






一、引言
论文: SuperPoint: Self-Supervised Interest Point Detection and Description
作者: Magic Leap
代码: SuperPoint
特点: 提出Homographic Adaptation策略,提升模型从虚拟数据迁移到真实数据的表现;提出自监督训练的双分支网络框架,无需人工标记真实数据的关键点并能够同时实现关键点检测和描述符生成。
二、框架
SuperPoint的整体流程包括如下三个部分:
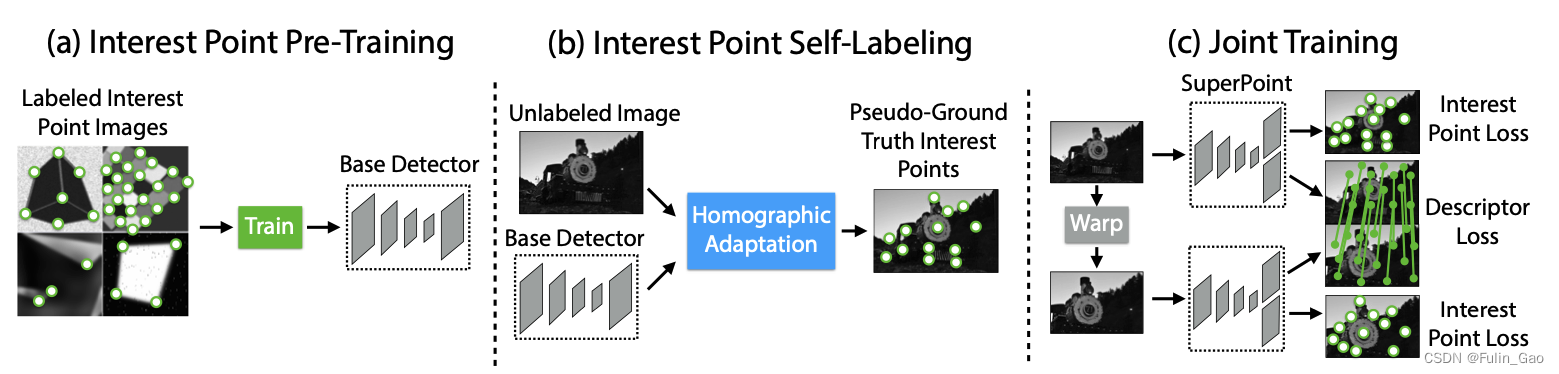
(a)使用有标签的虚拟三维物体数据集进行预训练,获取一个基础的关键点检测器。
(b)使用预训练好的关键点检测器对经过Homographic Adaptation中各种变换后的无标签的真实数据集进行关键点预测,然后整合所有预测得到一个关键点集合。
(c)使用整合出的关键点集合作为伪标签同时训练网络的关键点和描述符分支,获取一个可以同时预测关键点和描述符的模型。
2.1 关键点预训练
进行真实数据的关键点手工标注费时费力,作者先使用虚拟数据集进行预训练,该数据集是自己生成的、有关键点标签的,具有图形简单、数量多、关键点明确等特点。
预训练的关键点检测模型被称为MagicPoint,检测流程如下:
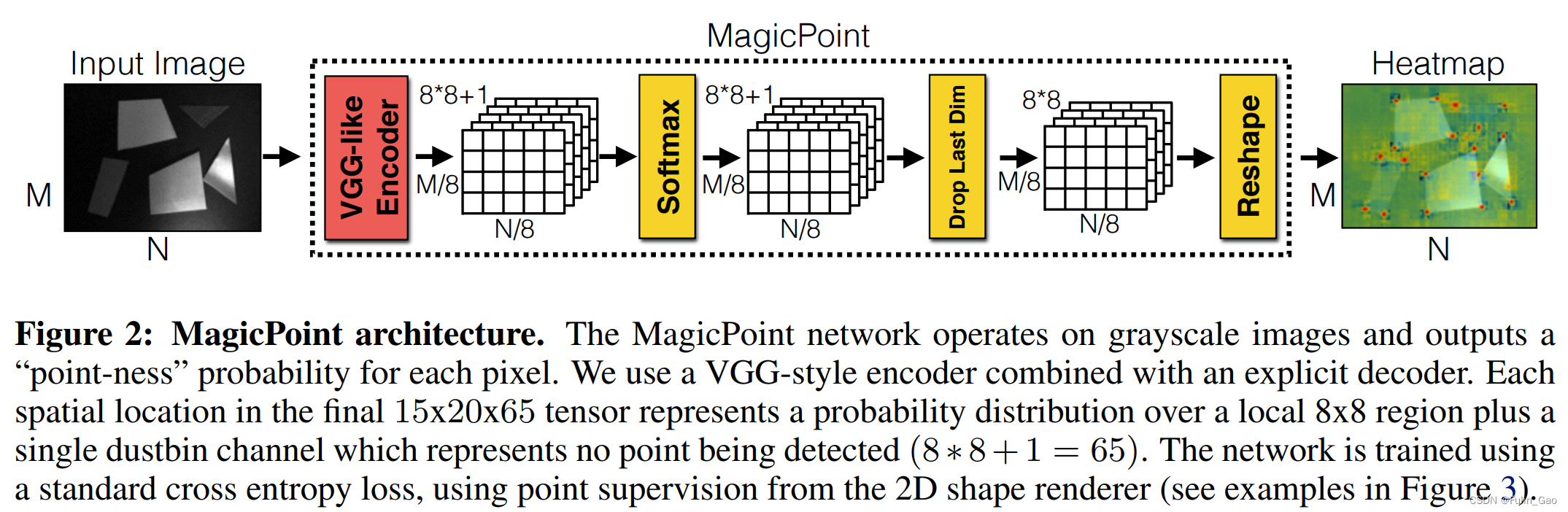
首先,该模型输入的是灰度图,所有输入的维度都要先从彩色的 M × N × 3 M\times N\times 3 M×N×3转为灰度的 M × N × 1 M\times N\times 1 M×N×1。
其次,是MagicPoint模型,其结构图如下:
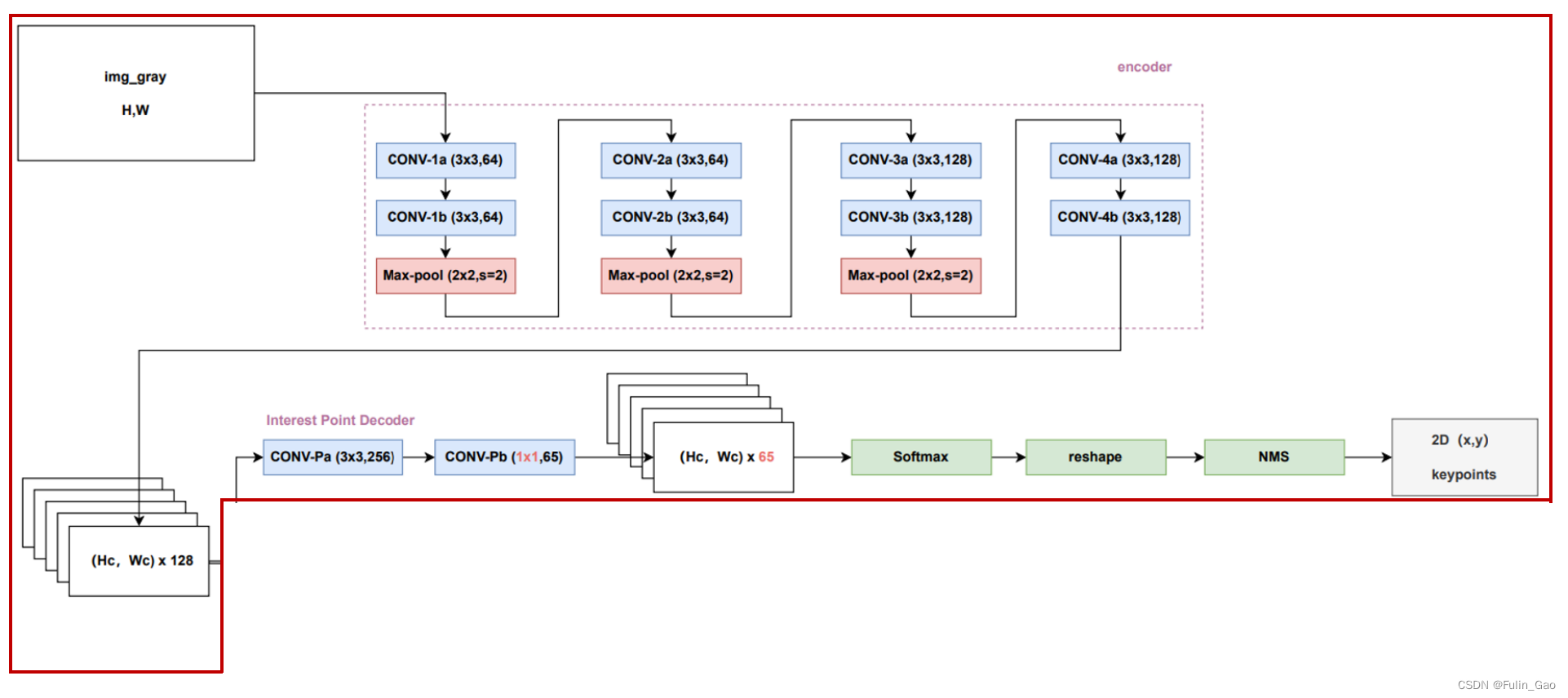
其中,编码器部分主要包括卷积和最大池化操作,多次卷积使输出通道数从1变为128,三次最大池化使输出宽高变为输入宽高的 1 / 8 1/8 1/8(每次缩小 1 / 2 1/2 1/2)。因此,编码器的输出维度为 H c × W c × 128 H_c\times W_c\times 128 Hc×Wc×128( H c = H / 8 , W c = W / 8 H_c=H/8,W_c=W/8 Hc=H/8,Wc=W/8),此时该特征图上一个像素点又称一个cell。
特征图的宽高均缩小了8倍,但我们希望检测出的关键点坐标处于原图尺度上,所以作者通过两次卷积操作将特征图的通道数从128变为了65。65包括 8 × 8 8\times 8 8×8个像素点和1个dustbin点。 8 × 8 8\times 8 8×8是因为还原至原图尺寸时当前的一个像素点应该对应原图的64个像素点。额外的1个dustbin点对应非关键像素点,当剩余64个像素点均不是关键点时它能保证结果的正确性。
具体来说, H c × W c × 65 H_c\times W_c\times 65 Hc×Wc×65的特征图会对当前每个cell上的65个通道值进行softmax,在去掉最后的dustbin点后进行reshape,经过softmax后的64个值按8个一行依次放置便还原出了与原图对应的64个像素点。
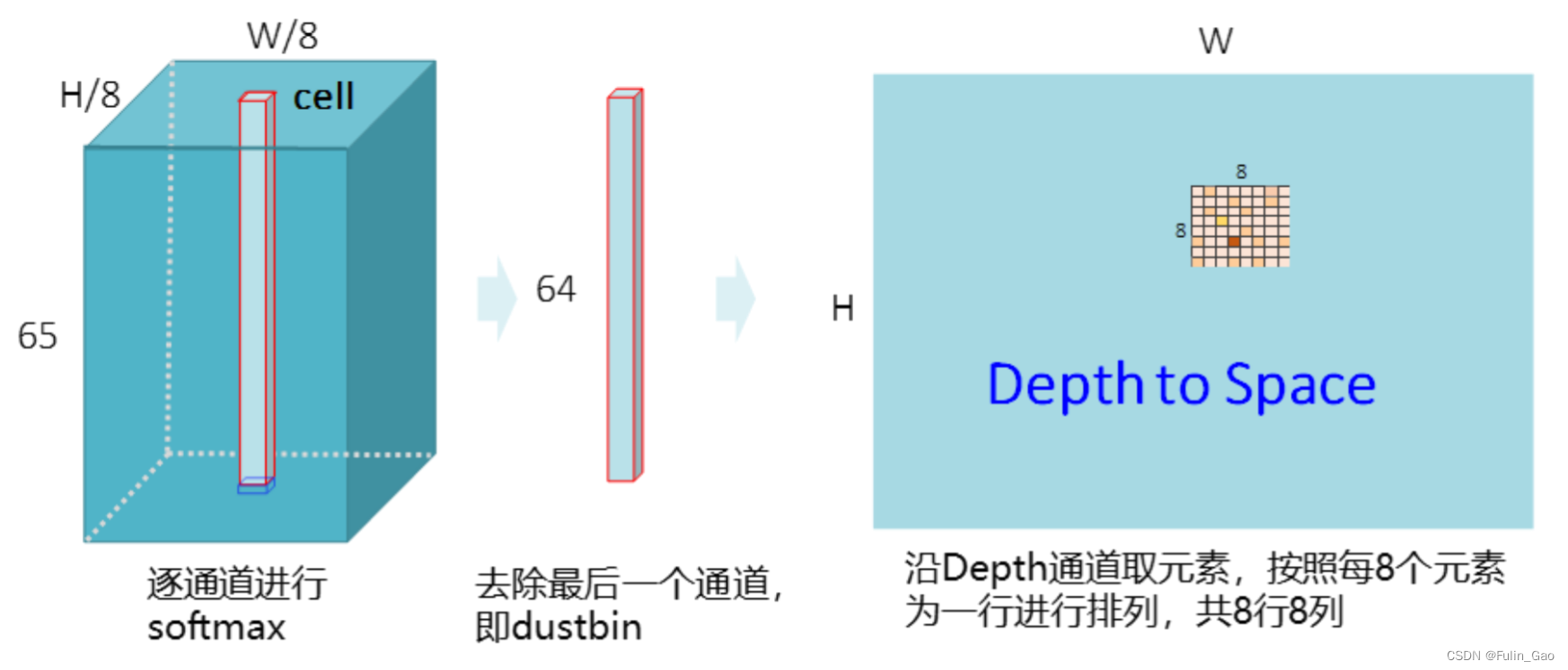
如果没有dustbin点,这64个通道值中必然会有较大的值出现,经过softmax后这些值就会更加突出,无关键点的情况就永远得不到表达。
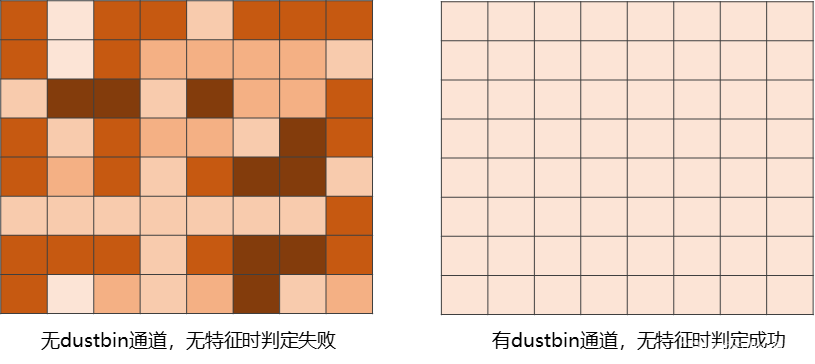
如上图所示,有了dustbin点,64个像素点都不是关键点时dustbin点的值会很大,softmax并去掉dustbin点后剩下的64个通道值都很小,从而可以正确地表达无关键点的情况。
NMS不需要在训练阶段执行,而是在推理阶段,这是为了避免关键点被重复表达。

与目标检测时剔除多余框所使用的NMS不同,这里的NMS并不是通过IoU进行剔除,而是通过最大池化实现的。
下面以一个随机的矩阵为例说明NMS的过程:
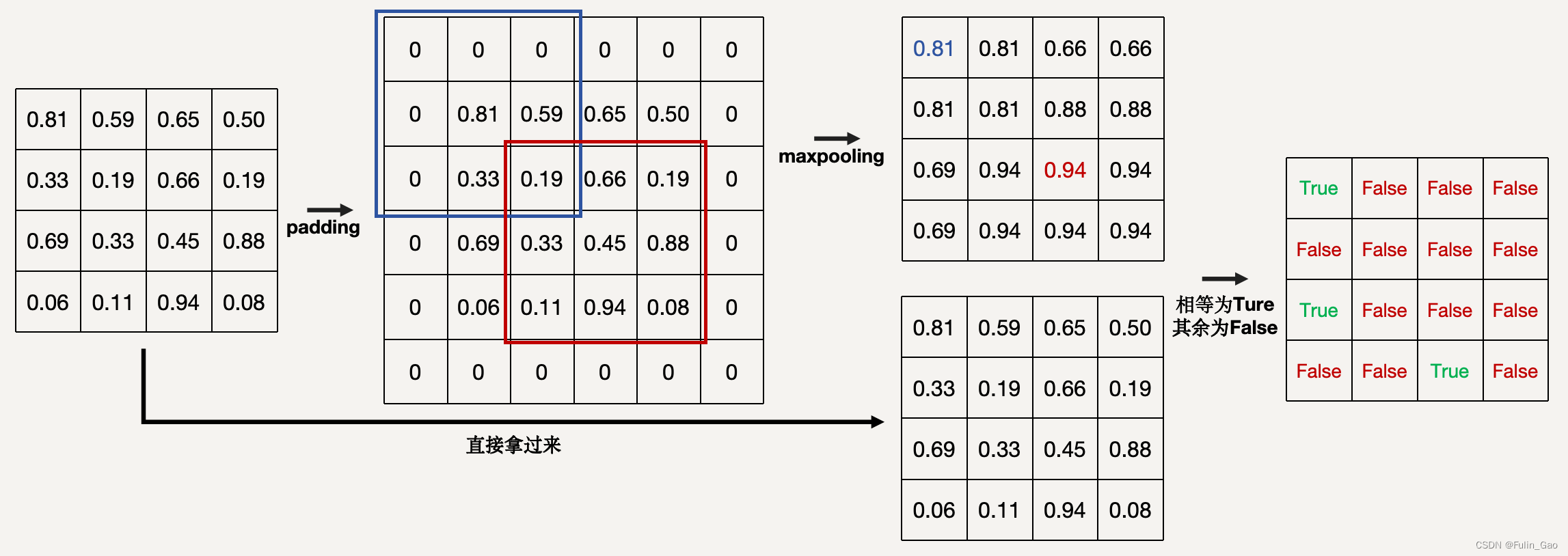
该例子中最大池化核大小为 3 × 3 3\times 3 3×3,最大池化前需要进行padding以保证最终输出尺寸的一致性,经最大池化后的矩阵与原矩阵同位置元素进行对比,相同的保留,剩余的再进行下一次NMS(源码中共两次NMS)。
使用标准交叉熵为损失进行关键点检测网络的学习,这与前面的softmax是对应的,64个像素点就有一个交叉熵损失项。如果与cell对应的64个像素点上有多个关键点,随机选取其中一个作为标签关键点,该方法使每64个像素点最多表达出一个关键点。
最后输出一个与原图尺寸一致的热力图,我们可以通过执行NMS、设置阈值等方法确定关键点的坐标。
2.2 关键点自标记
通过2.1 关键点预训练我们已经得到一个预训练好的关键点提取器(Base Detector),但是这个关键点提取器不具备泛化至真实数据上的能力,毕竟虚拟的简单数据与真实数据相差很大。但是真实数据的标注又很费力,所以作者提出Homographic Adaptation的方法利用预训练的关键点检测器对真实数据进行自标记以获取伪标签。
伪标签获取流程如下:
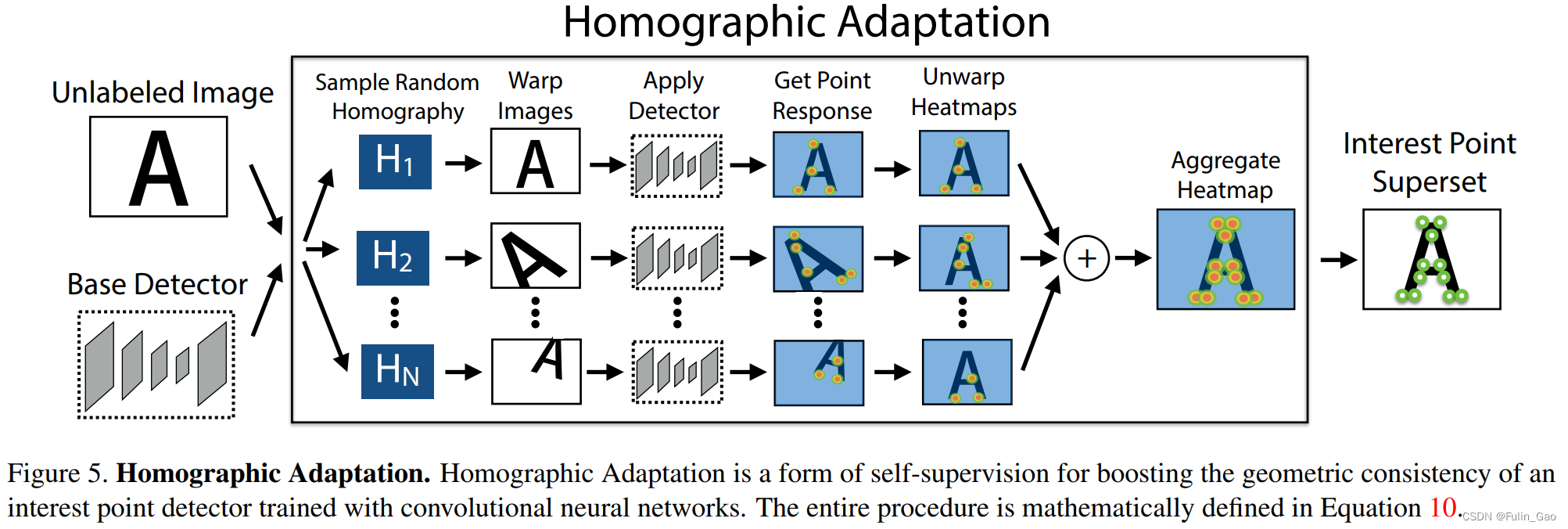
其中,无标签数据作者用的是CoCo,无标签指的是无关键点的标签。
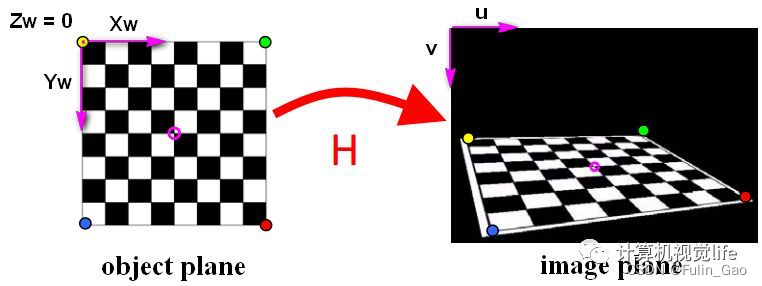
可见,Homographic Adaptation就是先将一个无标签图片进行各种随机的变换:
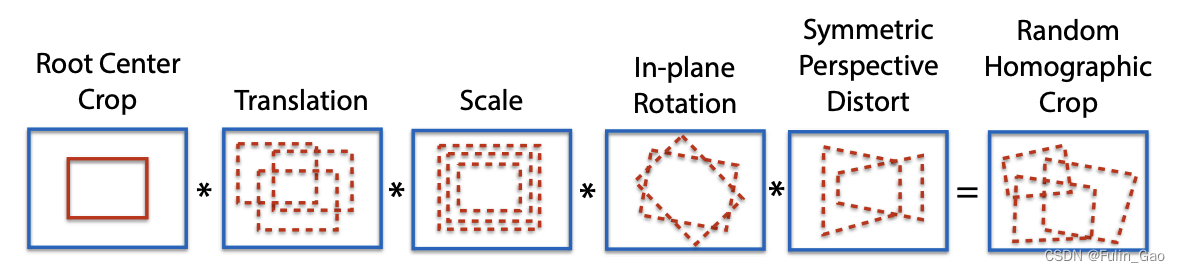
简单理解就是从另一个视角展示当前图中的物体,效果可能是这样:
之后,通过Warp操作扭曲变换后的图像。再使用预训练的关键点检测器进行关键点检测,然后将预测结果还原、合并得到一个聚合版的热力图,取出热力值高的地方就得到了该图片的关键点伪标签。
2.3 联合训练
通过2.2 关键点自标记有了真实数据的关键点伪标签,就可以训练模型以提升其预测真实数据关键点的能力。此外,作者还增加了一个描述符分支,在预测关键点的同时也能预测描述符(理想情况下的描述符可以理解为一种稳定的特征表达,无论经过什么变换或在什么视角下,同一事物的同一个关键点的描述符一致)。
联合训练的流程如下:
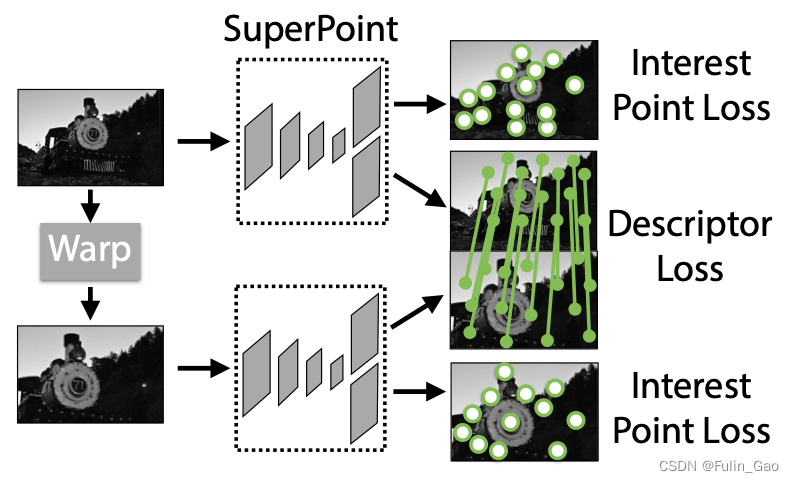
联合训练时输入两张图片,一张原始图片和一张Warp之后的图片(Warp操作表示为 H \mathcal{H} H),Warp前后图像的关键点伪标签和对应关系是已知的。
联合训练的模型被称为SuperPoint(图中的两个SuperPoint其实是同一个),其结构如下:
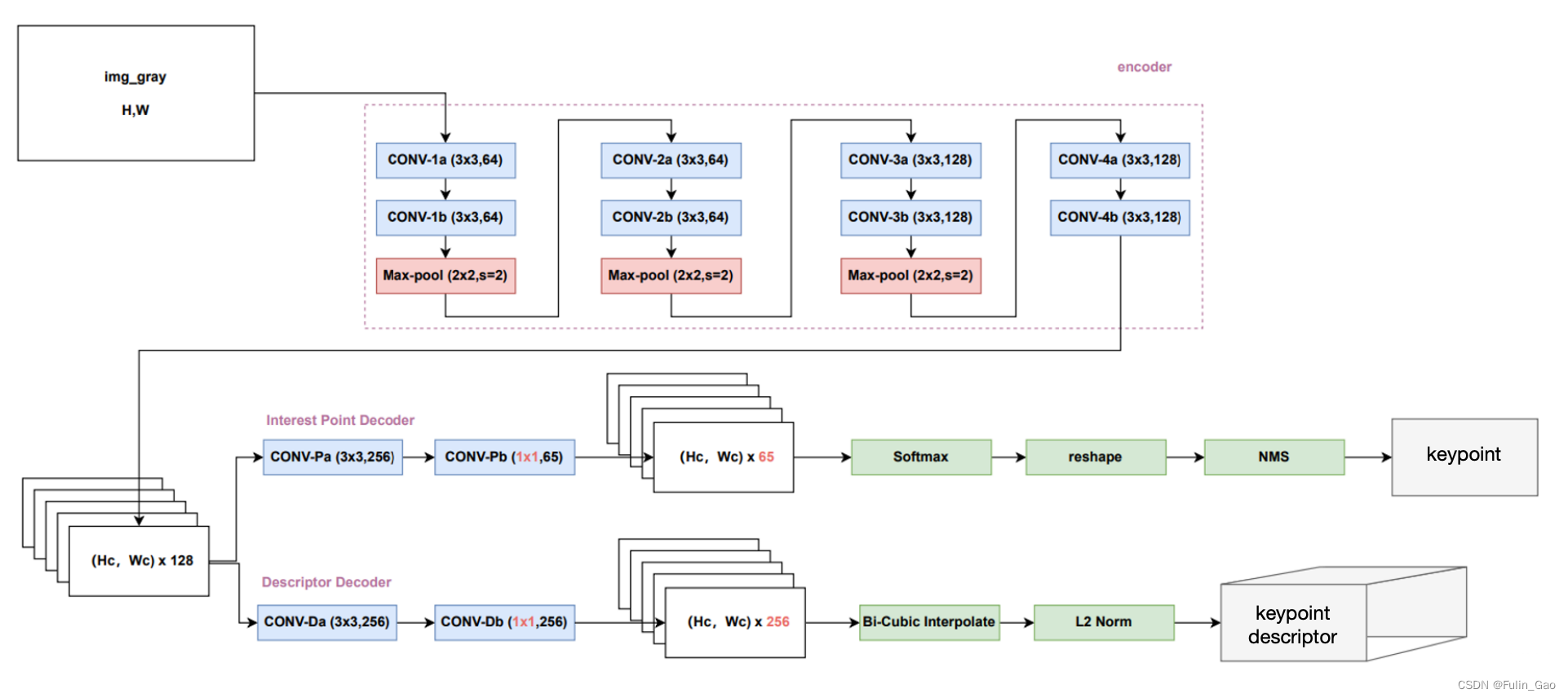
事实上,除描述符分支外,SuperPoint其余部分的网络结构与MagicPoint一致。
对于描述符分支,作者使用长度为256的特征向量来表达关键点。因此,作者先通过两个卷积层将原本128的通道数映射至256,特征图大小变为 H c × W c × 256 H_c\times W_c\times 256 Hc×Wc×256。双线性插值仅在推理阶段使用,训练时仅对每个cell上所有通道值执行L2 Norm归一化。
训练时所使用的损失函数如下:
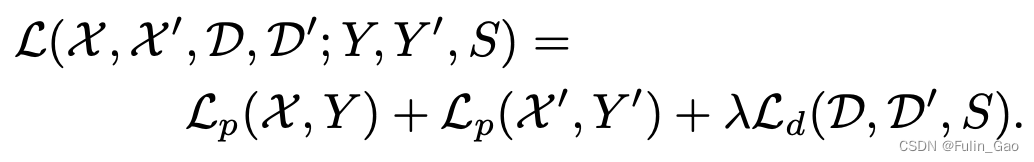
其中, X , Y \mathcal{X},Y X,Y分别为原始图片和关键点标签, X ′ , Y ′ \mathcal{X}^{\prime},\mathcal{Y}^{\prime} X′,Y′分别为Warp后的图片和关键点标签; L p \mathcal{L}_p Lp为标准交叉熵损失,作用于关键点检测分支,公式如下:
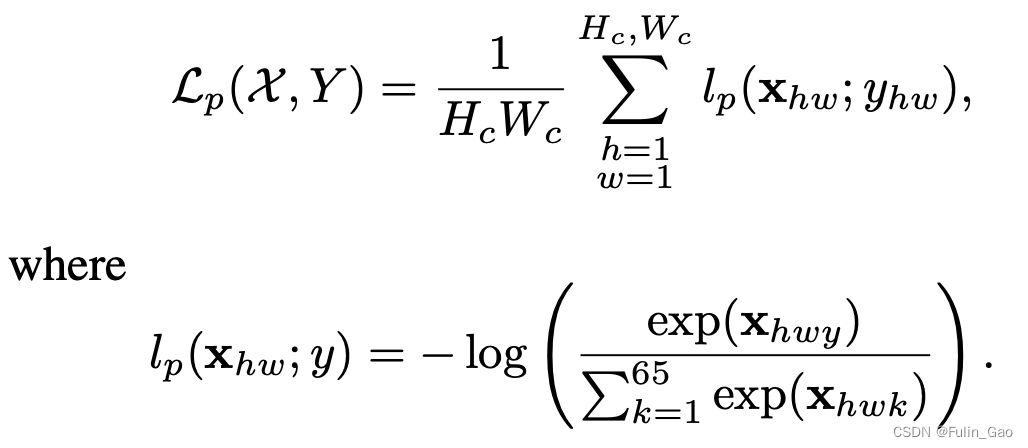
与预训练时一样,当与cell对应的64个像素点中有多个关键点时,仅随机选取一个作为关键点标签,每个cell都对应一个损失项。
L d \mathcal{L}_d Ld为Double margin Siamese loss,作用于描述符分支,公式如下:
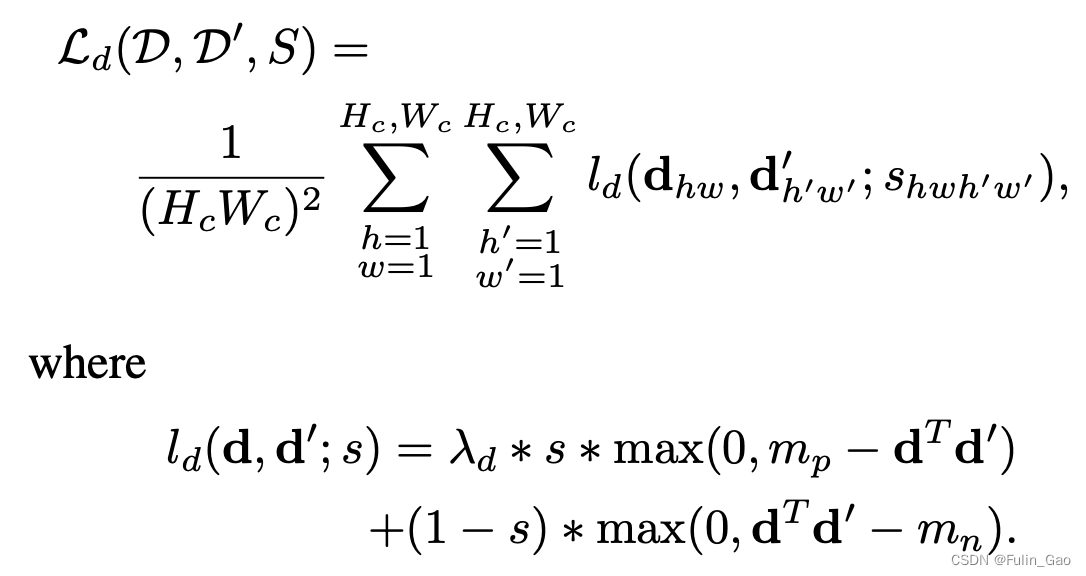
其中, d d d和 d ′ d^{\prime} d′为原始和warp后图像对应特征图的描述符; m p m_p mp和 m n m_n mn是自行设置的边界阈值; s s s是指示函数,公式如下
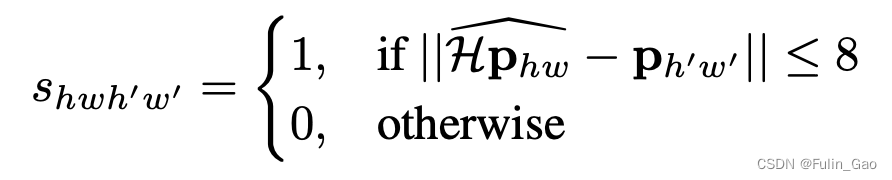
其中, p h w p_{hw} phw是原图特征图上cell的坐标, p h ′ w ′ p_{h^{\prime}w^{\prime}} ph′w′是经Warp变换后的图像的特征图上cell的坐标, H p h w ^ \widehat{\mathcal{H}p_{hw}} Hphw 是 p h w p_{hw} phw经Warp变换后的坐标。当 H p h w ^ \widehat{\mathcal{H}p_{hw}} Hphw 和 p h ′ w ′ p_{h^{\prime}w^{\prime}} ph′w′相差不超过8个像素时,认为 p h w p_{hw} phw和 p h ′ w ′ p_{h^{\prime}w^{\prime}} ph′w′这两个cell应该被匹配。
注意,这些坐标都是在特征图尺度上的,不是在原图上。原图特征图的所有cell和Warp特征图的所有cell两两配对,均要进行是否匹配的判断。
其实就是希望两张特征图上相互匹配的cell的描述符向量尽可能接近,反之尽可能远离。
它实现的功能通过下图一目了然:
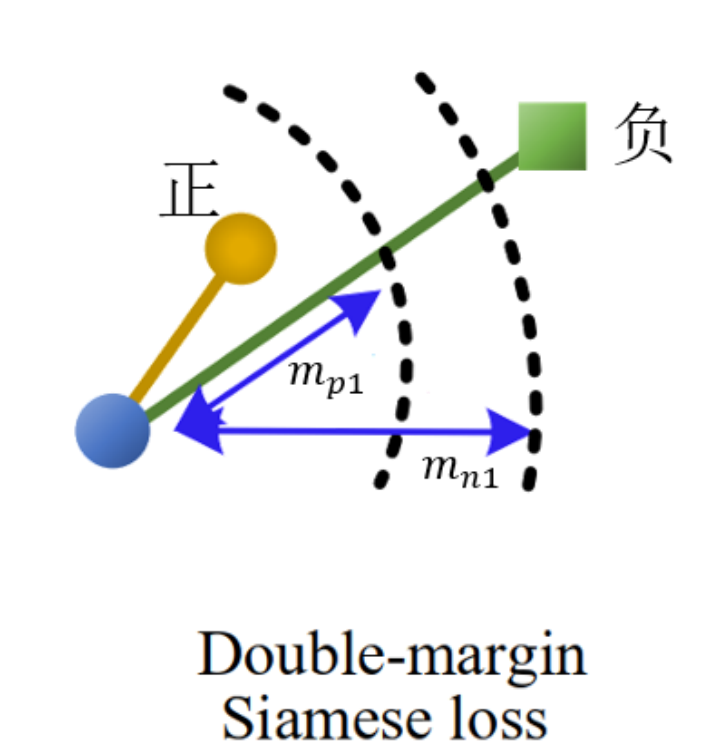
如果两个cell应该被匹配(相差不超过8个像素),就使用损失的前半部分,两个描述符向量的相似度 d T d ′ d^Td^{\prime} dTd′越大,损失越小,当相似度超过阈值 m p m_p mp时,不做惩罚。如果两个cell不应该被匹配(相差超过8个像素),就使用损失的后半部分,两个描述符向量的相似度 d T d ′ d^Td^{\prime} dTd′越小,损失越小,小于阈值 m n m_n mn时,不做惩罚。
于是,关键点检测分支输出原图尺度上的热力图,图中热值大的位置就是关键点坐标(可以通过阈值选取)。而描述符分支输出大小为 H c × W c × 256 H_c\times W_c\times 256 Hc×Wc×256的特征图。
在推理阶段,是通过torch.nn.functional.grid_sample() 取出关键点的特征向量,即描述符。grid_sample先将关键点坐标(在原图尺度上)映射到[-1,1]范围内,从整张图上看就是4个角的坐标分别映射为左上(-1,-1)、右上(1,-1)、右下(1,1)、左下(-1,1),再将坐标映射到特征图上取值。由于这种映射无法保证坐标一定在像素点上,所以会以双线性插值的方式计算与关键点对应的特征向量。之后,通过L2 Norm将每个256长度的特征向量归一化变可得到描述符。
致谢:
本博客仅做记录使用,无任何商业用途,参考内容如下:
Homographic Adaptation 单应性变换
一种自监督的特征点检测、描述网络
SuperPoint 与 SuperGlue 详解
深度学习特征点+描述子
















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











