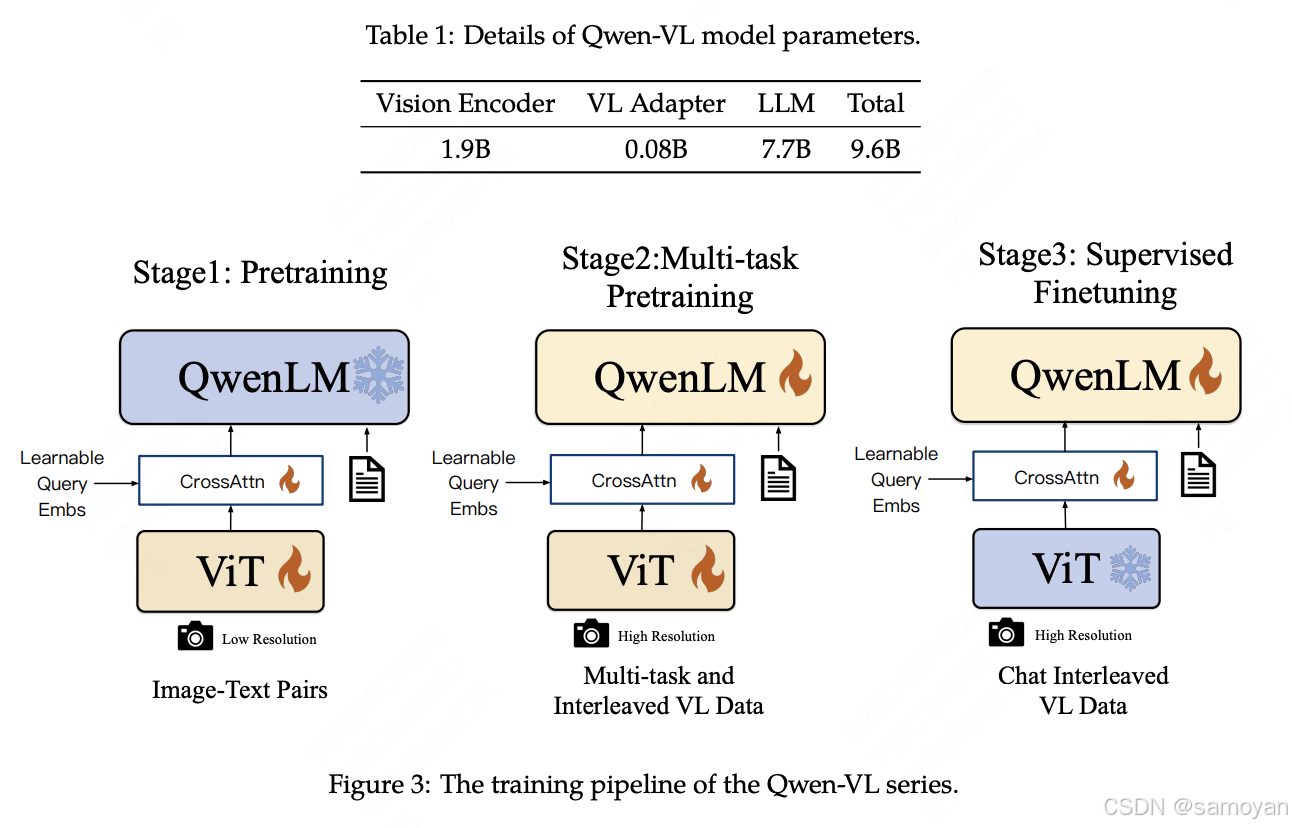
 Qwen-VL
Qwen-VL
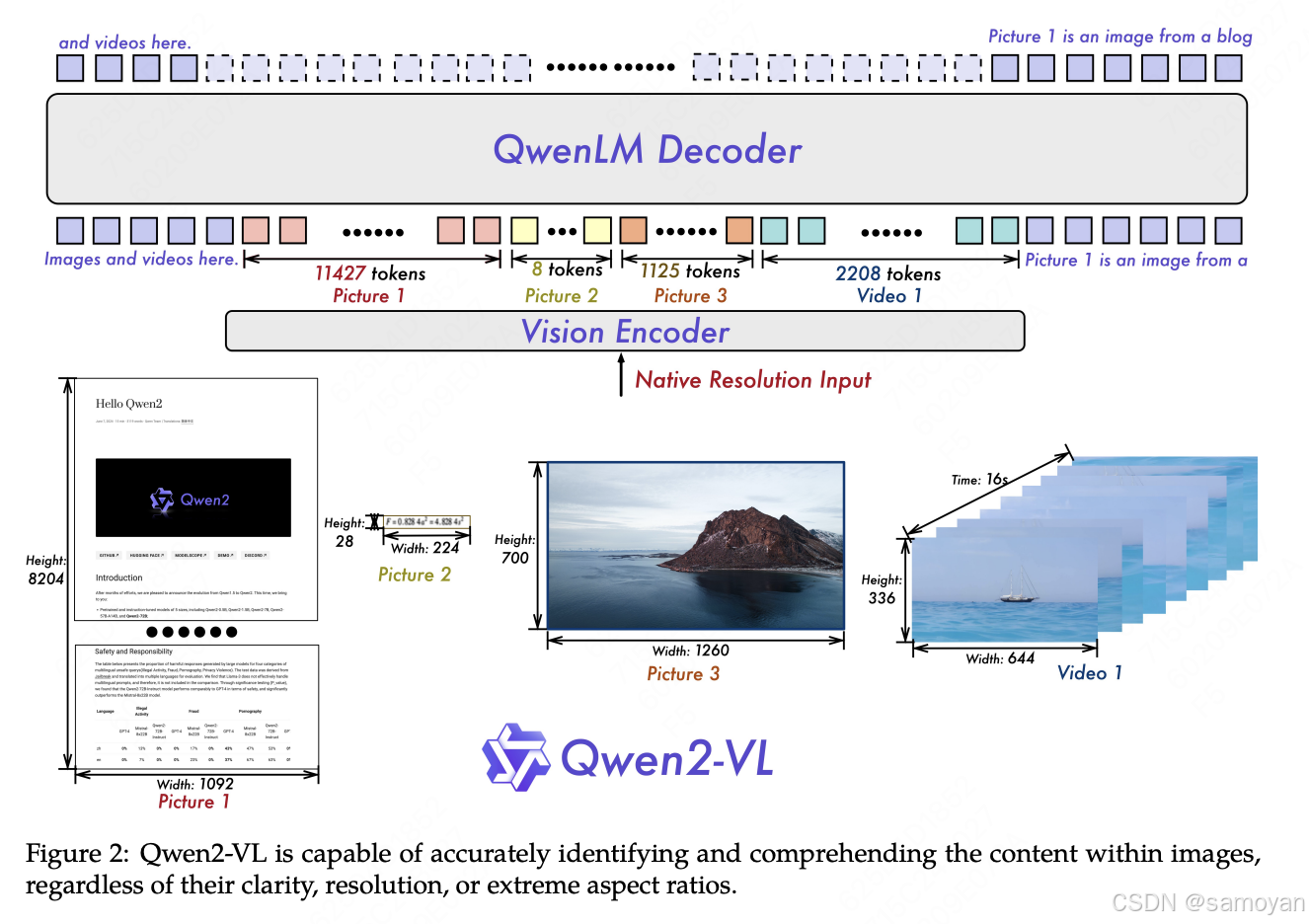 Qwen2-VL
Qwen2-VL
1. 模型结构对比
Qwen 的模型结构
- 核心组件:
- 大语言模型:基于 Qwen-7B 的预训练权重。
- 视觉编码器:使用 Openclip 的 ViT-bigG(Vision Transformer)。
- 视觉语言适配器:单层交叉注意力模块,用于压缩长图像特征序列。
- 特点:
- 固定分辨率输入(224×224)。
- 通过绝对位置编码处理图像位置信息。
- 仅支持图像输入,不支持视频。
Qwen2 的模型结构
- 核心组件:
- 大语言模型:基于 Qwen2 系列,参数规模更大(如 Qwen2-VL-72B)。
- 视觉编码器:675M 参数的 ViT,支持图像和视频输入。
- 多模态旋转位置嵌入(M-RoPE):分解位置编码为时间、高度、宽度三部分,增强多模态位置建模。
- 朴素动态分辨率支持:处理任意分辨率图像,动态生成视觉标记。
- 特点:
- 动态分辨率输入(如 448×448),减少信息损失。
- 支持视频处理(3D 卷积和帧采样)。
- 引入 MLP 层压缩视觉标记,提升效率。
模型结构异同
| 特性 | Qwen | Qwen2 |
|---|
| 视觉编码器 | ViT-bigG | 675M 参数的 ViT |
| 语言模型 | Qwen-7B | Qwen2 系列(更大规模) |
| 位置编码 | 绝对位置编码 | 2D-RoPE 与 M-RoPE |
| 输入支持 | 图像 | 图像 + 视频 |
| 动态分辨率 | 不支持 | 支持(任意分辨率) |
| 视频处理 | 不支持 | 支持(3D 卷积、帧采样) |
| 标记压缩 | 单层交叉注意力模块 | MLP 压缩(2×2 标记合并) |
2. 训练方式对比
Qwen 的训练方式
- 训练阶段:
- 预训练:冻结语言模型,优化视觉编码器和适配器,使用 14 亿图像-文本对。
- 多任务预训练:解冻所有参数,引入高质量数据(VQA、OCR 等)。
- 指令微调:冻结视觉编码器,优化语言模型和适配器,使用 35 万指令数据。
- 特点:
- 固定分辨率训练(224×224)。
- 强调图像-文本对齐,未涉及视频数据。
Qwen2 的训练方式
- 训练阶段:
- ViT 训练:专注于视觉编码器的训练,使用大规模图像-文本对。
- 全面训练:解冻所有参数,整合多模态数据(视频、OCR、视觉问答等)。
- 指令微调:锁定 ViT 参数,优化语言模型,引入多模态对话数据(视频流、多图对比)。
- 特点:
- 动态分辨率训练(如 448×448)。
- 混合图像和视频数据,支持长视频处理(总标记数限制为 16384)。
- 使用 3D 并行策略(数据并行、张量并行、流水线并行)优化训练效率。
训练方式异同
| 特性 | Qwen | Qwen2 |
|---|
| 训练阶段 | 三阶段(预训练、多任务、微调) | 三阶段(ViT 训练、全面训练、微调) |
| 分辨率调整 | 固定分辨率(224→384) | 动态分辨率(224→448) |
| 视频训练 | 不支持 | 支持(视频帧采样、3D 卷积) |
| 并行策略 | 基础并行 | 3D 并行 + 序列并行 |
| 数据规模 | 14 亿图像-文本对 | 1.4 万亿标记(含图像和视频) |
3. 数据组成与处理对比
Qwen 的数据处理
- 数据集:
- 主要来源:LAION-en、LAION-zh、DataComp、Coyo、CC12M、CC3M 等。
- 类型:图像-文本对(77.3% 英文,22.7% 中文)。
- 处理方式:
- 图像分辨率固定为 224×224。
- 使用特殊标记(
<img>、</img>)区分图像特征。 - 边界框归一化为字符串格式(
(X,Y) 坐标),并用 <box> 标记标注。
Qwen2 的数据处理
- 数据集:
- 扩展数据:视频对话、视频流、多图像对比、OCR 合成数据。
- 类型:图像-文本对 + 视频-文本对 + 多模态交互数据。
- 处理方式:
- 动态分辨率图像处理(如 448×448)。
- 视频帧采样(2 帧/秒),3D 卷积处理。
- 使用特殊标记(
<|vision_start|>、<|box_start|>)区分多模态输入。 - 边界框与文本关联标记(
<ref>、</ref>)。
数据处理异同
| 特性 | Qwen | Qwen2 |
|---|
| 数据类型 | 图像-文本对 | 图像 + 视频 + 多模态交互 |
| 分辨率处理 | 固定分辨率 | 动态分辨率 |
| 视频支持 | 不支持 | 支持(帧采样、3D 卷积) |
| 标记机制 | 基础视觉-文本标记 | 多模态标记(视频、边界框、交互) |
| 数据规模 | 14 亿图像-文本对 | 1.4 万亿标记(含视频) |
总结
模型结构
- Qwen:基础多模态架构,专注于图像-文本对齐,结构简单但功能明确。
- Qwen2:全面升级,支持动态分辨率、视频输入和多模态位置编码(M-RoPE),显著提升灵活性和任务覆盖范围。
训练方式
- Qwen:传统三阶段训练,强调图像-文本对齐。
- Qwen2:引入视频训练和动态分辨率优化,结合 3D 并行策略,显著提升训练效率和模型容量。
数据处理
- Qwen:以静态图像-文本对为主,处理流程标准化。
- Qwen2:扩展至视频和多模态交互数据,支持动态输入和复杂任务(如视觉代理、多图推理)。
Qwen2 在 Qwen 的基础上,通过动态分辨率、视频支持、多模态位置编码和高效并行训练策略,实现了从单一图像处理到复杂多模态任务的全面升级,尤其在视频理解和交互能力上表现突出。


























 5277
5277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











