







作者:旷视科技
链接:https://zhuanlan.zhihu.com/p/41944858
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

论文名称:《Acquisition of Localization Confidence for Accurate Object Detection》
论文链接:https://arxiv.org/abs/1807.11590
代码链接:https://github.com/vacancy/PreciseRoIPooling
目录
- 导语
- 背景
- 设计思想
- 目标定位
- 分类&定位准确度不匹配
- 非单调边界框回归
- IoU-Net
- 学习预测 IoU
- IoU-guided NMS
- 边界框回归作为优化过程
- 联合训练
- 实验
- IoU-guided NMS
- 基于优化的边界框修正
- 联合优化
- 结论
- 参考文献
- 往期解读
导语
现代基于 CNN 的目标检测器依靠边界框回归和非极大抑制(NMS)来定位目标,其对类别标签的预测概率可以天然反映每个框的分类置信度,然而却缺失了框的定位置信度。这使得原本定位准确的边界框会在迭代回归的过程中偏离目标,又或甚至在 NMS 过程中受到抑制。为此,旷视科技提出 IoU-Net,可学习预测每个检测得到的边界框和与之匹配的目标之间的 IoU 作为该框的定位置信度。利用这种定位置信度,检测器能确保定位更准确的边界框在 NMS 过程中被保留下来,从而改进 NMS 过程。此外,将预测得到的 IoU 作为优化目标,一种基于优化的边界框修正方法也同时被提出。目标检测技术(计算机视觉的基石之一)的这一底层的原创性突破,不仅将优化上层技术的发展,还将为技术落地带来有益影响,比如视频智能理解、智能地产和零售以及智能相机等,推动数字中国、城市大脑、无人超市等产业的进步。
背景
目标检测是很多下游视觉应用的前提基础,比如实例分割、人体骨架绘制、人脸识别和高级目标推理。它结合了目标分类和定位两个任务。现代大多数目标检测器的框架是 two-stage,其中目标检测被定义为一个多任务学习问题:1)区分前景物体框与背景并为它们分配适当的类别标签;2)回归一组系数使得最大化检测框和目标框之间的交并比(IoU)或其它指标。最后,通过一个 NMS 过程移除冗余的边界框(对同一目标的重复检测)。
在这样的检测流程中,分类和定位被用不同的方法解决。具体来说,给定一个提议框(proposal),每个类别标签的概率可自然而然地用作该 proposal 的“分类置信度”,而边界框回归模块却只是预测了针对该 proposal 的变换系数,以拟合目标物体的位置。换而言之,这个流程缺失了“定位置信度”。定位置信度的缺失带来了两个缺点:
- 在抑制重复检测时,由于定位置信度的缺失,分类分数通常被用作检测框排名的指标。在图 1(a) 中,研究者展示了一组案例,其中有更高分类置信度的检测框却与其对应的目标物体有更小的重叠。就像 Gresham 著名的 “劣币驱逐良币”理论一样,分类置信度和定位准确度之间的不匹配可能导致定位更准确的边界框在 NMS 过程中反被更不准确的边界框抑制。
- 缺乏定位置信度使得被广泛使用的边界框回归方法缺少可解释性或可预测性。举个例子,之前的研究 [3] 报告了迭代式边界框回归的非单调性。也就是说,如果多次应用边界框回归,可能有损输入边界框的定位效果(见图 1(b))。


图 1:由缺乏定位置信度所造成的两个缺点的图示。
这些示例选自 MS-COCO minival。(a)分类置信度和定位准确度不对齐的示例。黄框表示真实目标框,红框和绿框都是 FPN 所得到的检测结果。定位置信度由研究者提出的 IoU-Net 计算得到。使用分类置信度作为排名指标,会导致定位更准确的边界框(绿框)在传统的 NMS 流程被错误地删去。(b)在迭代式边界框回归中非单调定位的示例。
设计思想
在这篇论文中,研究者引入了 IoU-Net,其能预测检测到的边界框和它们对应的真实目标框之间的 IoU,使得该网络能像其分类模块一样,对检测框的定位精确程度有所掌握。这种简单的预测IoU值能为研究者提供前述问题的新解决方案:
- IoU 是定位准确度的一个天然标准。研究者可以使用预测得到的 IoU 替代分类置信度作为 NMS 中的排名依据。这种技术被称为 IoU 引导式 NMS(IoU-guided NMS),可消除由误导性的分类置信度所造成的抑制错误。
- 研究者提出了一种基于优化的边界框修正流程,可与传统的基于回归的边界框修正方法分庭抗礼。在推理期间,预测得到的 IoU 可用作优化目标,也可作为定位置信度的可解释性指示量。研究者提出的精准 RoI 池化层(Precise RoI Pooling layer)让研究者可通过梯度上升求解 IoU 优化。研究者表明,相比于基于回归的方法,基于优化的边界框修正方法在实验中能实现定位准确度的单调提升。这种方法完全兼容并可整合进各种不同的基于 CNN 的检测器。


边界框修正图示:上行是传统方法的结果,下行是本文提出方法的结果。
目标定位
本节探讨了目标定位的两个缺点:分类置信度与定位精确度之间的不匹配以及非单调边界框回归。标准的 FPN 检测器在 MS-COCO trainval35k 上被训练以最为基线,并在 minival 上测试以供进一步研究。
分类&定位准确度不匹配
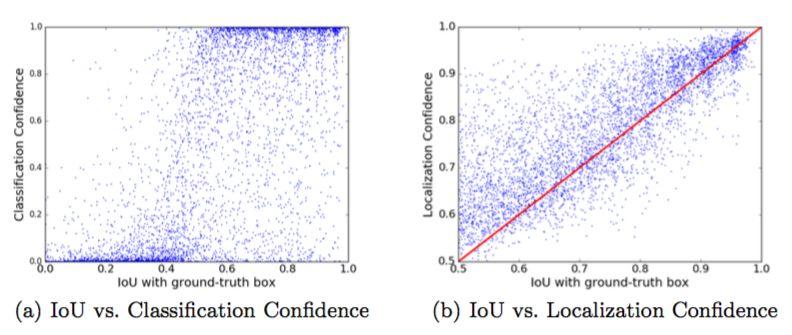
图 2:边界框与其对应目标框的 IoU 与分类/定位置信度之间的关系。
对那些与目标框的 IoU 高于 0.5 的检测框,其 Pearson 相关系数为 (a) 0.217 和 (b) 0.617。(a)分类置信度表示了一个边界框的类别,但不能被解读成定位准确度。(b)为了解决这个问题,研究者提出了 IoU-Net 来预测每个检测到的边界框的定位置信度,即其与对应的目标框的 IoU。

图3:经过 NMS 之后得到的正例边界框的数量,根据它们与对应的目标框之间的 IoU 分组。
在传统 NMS 中(蓝色条形图),定位准确的边界框中有很大一部分会被错误抑制,这是由分类置信度和定位准确度之间的不匹配造成的,而 IoU-guided NMS(黄色条形图)则能保留定位更准确的边界框。
非单调边界框回归

图 4:基于优化的与基于回归的 BBox 优化。
如上图所示,(a)表示在 FPN 中比较。当迭代式地应用回归时,检测结果的 AP(平均精度)首先会提升,但会在之后的迭代中快速降低。(b)表示在 Cascade R-CNN 中比较。迭代 0、1、2 表示 Cascade R-CNN 中的第 1、2、3 个回归阶段。在多轮回归之后,AP 稍有下降,而基于优化的方法则进一步将 AP 提高了 0.8%。
IoU-Net
为了定量地分析 IoU 预测的有效性,研究者首先提出用于训练 IoU 预测器的方法。接着分别展示了如何将 IoU 预测器用于 NMS 和边界框修正的方法。最后,研究者将 IoU 预测器整合进了 FPN 等现有的目标检测器中。
学习预测 IoU

图 5:IoU-Net 的完整架构。
在上图中,输入图像首先输入一个 FPN 骨干网络。然后 IoU 预测器读取这个 FPN 骨干网络的输出特征。研究者用 PrRoI 池化层替代了 RoI 池化层。这个 IoU 预测器与 R-CNN 分支有相似的结果。虚线框内的模块能构成一个单独的 IoU-Net。
IoU-guided NMS

算法 1:IoU-guided NMS。
在这个算法中,分类置信度和定位置信度是解开的(disentangled)。研究者使用定位置信度(预测得到的 IoU)来给所有被检测到的边界框排名,然后基于一个类似聚类的规则来更新分类置信度。
边界框修正作为优化过程

算法 2:基于优化的边界框修正。
精准 RoI 池化(Precise RoI Pooling)。研究者引入了精准 RoI 池化(简写成:PrRoI 池化)来助力研究者的边界框修正。其没有任何坐标量化,而且在边界框坐标上有连续梯度。给定 RoI/PrRoI 池化前的特征图 F(比如,来自 ResNet-50 中的 Conv4),设 wi,j 是该特征图上一个离散位置 (i,j) 处的特征。使用双线性插值,这个离散的特征图可以被视为在任意连续坐标 (x,y) 处都是连续的:
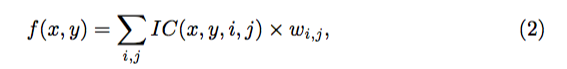
其中,

是插值系数。然后将 RoI 的一个 bin 表示为

,其中 (x_1,y_1) 和 (x_2,y_2) 分别是左上角和右下角的连续坐标。给定 bin 和特征图 F,研究者通过计算一个二阶积分来执行池化(比如平均池化):

为更便于理解,研究者在图 6 中可视化了 RoI 池化、RoI Align 和研究者的 PrRoI 池化:在传统的 RoI 池化中,连续坐标首先需要被量化(quantization),以计算该 bin 中激活的和;为了消除量化误差,在 RoI Align 中,会采样该 bin 中 N=4 个连续点,表示成 (a_i,b_i),而池化就是在这些采样的点上执行的。RoI Align 中的 N 是预定义的,而且不能根据 bin 的大小进行调整;与此不同,研究者提出的 PrRoI 池化是直接基于连续特征图计算二阶积分。

图 6:RoI 池化、RoI Align 和 PrRoI 池化的图示。
联合训练
这种 IoU 预测器可集成到标准的 FPN 流程中,以进行端到端的训练和推理。为了清楚说明,研究者将用于图像特征提取的 CNN 架构称为骨干(backbone),将应用于各个 RoI 的模块称为头(head)。
如图 5 所示,这个 IoU-Net 使用了 ResNet-FPN 作为骨干网络,其架构是自上而下的,可构建特征金字塔(feature pyramid)。FPN 能根据 RoI 的特征的比例从这个特征金字塔的不同层级提取这些 RoI 的特征。其中原来的 RoI 池化层被换成了精准 RoI 池化层。至于该网络的头,这个 IoU 预测器根据来自骨干网络的同一视觉特征而与 R-CNN 分支(包括分类和边界框回归)并行工作。
实验
研究者在有 80 个类别的 MS-COCO 检测数据集上进行了实验。具体来讲,在 8 万张训练图像和 3.5 万张验证图像的并集(trainval35k)上训练了模型,并在包含 5000 张验证图像的集合(minival)上评估了模型。为验证该方法,研究者与目标检测器分开而训练了一个独立的 IoU-Net(没有 R-CNN 模块)。IoU-guided NMS 和基于优化的边界框修正被应用在了检测结果上。
IoU-guided NMS
表 1 总结了不同 NMS 方法的表现。尽管 Soft-NMS 能保留更多边界框(其中没有真正的“抑制”),但 IoU-guided NMS 还能通过改善检测到的边界框的定位来提升结果。因此,在高 IoU 指标(比如 AP_90)上,IoU-guided NMS 显著优于基准方法。

表 1:IoU 引导式 NMS 与其它 NMS 方法的比较。通过保留定位准确的边界框,IoU-guided NMS 在具有高匹配IoU阈值的 AP(比如 AP_90)上的表现显著更优。

图 7:在匹配检测到的边界框与真实目标框的不同 IoU 阈值下,不同 NMS 方法的召回率曲线。
研究者提供了 No-NMS(不抑制边界框)作为召回率曲线的上限。研究者提出的 IoU-NMS 有更高的召回率,并且在高 IoU 阈值(比如 0.8)下能有效收窄与上限的差距。
基于优化的边界框修正
研究者提出的基于优化的边界框修正与大多数基于 CNN 的目标检测器都兼容,如表 2 所示。将这种边界框修正方法应用在原来的使用单独 IoU-Net 的流程之后还能通过更准确地定位目标而进一步提升表现。即使是对有三级边界框回归运算的 Cascade R-CNN,这种改进方法能进一步将 AP_90 提升 2.8%,将整体 AP 提升 0.8%。

表 2:基于优化的边界框修正能进一步提升多种基于 CNN 的目标检测器的表现。
联合优化
IoU-Net 可与目标检测框架一起并行地端到端优化。研究者发现,将 IoU 预测器添加到网络中有助于网络学习更具判别性的特征,这能分别将 ResNet50-FPN 和 ResNet101-FPN 的整体 AP 提升 0.6% 和 0.4%。IoU-guided NMS 和边界框修正还能进一步提升表现。研究者使用 ResNet101-FPN 得到了 40.6% 的 AP,相比而言基准为 38.5%,提升了 2.1%。表 4 给出了推理速度,表明 IoU-Net 可在计算成本承受范围之内实现检测水平的提升。
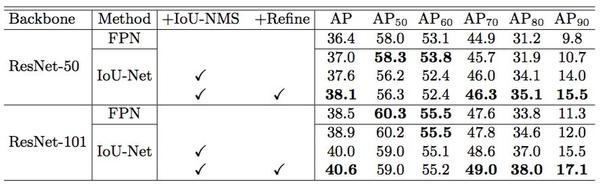
表 3:在 MS-COCO 上的最终实验结果。IoU-Net 表示嵌入IoU预测器的 ResNet-FPN。在这个 FPN 基准上,研究者实现了约 2% 的 AP 提升。

表 4:多种目标检测器在单个 TITAN X GPU 上得到的推理速度。这些模型都有一样的骨干网络 ResNet50-FPN。输入分辨率为 1200x800。所有超参数设置相同。
结论
本文提出一种用于准确目标定位的全新网络架构 IoU-Net。通过学习预测与对应真实目标的 IoU,IoU-Net 可检测到的边界框的“定位置信度”,实现一种 IoU-guided NMS 流程,从而防止定位更准确的边界框被抑制。IoU-Net 很直观,可轻松集成到多种不同的检测模型中,大幅提升定位准确度。MS-COCO 实验结果表明了该方法的有效性和实际应用潜力。
从学术研究的角度,本文指出现代检测流程中存在分类置信度和定位置信度不匹配的问题。更进一步,研究者将边界框修正问题重定义为一个全新的优化问题,并提出优于基于回归方法的解决方案。研究者希望这些新视角可以启迪未来的目标检测工作。
参考文献
- Cai, Z., Vasconcelos, N.: Cascade r-cnn: Delving intohigh qualityobject detection. arXiv preprint arXiv:1712.00726 (2017)
- Lin, T.Y., Doll ́ar, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
- He,K.,Gkioxari,G.,Dolla ́r,P.,Girshick,R.:Maskr-cnn.In:TheIEEEInternationalConference on Computer Vision (ICCV) (2017)
- Lin, T.Y., Doll ́ar, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017)
- Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time objectdetec- tionwith region proposal networks. In: Advances in neural information processing systems. pp. 91–99 (2015)
- Wang, X., Xiao, T., Jiang, Y., Shao, S., Sun, J., Shen, C.: Repulsion loss: Detecting pedestrians in a crowd. arXiv preprint arXiv:1711.07752 (2017)
往期解














 1186
1186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









