







大模型如火如荼,研究者们已经不再满足于基本文本的大语言模型(LLM, Large Language Model),AI领域的热点正逐步向多模态转移,具备多模态能力的多模态大型语言模型(MM(Multi-Modal)-LLM)就成了一个备受关注的研究主题。在BLIP算法的基础上,Salesforce提出的多模态预训练模型BLIP-2(Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models),是BLIP系列的第二篇研究论文,通过有效利用现有的预训练图像编码器和大型语言模型来降低视觉-语言预训练模型的成本和计算需求。
框架
BLIP-2为多模态任务的研究提供了新的思路和方法,预训练策略实现了在降低训练成本的同时提高性能,整体使用如下的结构(虚线框对应两个阶段:表示学习与生成学习):
● 图像编码器:图像作为输入,输出图像的视觉特征。
● Q-Former:接收文本和图像的视觉特征,结合查询向量进行融合,学习与文本相近的视觉特征,输出LLM能够理解的视觉表示。
● 大语言模型LLM:接收Q-Former输出的视觉表示,生成对应的文本。
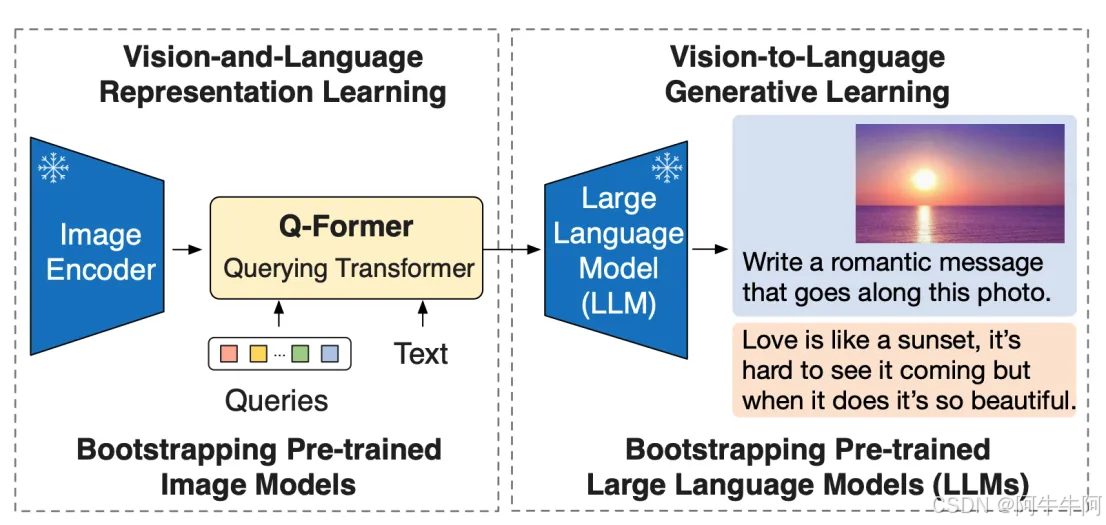
模型
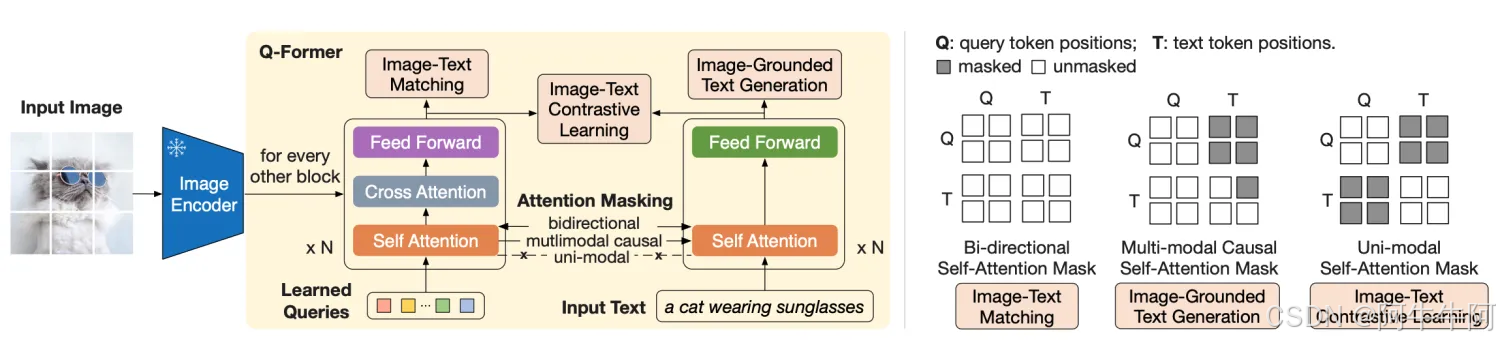
- 冻结预训练模型:BLIP-2在预训练阶段冻结了预训练的图像编码器和大型语言模型(LLM),以减少计算量并防止灾难性遗忘问题。
- 两阶段预训练:
○ 第一阶段:从冻结的图像编码器中引导视觉-语言表征学习。
○ 第二阶段:基于冻结的语言模型,进行视觉到语言的生成学习。 - Querying Transformer(Q-Former):BLIP-2引入了一个轻量级的Q-Former来弥合冻结的图像编码器和LLM之间的模态差距。Q-Former通过两阶段预训练策略进行预训练,以桥接视觉特征和文本特征。这个过程中引入了三个优化目标
a. 图像-文本的匹配:通过图像与对应描述词的pair对进行有监督的二分类训练,实现任务相关的训练
b. 基于图像的文本生成:图像与文本的预训练冻结,所以将当前输入query作attention之后的图像与文本进行交互学习
c. 图像与文本的对比学习:学习两种模态的对齐 - 视觉-语言任务的性能:BLIP-2在多种视觉-语言任务上达到了最先进的性能(SOTA),例如在zero-shot VQAv2上超越了Flamingo80B 8.7%,同时显著减少了可训练参数的数量。
- 零样本图像到文本生成:BLIP-2可以根据自然语言指令进行零样本图像到文本的生成能力。
小结
BLIP-2的特点可以归纳如下:
(1)使用预训练并冻结模型,以减少端到端的大模型训练时的运算量(FLOPS)
(2)预训练的模型冻结,通过引入可训练的Q-Former实现图像与文本的对齐学习
(3)基于图像的文本生成模块,使得BLIP-2具备好的zero-shot图像生成文本能力
最后,附BLIP-2的原文:https://arxiv.org/pdf/2301.12597,感兴趣的读者可以深入阅读。

















 2508
2508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









