









摘要翻译
我们提出了图注意力网络 (GATs),一个新颖的在图结构数据上运行的神经网络架构,利用掩码自注意力机制(masked self-attentional layers)来克服之前的图卷积神经网络及其近似模型的缺点。通过堆叠让其节点能够关注其邻域特征的网络层,我们能够(隐式地)给邻域中不同的节点赋予不同的权重,而不需要任何类型的昂贵矩阵操作(比如求逆)或依赖预先知道的图结构。通过这种方式,我们同时解决了基于谱图的图神经网络的几个关键挑战,并且使我们的模型可以在inductive和transductive类型的问题都适用。我们的GAT模型在四个inductive和transductive的基准数据集Cora, Citeseer、Pubmed、PIP(测试集在训练集上不可见)都取得或者匹配了state of the art的结果
模型理解
论文摘要中说其模型结构可以给一个节点的邻域中不同的节点赋予不同的权重,那是如何实现的呢,是通过自注意力机制来得到的;而强调是掩码自注意力机制(masked self-attentional layers),是因为一个节点不是对图中的所有其他节点进行注意力计算,而是只有部分节点,作者实验时就只取了一个节点的一阶邻域节点进行注意力计算。
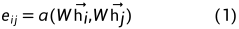
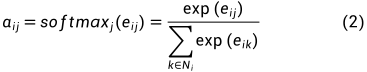
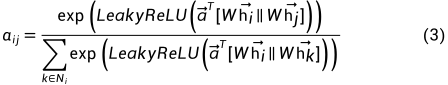
计算完注意力系数后,一个节点由其自己和相关邻域中的信息表示(这里对于论文中的公式写法其实有点疑问,觉得好像没有把节点本身包括进来,但是在图1右图中很明显节点原来的信息肯定要保留的)
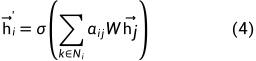
像Transformer一样,使用multi-head attention也是有益的,就像图1右图中不同颜色就表示不同head, 假设有K个head, 最后一层将K个注意力结果平均,而其他层则将各个头的结果连接(concate)起来(式(5)中的 || 符号表示连接(concatenation)操作)
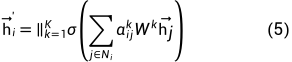
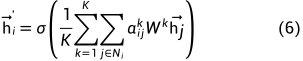
图1 attention机制和多头注意力示意
pytorch geometric的GAT代码有助于理解模型,附在这里
import torch
from torch.nn import Parameter, Linear
import torch.nn.functional as F
from torch_geometric.nn.conv import MessagePassing
from torch_geometric.utils import remove_self_loops, add_self_loops, softmax
from ..inits import glorot, zeros
class GATConv(MessagePassing):
r"""The graph attentional operator from the `"Graph Attention Networks"
<https://arxiv.org/abs/1710.10903>`_ paper
.. math::
\mathbf{x}^{\prime}_i = \alpha_{i,i}\mathbf{\Theta}\mathbf{x}_{i} +
\sum_{j \in \mathcal{N}(i)} \alpha_{i,j}\mathbf{\Theta}\mathbf{x}_{j},
where the attention coefficients :math:`\alpha_{i,j}` are computed as
.. math::
\alpha_{i,j} =
\frac{
\exp\left(\mathrm{LeakyReLU}\left(\mathbf{a}^{\top}
[\mathbf{\Theta}\mathbf{x}_i \, \Vert \, \mathbf{\Theta}\mathbf{x}_j]
\right)\right)}
{\sum_{k \in \mathcal{N}(i) \cup \{ i \}}
\exp\left(\mathrm{LeakyReLU}\left(\mathbf{a}^{\top}
[\mathbf{\Theta}\mathbf{x}_i \, \Vert \, \mathbf{\Theta}\mathbf{x}_k]
\right)\right)}.
Args:
in_channels (int): Size of each input sample.
out_channels (int): Size of each output sample.
heads (int, optional): Number of multi-head-attentions.
(default: :obj:`1`)
concat (bool, optional): If set to :obj:`False`, the multi-head
attentions are averaged instead of concatenated.
(default: :obj:`True`)
negative_slope (float, optional): LeakyReLU angle of the negative
slope. (default: :obj:`0.2`)
dropout (float, optional): Dropout probability of the normalized
attention coefficients which exposes each node to a stochastically
sampled neighborhood during training. (default: :obj:`0`)
bias (bool, optional): If set to :obj:`False`, the layer will not learn
an additive bias. (default: :obj:`True`)
**kwargs (optional): Additional arguments of
:class:`torch_geometric.nn.conv.MessagePassing`.
"""
def __init__(self, in_channels, out_channels, heads=1, concat=True,
negative_slope=0.2, dropout=0, bias=True, **kwargs):
super(GATConv, self).__init__(aggr='add', **kwargs)
self.in_channels = in_channels
self.out_channels = out_channels
self.heads = heads
self.concat = concat
self.negative_slope = negative_slope
self.dropout = dropout
self.__alpha__ = None
self.lin = Linear(in_channels, heads * out_channels, bias=False)
self.att_i = Parameter(torch.Tensor(1, heads, out_channels))
self.att_j = Parameter(torch.Tensor(1, heads, out_channels))
if bias and concat:
self.bias = Parameter(torch.Tensor(heads * out_channels))
elif bias and not concat:
self.bias = Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
glorot(self.lin.weight)
glorot(self.att_i)
glorot(self.att_j)
zeros(self.bias)
def forward(self, x, edge_index, return_attention_weights=False):
""""""
if torch.is_tensor(x):
x = self.lin(x)
x = (x, x)
else:
x = (self.lin(x[0]), self.lin(x[1]))
edge_index, _ = remove_self_loops(edge_index)
edge_index, _ = add_self_loops(edge_index,
num_nodes=x[1].size(self.node_dim))
out = self.propagate(edge_index, x=x,
return_attention_weights=return_attention_weights)
if self.concat:
out = out.view(-1, self.heads * self.out_channels)
else:
out = out.mean(dim=1)
if self.bias is not None:
out = out + self.bias
if return_attention_weights:
alpha, self.__alpha__ = self.__alpha__, None
return out, (edge_index, alpha)
else:
return out
def message(self, x_i, x_j, edge_index_i, size_i,
return_attention_weights):
# Compute attention coefficients.
x_i = x_i.view(-1, self.heads, self.out_channels)
x_j = x_j.view(-1, self.heads, self.out_channels)
alpha = (x_i * self.att_i).sum(-1) + (x_j * self.att_j).sum(-1)
alpha = F.leaky_relu(alpha, self.negative_slope)
alpha = softmax(alpha, edge_index_i, size_i)
if return_attention_weights:
self.__alpha__ = alpha
# Sample attention coefficients stochastically.
alpha = F.dropout(alpha, p=self.dropout, training=self.training)
return x_j * alpha.view(-1, self.heads, 1)
def __repr__(self):
return '{}({}, {}, heads={})'.format(self.__class__.__name__,
self.in_channels,
self.out_channels, self.heads)小结
这篇文章与Transformer有一些类似之处,只是在图结构上进行自注意力机制。 它是2017年写的,在Transformer爆火了几年的现在看起来GAT模型有点简单,但是在当时其实是一个在图上创新应用注意力机制的思路。
参考资料
论文: Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò and Yoshua Bengio. “Graph Attention Networks” arXiv: Machine Learning(2017): n. pag.
网站: https://petar-v.com/GAT/, 论文中的原始github项目https://github.com/PetarV-/GAT, 里面作者也给出了其他库实现了GAT库的链接
https://pytorch-geometric.readthedocs.io/en/1.5.0/_modules/torch_geometric/nn/conv/gat_conv.html 对pytorch-geometric的GAT实现















 3183
3183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









