” 操作,在BEV网格中构建BEV特征,即模型的输出;最后,得到BEV特征后,可通过“Shooting”完成特定的下游任务,比如Motion Planning。
要理清LSS的工作流程,就是要搞明白“Lift”和“Splat”这两个操作,在上图中,我列出了源码中实现"Lift"和“Splat”这两个操作的相关函数,接下来我将结合源码,来重点解析下这两个操作的原理以及它们是如何实现的。
Lift
相机将真实世界投影到图像平面,是一个3d转2d的过程,会丢失深度信息。Lift的目的就是为了恢复图像中每个像素的深度,将图像从2d平面提升到3d空间,该操作具体分为两步:
【Step1】生成3d视锥(frustum)点云:令图像大小为 [H, W] ,为每个像素生成D个离散的深度值,表示这个像素所有可能处于的深度位置,从而生成大小为 [D, H, W] 的视锥点云,然后利用相机的内参和外参,将所有的视锥点云转换到自车坐标系。论文中设置深度方向的范围是 [4m, 45m],每间隔1m估计1个离散深度,故每个像素会生成41个深度值,即D=41。
实现该步骤的源码为models.py文件中的create_frustum()和get_geometry()这两个函数,源码解析:
def create_frustum(self):
"""
将图像从2d提升到3d,生成3d视锥(frustum)点云。
这里实际上是在下采样后的特征图上生成点云,然后把每个点的坐标映射回原图中。
"""
ogfH, ogfW = self.data_aug_conf['final_dim'] # 原始图像大小 (128,352)
fH, fW = ogfH // self.downsample, ogfW // self.downsample # 经backbone下采样后的特征图大小 (8,22)
# 为特征图上的每个点生成一组深度位置,shape变化:(41,) -> (41,1,1) -> (41,8,22),这里dbound=[4,45,1]
ds = torch.arange(*self.grid_conf['dbound'], dtype=torch.float).view(-1, 1, 1).expand(-1, fH, fW)
D, _, _ = ds.shape
# 将每个点的x坐标映射回原图,shape变化:(22,) -> (1,1,22) -> (41,8,22)
xs = torch.linspace(0, ogfW - 1, fW, dtype=torch.float).view(1, 1, fW).expand(D, fH, fW)
# 将每个点的y坐标映射回原图,shape变化:(8,) -> (1,8,1) -> (41,8,22)
ys = torch.linspace(0, ogfH - 1, fH, dtype=torch.float).view(1, fH, 1).expand(D, fH, fW)
# 堆叠生成视锥点云,shape为(41,8,22,3),3代表每个点的3d坐标(x,y,d)
frustum = torch.stack((xs, ys, ds), -1)
return nn.Parameter(frustum, requires_grad=False)
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):
"""
将每张图的视锥点云从图像坐标系转换到自车坐标系。
rots:由相机坐标系->自车坐标系的旋转矩阵,(B, N, 3, 3)
trans:由相机坐标系->自车坐标系的平移矩阵,(B, N, 3)
intrins:相机内参,(B, N, 3, 3)
post_rots:由图像增强引起的旋转矩阵,(B, N, 3, 3)
post_trans:由图像增强引起的平移矩阵,(B, N, 3)
"""
B, N, _ = trans.shape
# 恢复数据增强以及预处理对像素位置的变化
points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)
points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))
# 图像坐标系 -> 相机归一化坐标系
points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],
points[:, :, :, :, :, 2:3]
), 5)
combine = rots.matmul(torch.inverse(intrins))
# 相机归一化坐标系 -> 相机坐标系 -> 自车坐标系
points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)
points += trans.view(B, N, 1, 1, 1, 3)
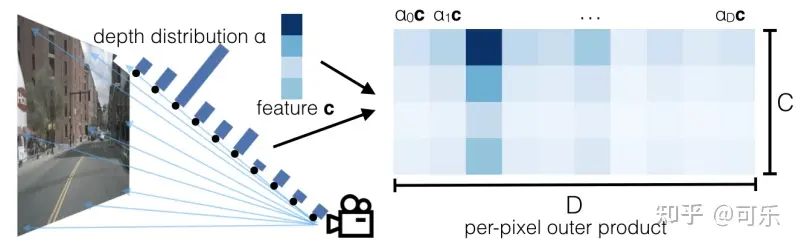
return points # shape (B,N,41,8,22,3)【Step2】生成context特征点云:利用EfficientNet作为backbone提取图像特征,对特征图上的每个点,预测C维的特征向量�∈��以及D个离散深度的概率分布�(C等于64,D等于41),然后将特征向量和深度分布做外积,生成context特征。实际上,每个点的context特征可以看作成一个shape为(64, 41)的2维张量,其中每一列 �� 由该点在深度为d处的深度分布值 �� 乘以特征向量c上得到,即论文中的公式(1):
��=���
如下图所示,左边为图像上某点在其深度方向上预测的D个深度分布 � ,中间为该点的特征向量c,右边为通过外积得到的context特征,可以看出,由于在第三个深度处的概率值最高,所以在外积结果中 �2� 获得的特征最丰富。
实现该步骤的源码为models.py文件中的get_cam_feats()和==get_depth_feat()这两个函数,源码解析:
def get_depth_feat(self, x):
"""
为特征图上的每个点生成context特征,构建context特征点云。
x: 输入图像,shape为(B*N,3,128,352),注意这里将batch和每个batch的图像数量N融合成了一个维度
"""
# get_eff_depth用于提取图像特征,源码中使用efficientNet作为backbone,输出的特征图shape为(B*N,512,8,22)
x = self.get_eff_depth(x)
# depthnet实际就是一个Conv2d,输出的特征图shape为(B*N,105,8,22),其中105的前41项为深度值,后面64项为特征
x = self.depthnet(x)
# 提取前41维的深度图,通过get_depth_dist执行softmax得到概率分布,shape为(B*N,41,8,22)
depth = self.get_depth_dist(x[:, :self.D])
# 提取后64维的特征图,和深度分布做外积,构建context特征点云,shape为(B*N,64,41,8,22)
new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2)
return depth, new_x
def get_cam_feats(self, x):
"""
构建context特征点云。
x: 输入图像,shape为(B,N,3,128,352)
"""
B, N, C, imH, imW = x.shape # shape(B,N,3,128,352)
x = x.view(B*N, C, imH, imW) # 合并维度0和维度1,shape(B*N,3,128,352)
x = self.camencode(x) # camencode内部会调用get_depth_feat得到context特征点云,shape(B*N,64,41,8,22)
x = x.view(B, N, self.camC, self.D, imH//self.downsample, imW//self.downsample) # shape(B,N,64,41,8,22)
x = x.permute(0, 1, 3, 4, 5, 2) # shape(B,N,41,8,22,64)
return x Splat
经过Lift操作后,我们得到了两个3d点云:
- 视锥点云:shape为(B, N, 41, 8, 22, 3),包含了每个点在自车坐标系中的位置
- context特征点云:shape为(B, N, 41, 8, 22, 64),包含了每个点的context特征
Splat的目的就是将context特征投影到BEV网格中,构建BEV特征。具体为:首先将视锥点云从自车坐标系平移到BEV网格中,并滤除平移后落在BEV网格边界外的点;由于可能存在多个点落到同一个单元格中,所以对每个点赋一个rank值,rank值相同的点表示在同一个batch的同一个单元格里;最后对落在同一个单元格的context特征进行求和池化,得到BEV特征。
BEV网格:在以自动驾驶车辆为中心的俯视图中,沿着x轴和y轴方向划分N个单元格(有的论文中也称为"Pillar"),每个单元格有特定的大小,在车辆感知范围内的所有单元格构成了BEV网格。
论文中设置x轴方向和y轴方向的感知范围都为-50m ~ 50m,z轴方向的感知范围为-10m ~10m,单元格的长宽高为[0.5m, 0.5m, 20m],故BEV网格大小为200x 200x1。
实现Splat操作的源码为models.py文件中的voxel_pooling()函数,源码解析:
def voxel_pooling(self, geom_feats, x):
"""
构建BEV特征。
geom_feats: 视锥点云,shape为(B,N,41,8,22,3)
x: context特征点云,shape为(B,N,41,8,22,64)
"""
B, N, D, H, W, C = x.shape
Nprime = B*N*D*H*W
# flatten
x = x.reshape(Nprime, C)
# 将视锥点云从自车坐标系平移到BEV网格中,BEV网格以左上角为原点
geom_feats = ((geom_feats - (self.bx - self.dx / 2.)) / self.dx).long()
geom_feats = geom_feats.view(Nprime, 3)
# 每个点的batch索引,shape(Nprime,1)
batch_ix = torch.cat([torch.full([Nprime//B, 1], ix, device=x.device, dtype=torch.long) for ix in range(B)])
# 合并batch索引,shape(Nprime,4)
geom_feats = torch.cat((geom_feats, batch_ix), 1)
# 过滤掉在落BEV网格边界外的点,网格各维度的边界为[0,200)、[0,200)、[0,1)
kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0])\
& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1])\
& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])
x = x[kept]
geom_feats = geom_feats[kept]
# 给每个点赋予一个rank值,rank相同的点表明落在同一个batch的同一个格子里
ranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B)\
+ geom_feats[:, 1] * (self.nx[2] * B)\
+ geom_feats[:, 2] * B\
+ geom_feats[:, 3]
# 对ranks排序,将rank值相同的点排在一起,这么做的目的是为了后续的cumsum
sorts = ranks.argsort()
x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts]
# 利用cumsum trick对落在同一个格子里的context特征进行求和池化
if not self.use_quickcumsum:
x, geom_feats = cumsum_trick(x, geom_feats, ranks)
else:
x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks)
# 构建BEV特征图,shape(B,64,1,200,200)
final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device)
final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x
# 消除第2维,shape(B,64,200,200)
final = torch.cat(final.unbind(dim=2), 1)
return final
def cumsum_trick(x, geom_feats, ranks):
"""
对落在同一个单元格的特征进行求和池化。
x: 铺平的context特征,shape为(n,64)
geom_feats: 铺平的视锥点,shape为(n,3)
ranks:每个点的rank值,shape为(n,)
"""
# 求所有点的特征执行累加和
x = x.cumsum(0)
# 获取前后rank值不相等的索引位置
kept = torch.ones(x.shape[0], device=x.device, dtype=torch.bool)
kept[:-1] = (ranks[1:] != ranks[:-1])
# 对于具有相同rank值的点,只保留最后一个
x, geom_feats = x[kept], geom_feats[kept]
# 由于前面是对所有点执行累加和,这里进行移位相减,得到具有相同rank值的点的实际特征和
x = torch.cat((x[:1], x[1:] - x[:-1]))
return x, geom_feats下面通过一个例子来理解一下cumsum trick,假设我们有一组包含5个点的context特征,特征维度为2,对其求累加和:
feats = np.array([[1,1], [2,2], [3,3], [4,4], [5,5]])
ft_cumsum = feats.cumsum(0)
>>> ft_cumsum: [[1,1], [3,3], [6,6], [10,10], [15,15]]假设在BEV网格中,第三个点和第四个点落在同一个单元格里,即它们具有相同的rank值:
ranks = np.array([0, 1, 2, 2, 3])
kept = np.ones(feats.shape[0], dtype=bool)
kept[:-1] = (ranks[1:] != ranks[:-1])
>>> kept: [True, True, False, True, True]对于具有相同rank值的点,只会保留最后一个,所以第三个点会被滤掉:
ft_cumsum = ft_cumsum[kept]
>>> ft_cumsum: [[1,1], [3,3], [10,10], [15,15]]移位相减,得到剩余每个点的实际特征和:
ft_cumsum = np.concatenate((ft_cumsum[:1], ft_cumsum[1:] - ft_cumsum[:-1]))
>>> ft_cumsum: [[1,1], [2,2], [7,7], [5,5]]BevEncode
为了执行语义分割任务,最后还接个BevEncode对BEV特征进一步进行编码,BevEncode由一个2d Conv、resnet18的前三层、以及两个上采样层组成,最终输出的特征图shape为(4, 1, 200, 200)。

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









