







上一篇中介绍faster rcnn,这次mask 基本在上次的基础上加了点代码,参考和引用1. mask rcnn slides 2. kaiming he maskrcnn 3. Ardian Umam mask rcnn,欢迎fork简版mask rcnn
整体框架
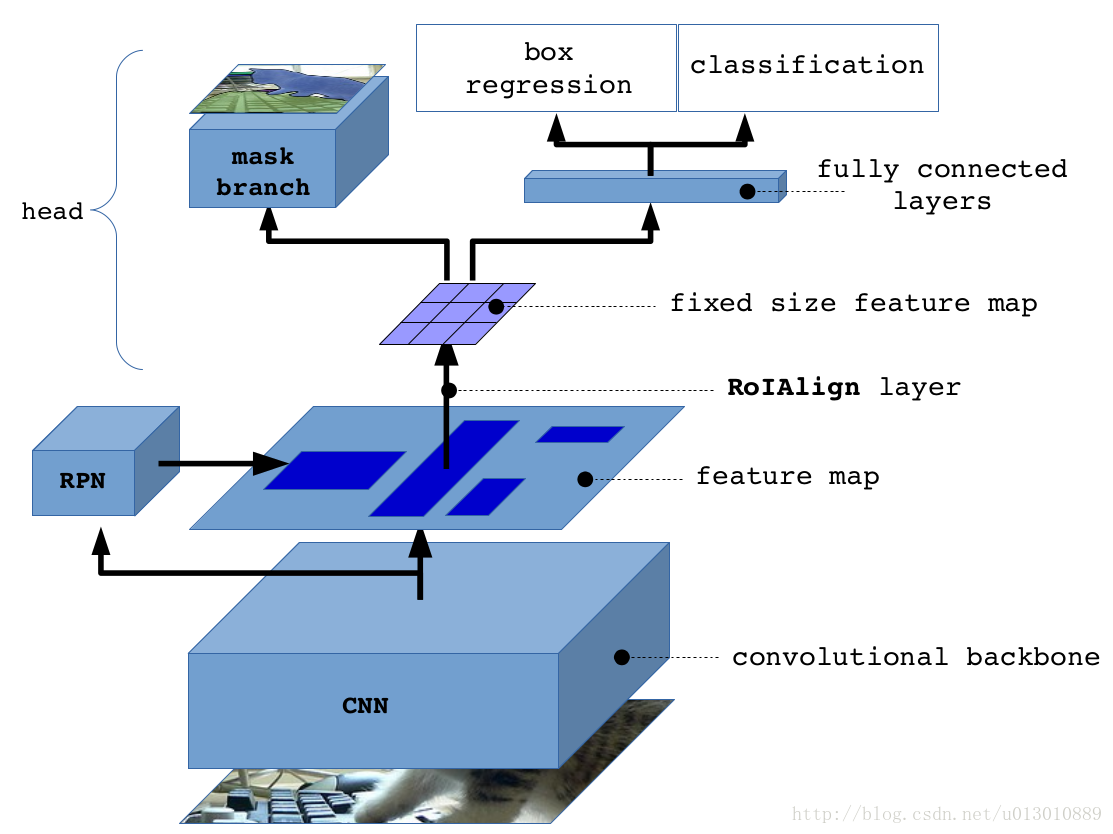
RoIAlign
问题
-
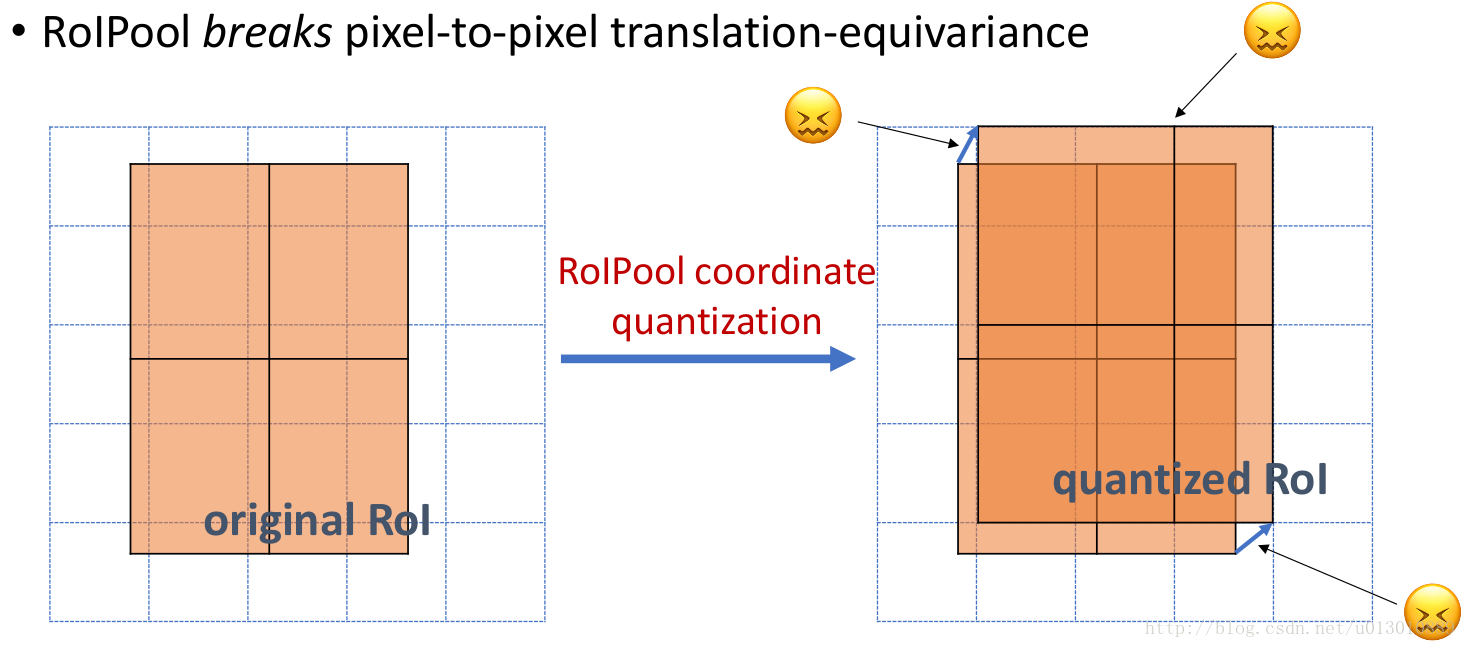
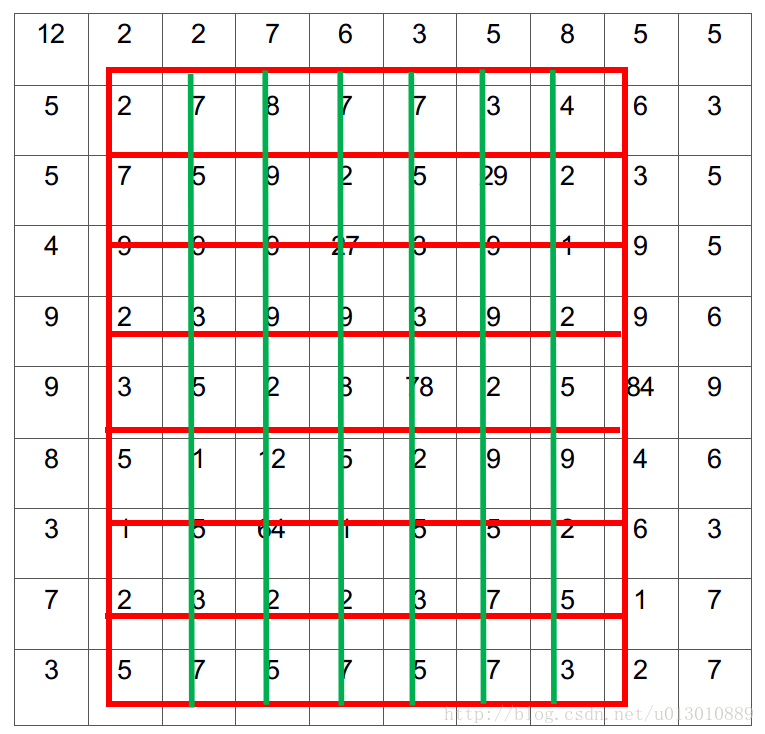
做segment是pixel级别的,但是faster rcnn中roi pooling有2次量化操作导致了没有对齐
-
两次量化,第一次roi映射feature时,第二次roi pooling时(这个图参考了youtube的视频,但是感觉第二次量化它画错了,根据上一讲ross的源码,不是缩小了,而是部分bin大小和步长发生变化)
-
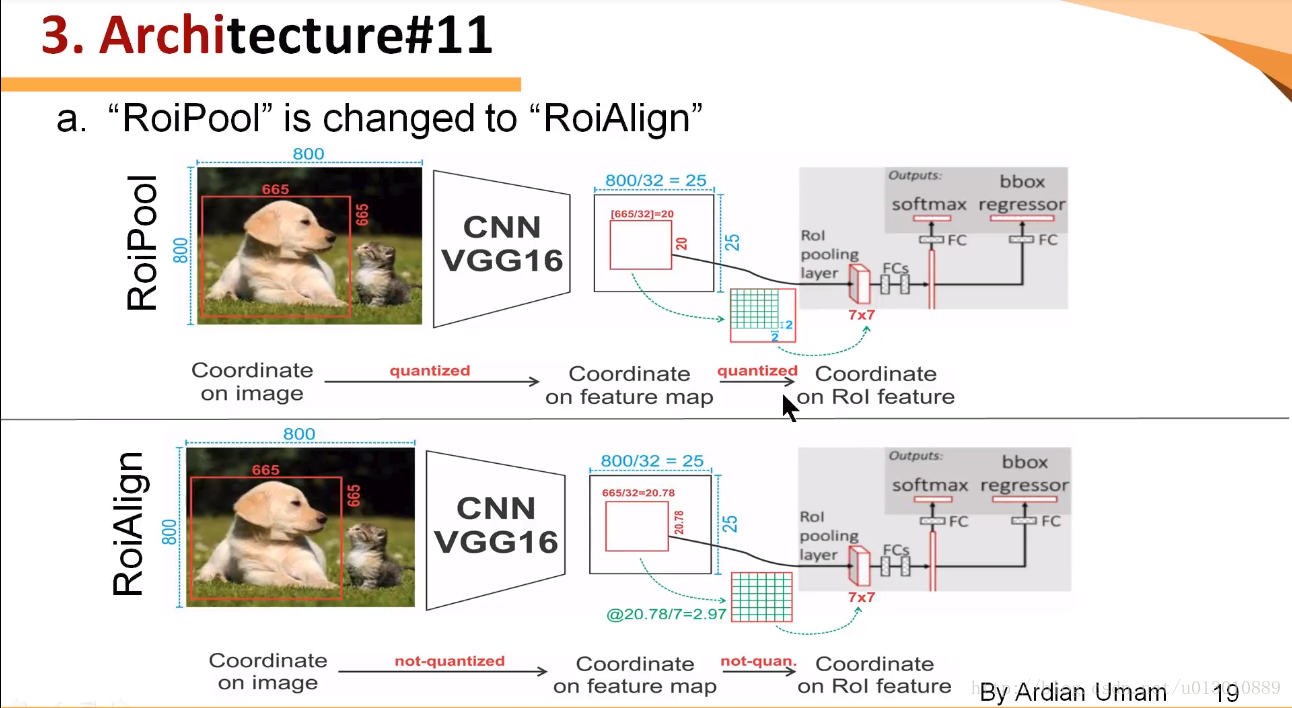
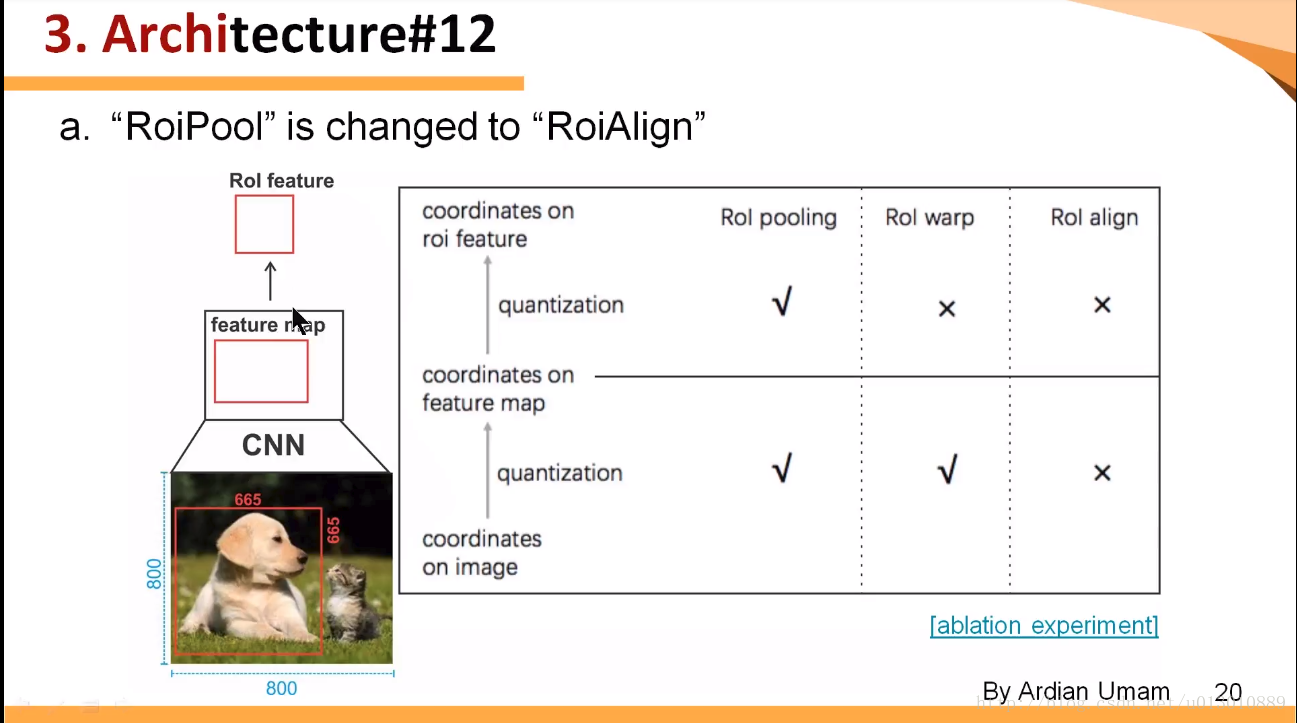
RoIWarp,第一次量化了,第二次没有,RoIAlign两次都没有量化
解决方案
和上一讲faster rcnn举的例子一样,输出7*7
-
划分7*7的bin(我们可以直接精确的映射到feature map来划分bin,不用第一次量化)
-
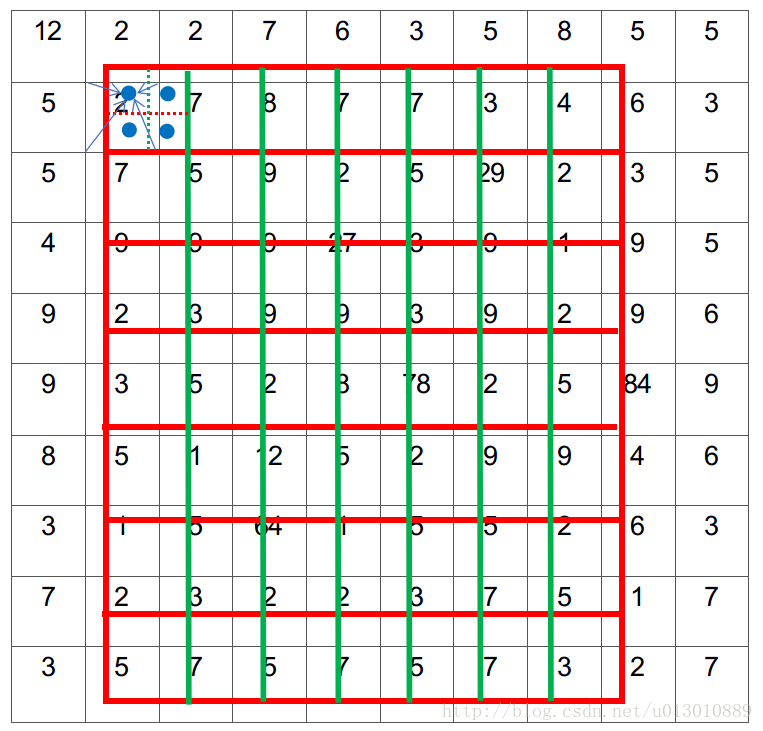
每个bin中采样4个点,双线性插值
-
对每个bin4个点做max或average pool
# pytorch
# 这是pytorch做法先采样到14*14,然后max pooling到7*7
pre_pool_size = cfg.POOLING_SIZE * 2
grid = F.affine_grid(theta, torch.Size((rois.size(0), 1, pre_pool_size, pre_pool_size)))
crops = F.grid_sample(bottom.expand(rois.size(0), bottom.size(1), bottom.size(2), bottom.size(3)), grid, mode=mode)
crops = F.max_pool2d(crops, 2, 2)
# tensorflow
pooled.append(tf.image.crop_and_resize(
feature_maps[i], level_boxes, box_indices, self.pool_shape,
method="bilinear"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
sigmoid代替softmax
利用分类的结果,在mask之路,只取对应类别的channel然后做sigmoid,减少类间竞争,避免出现一些洞之类(个人理解)
FPN
详见我的另一篇博客FPN解读
更多
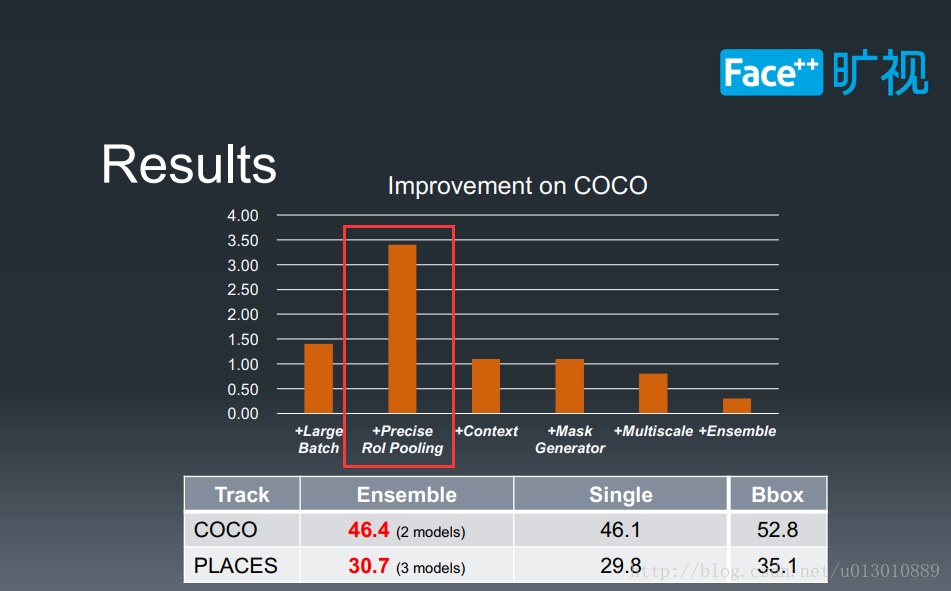
前面我们介绍RoI Align是在每个bin中采样4个点,双线性插值,但也是一定程度上解读了mismatch问题,而旷视科技PLACES instance segmentation比赛中所用的是更精确的解决这个问题,对于每个bin,RoIAlign只用了4个值求平均,而旷视则直接利用积分(把bin中所有位置都插值出来)求和出这一块的像素值和然后求平均,这样更精确了但是很费时。
















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









