









上次在聊 autoML 框架时顺带提了一下对于表格类数据(也是商业类问题的主要数据形式)表现较好的模型的选择,最近正好在 Twitter 上看到几篇不错的文章,就来稍微展开讨论一下。以我目前的认知,表格类数据的主流模型选择就是树模型(包括 GBDT,随机森林等)和 NN(从 MLP 到各种复杂变种)两类。本文也主要来阐述和对比这两类模型。
关于 Kaggle 比赛的分析
如果仅考虑模型的精度效果,那么 Kaggle 比赛绝对是最好的检验方式之一。这方面推荐砍手豪大佬的两个系列文章:
总结来看就是 90%以上的比赛中,树模型都比 NN 模型的表现更好,如果考虑一下有些大佬特地限定了自己只用 NN 来打比赛,放开来看的话这个比例可能还会更高……
对于这个结果的原因,大佬也做了些分析,包括:
- 数据特性,比如少量 category 特征情况下,手工特征+树模型往往表现优异,而 category 特征多且贡献度比较平均时,神经网络的自动特征交叉,embedding 学习的优势就得以体现。
- 评估指标,一些不好求二阶导的 metric 就容易对 xgboost 这类模型的优化造成一定困扰,例如作者提到了 web traffic forecasting 里用了 SMAPE,所以最终 NN 网络获得了冠军。
- 归纳偏置,一个最直观的理解是简单的线性相关规律,用 NN 只需要 fit 一个斜率+截距就好了,而树模型则可能需要构建一棵比较深的树才能达到类似效果。但是(此处为引用)NN 缺少全局的 feature selection 以及 gain。所以当小部分列包含当大部分有意义的信息的时候,lgb 因为做能够 feature selection,重点分割有价值的列,忽略无价值的列,因此效果较好。
个人在实践过程中也感觉到了这些原因,尤其是上面的第三点。现实商业问题在数据生成的逻辑上来说,基本就是那种少量特征贡献了主要的 predictive power 的情况,举例来说:
- 购买商品,我们可能主要考虑 3-5 个因素就会促成交易,比如价格,品质,需求满足程度。
- 信用评估,履约历史,经济状况,受教育程度等几个因素也基本可以判断一个人的履约可能。
- 反过来考虑下图片识别,我们很难说选出几个重要的 pixel 就能判断一个图片的种类是什么。
此外,树模型的决策逻辑对于真实世界中的各种数据异常也有比较好的容忍度,而神经网络则经常需要比较精细的调整各种正则化参数来防止模型对异常数据过拟合。结合看来,树模型作为 Tabular 问题的 SOTA 方案也就很顺理成章了。
NN 在 Tabular 问题上的创新
由于深度学习这几年在其它问题上的成功,还是有不少研究者投入了一些精力在 NN 模型在 Tabular 问题的优化上,例如 TabNN,GrowNet,从推荐系统衍生出来的 Wide and Deep,时序问题的 DeepAR 等等。但经过我们的大量评估尝试,发现效果能比较稳定达到接近树模型效果的,基本都是模拟了树模型特性的 NN 模型。
TabNet
一个比较典型的例子是 TabNet,解读可以参考这篇 知乎文章。其中一个比较特别的设计是用神经网络来模拟决策树的特征选择和条件判断操作:
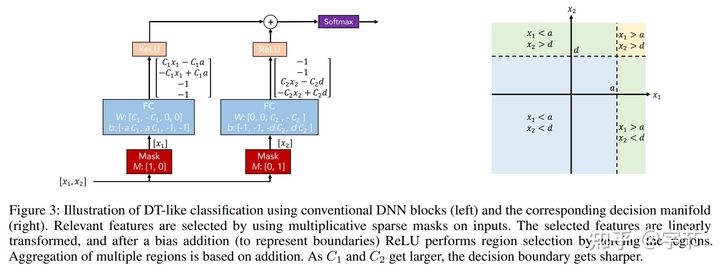
然后在此基础上形成了多步模型预测框架,上一步的输出会影响到下一步的特征选择操作,跟 gradient boosting 也有一些相似。与 TabNet 类似的还有 NODE,从原理上看感觉更接近随机森林,我们试用下来效果也不错。
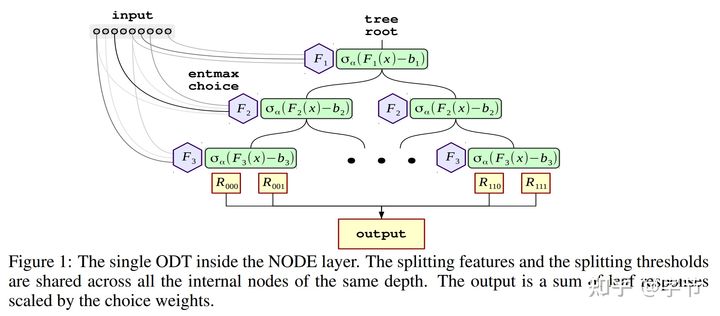
TFT
同样来自 Google Cloud AI 的一篇工作,主要针对时序问题。他们也同样精心设计了 variable selection network,在特征选择的基础上再去 apply 时序问题常见的操作手法如 LSTM,Transformer 等。具体说明可以参考 TFT 的论文。
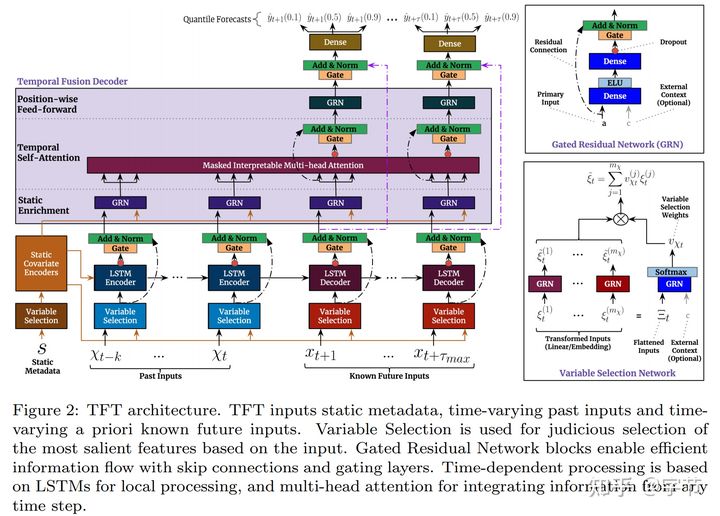
虽然模型结构比较复杂,但在我们的实际尝试中,TFT 的效果要比 DeepAR 稳定不少,可以达到接近树模型的精度效果。
树模型 vs NN 性能比拼
在尝试这些 NN 的创新模型过程中,我们发现了一个不错的框架:pytorch-widedeep。作者通过一个比较统一的框架,实现了在各种 NN 上跑 Tabular 任务:
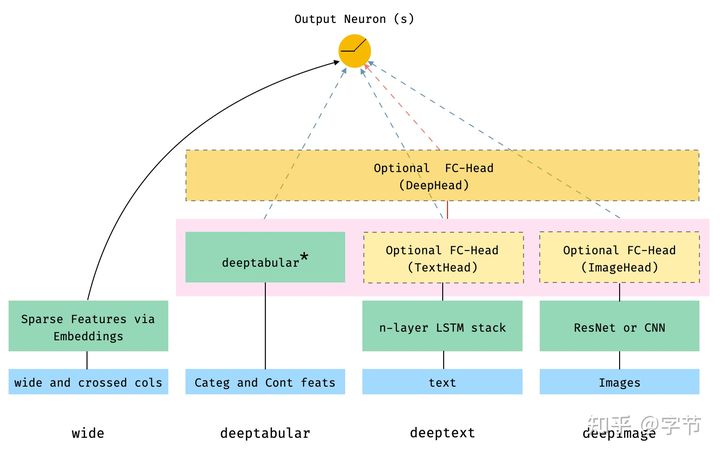
相信熟悉 wide and deep 架构的同学应该对这个图很好理解,主要就是在 deep 部分改成了适用于 tabular 任务的各种结构。以 deeptabular 模块为例,作者实现了:
- TabMlp
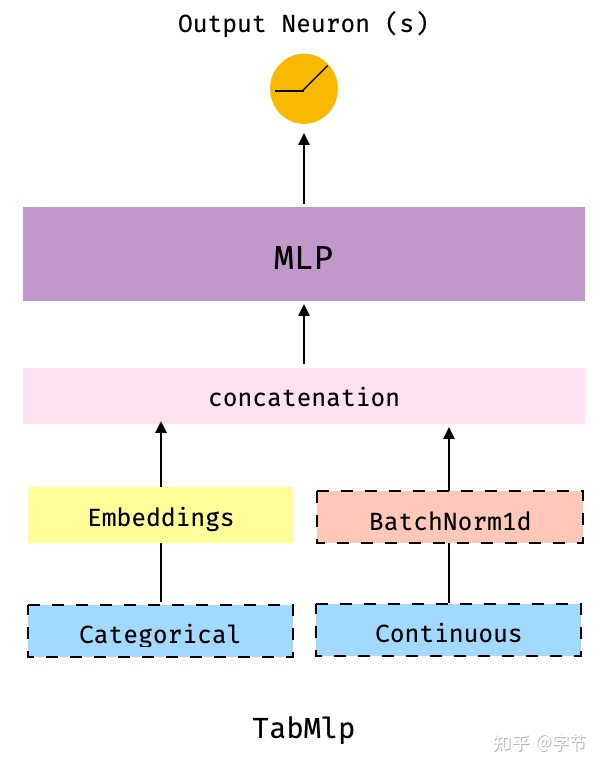
比较常规的 embedding 处理类别变量,和连续型变量一起再进入到 MLP 层的操作,与 fast.ai 中的 TabularLearner 结构非常类似。
- TabResnet
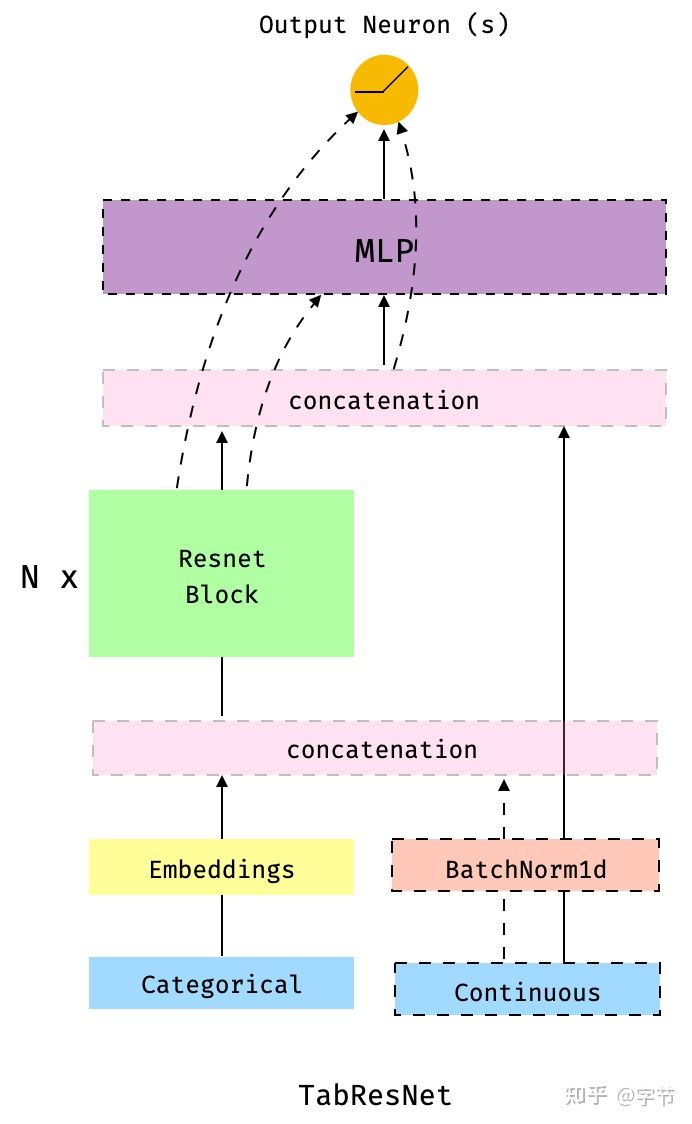
在 TabMlp 的基础上增加了 residual block,这个应该大家也很熟悉了,AutoGluon Tabular 中的 NN 也使用了类似的 skip-connection 机制。
- TabTransformer
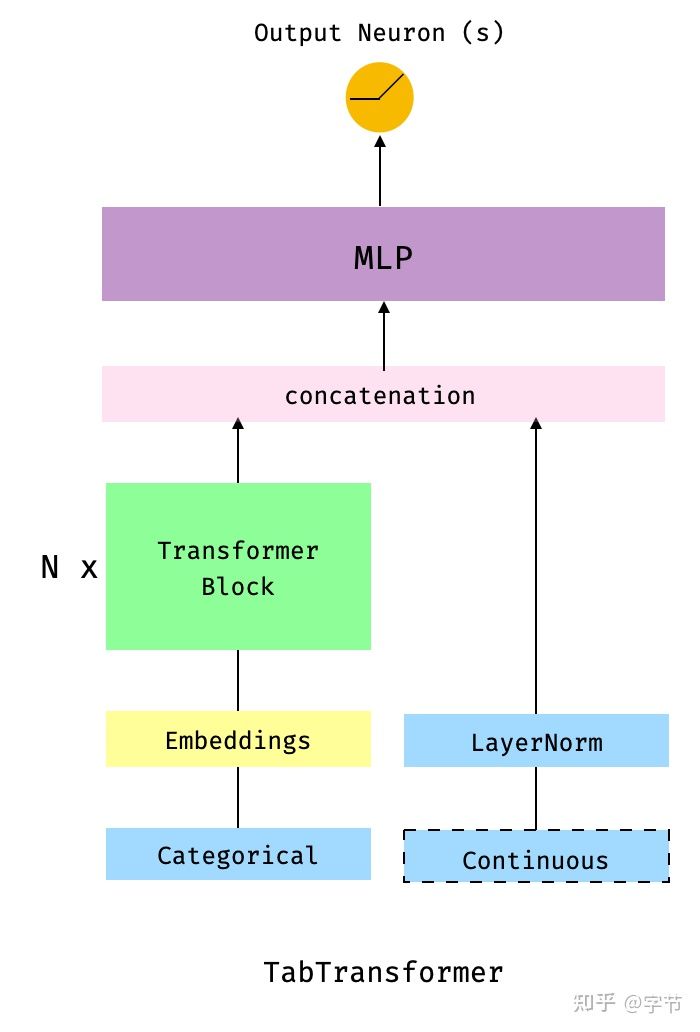
在 TabMlp 的基础上增加了 transformer block,来自 Amazon 的这篇论文。
可以看到这些模型都是相对“正统”的深度学习模型,并没有特意去模仿树模型的机制。目前作者也已经把表现比较好的 TabNet 包括了进来,计划后续还会增加比较新的 SAINT 等模型结构。
顺带一提,对于 deeptext 和 deepimage,作者采用了经典的 LSTM 和 ResNet 结构。
性能对比
比较有意思的是,这个框架作者最近发了一篇 文章,用他实现的各种 NN 模型来跟 LightGBM(yyds!) 做对比。
作者选用了 4 个表格数据,分别是:
- Adult Census (binary classification)
- Bank Marketing (binary classification)
- NYC taxi ride duration (regression)
- Facebook Comment Volume (regression)
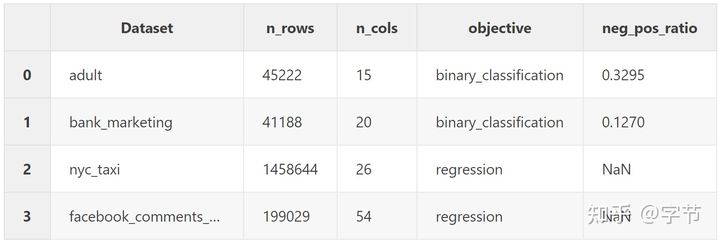
针对每一个数据集,作者都对比了 TabMlp,TabResnet,TabTransformer,TabNet 和 LightGBM 的训练时长,模型精度效果。而且每一个任务,作者都尝试了多种超参组合,总共做了超过 1500 个实验,可以说是非常的用心了,感兴趣的同学也可以从文中学习作者的具体调参技巧。
我们来看下四个数据集上的结果对比。
- Adult Census Dataset
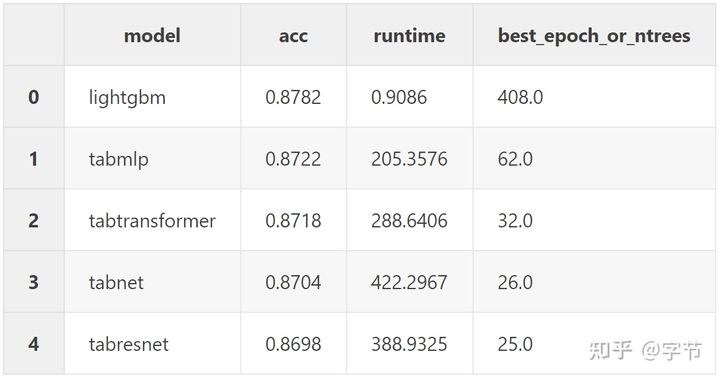
- Bank Marketing Dataset
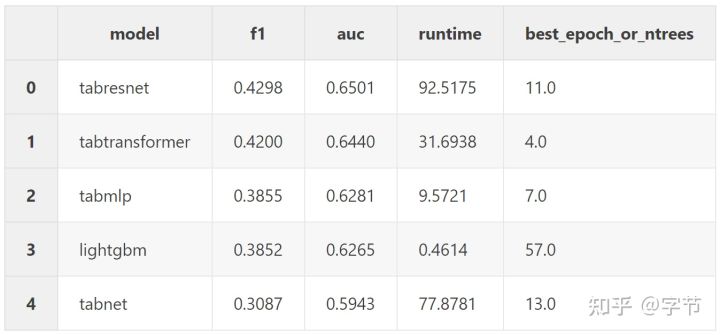
- NYC Taxi trip duration
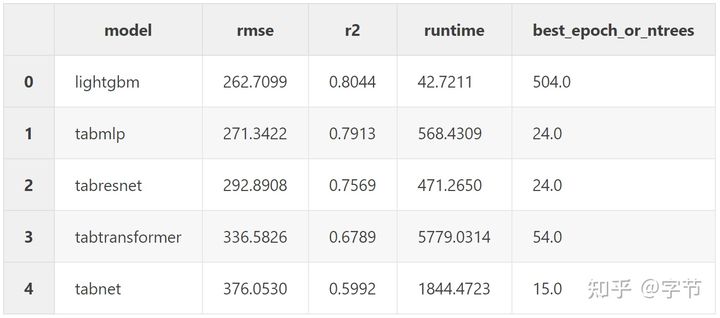
- Facebook comments volume
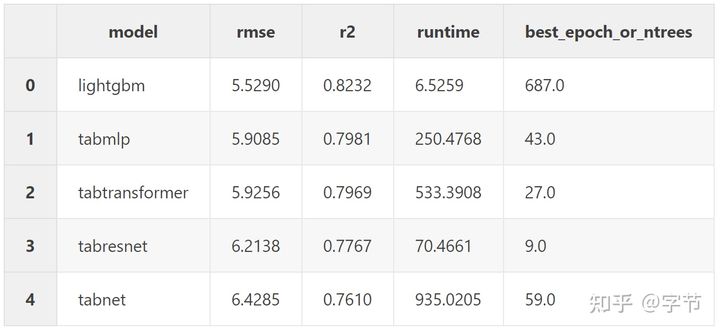
从精度来看,除了第二个数据集外(并不是数据量最大的),lgb 都打败了所有的 NN 模型。从训练时间上来看,注意这里所有 NN 模型都是在 Amazon EC2 的 p2.xlarge 上执行的(4 核 60G 内存),而 lgb 则是在作者 Mid 2015 的 Macbook 上执行,在 NN 模型利用了更强大的硬件情况下,lgb 仍然达到了 NN 模型 10-400 倍的性能提升。也难怪作者最后的结论是:
LightGBM wins, and there was never a fight
在这种运行性能和模型精度的优势下,对于工程化产品化考量来说几乎是毫无疑问应该选择树模型为首选。甚至在大多数比赛中,树模型的这个训练迭代速度,可以让你在单位时间内做 10 倍甚至 100 倍更多的实验,对于取得更好的成绩来说确定性会高不少。
另外还有一篇最近来自 Intel 的论文 Tabular Data: Deep Learning is Not All You Need,里面也做了类似的对比,同样每个模型都用了 HyperOpt 来搜索超参:
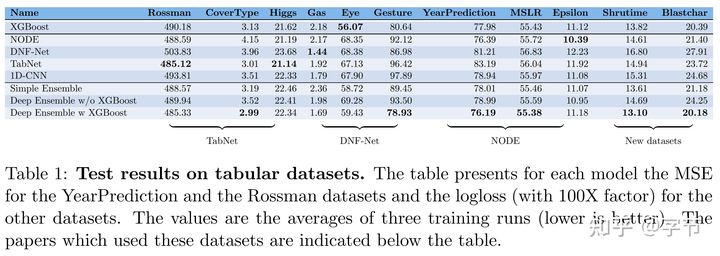
作者得出的结论是,如果不是在 NN 论文中使用到的数据集,比如 TabNet 在文中用了前三个数据集,看起来表现还可以,但除此之外的数据集,全部都输给了 Xgboost。其它模型大多也是类似情况,体现出了树模型强大的稳定性,易于优化训练的优点。
另外一个结论是如果把树模型和 NN 模型进行 ensemble,一般能获得最好的总体精度。说明这两类模型特性的差别能让两者在一定程度上实现互补。
NN 的优势
这么看来,是不是我们就根本没有必要在 Tabular 任务中尝试 NN 模型了呢?其实也不全是,NN 还是有很多独有的优势,这里我们列举一部分:
- Embedding 学习,NN 模型可以实现表达学习,相比树模型比较单一的 target encoding 等手段来说,可以实现更加丰富的类别特征提取。而且这些 embedding 还可以应用于其它场景任务,例如相似度计算召回,或者像TabNet里应用于自监督学习等。
- 灵活的 loss 设计,在业务上有时会出现一些复杂的优化目标,或者是多任务优化,这时候 NN 的 loss 设计就会方便很多,而树模型一般需要写 custom loss 进行一些近似操作等,效果上可能会不如 NN 来的直接。
- 多模态,当输入数据包括文本,图像等非结构化数据时,NN 的模型结构能比较方便的引入这些多模态数据进行联合建模优化,树模型的话就只能先利用 NN 的表达学习来提取特征,再进行二阶段的训练,pipeline 会更加复杂。
- 在线/增量学习,NN 模型的增量学习非常的自然,而树模型虽然也有一些方法支持(比如 lgb 的 update 和 refit),但从模型机制上来说就不太适合应用这类方法。同样 transfer learning 之类的感觉也很难在树模型上实现。
- 分布式训练,由于深度学习的流行,在大规模的数据量和模型参数情况下进行分布式训练也成为了一个热门研究方向,所以这方面 NN 模型框架积累的经验和方法目前来看要比树模型丰富很多。
- 专用软硬件加速,虽然树模型也有 GPU 优化版,但早年试用下来感觉没啥性能提升(不知道现在有没有变化),当然也可能因为树模型本身训练就足够快了,没有多少动力深入这个方向的开发。
- 巨量参数下的表达能力,GPT-3 这类模型给我们带来的震撼还是相当强烈的,在海量数据下,海量模型参数的加持,海量算力的配合,能持续提升各种 metrics,这才是 DL 时代的弄潮儿(误)。
未来我们如何能更好的利用和结合这两者模型的优势,感觉会是一个挺有意思的方向,欢迎有想法的同学来一起讨论这个话题 :)
今天的分享就到这里啦。Happy hacking!

















 74
74

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









