







本文尝试两种剪枝方法,分别是直接使用NNI工具 以及 通过Slimming方法进行硬编码。
1、剪枝的意义
深度模型落地需要权衡两个核心问题:精度和复杂度。
模型压缩加速,在保持精度基本不变、降低模型计算复杂度。一方面提升模型落地的可能性,另一方面降低了资源消耗、节省成本。
2、NNI剪枝
2.1 卷积裁剪
是指对卷积网络的通道数进行裁剪,减少大模型的参数量。
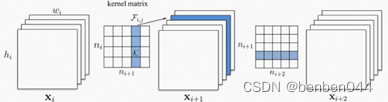
卷积裁剪主要是对卷积核的输出通道相关的维度进行缩小,此时影响卷积后的输出维度,同时还可能影响下一次卷积的输入通道数。
上图为卷积裁剪的示意图,输入维度Xi=[Ci, Hi, Wi],输出维度Xi+1=[Ci+1, Hi+1, Wi+1],卷积核维度Filteri,i+1=[ni, ni+1, ks, ks],上图中的kernel matrix中的小框K代表[kerner_size, kernel_size]个参数。
假设要裁剪20%的输出通道,那么卷积核变为Filteri,i+1 = [ni, 0.8*ni+1, ks, ks], 那么输出变为Xi+1=[0.8*ni+1, Hi+1, Wi+1]。
当Xi+1的维度变化的时候,为了使Xi+2的维度不变,那么对应的卷积和维度也要改变,由Filteri+1,i+2 = [ni+1, ni+2, ks, ks]变为Filteri+1,i+2 = [0.8*ni+1, ni+2, ks, ks]。
参考:https://blog.csdn.net/qq_40035462/article/details/123361763
2.2 L1-norm剪裁
在试验中使用的是L1NormFilterPruner,使用L1-norm统计量来表示一个卷积层内各个Filters的重要性,L1-norm越大的Filter越重要。
L1Norm直接计算各滤波器的L1范数,根据范数大小来决定裁剪哪个滤波器。
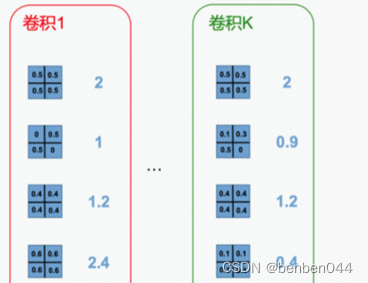
如卷积1中,第2个滤波器L1范数最小,所以裁剪第2个滤波器。卷积K中,第4个滤波器L1范数最小,所以裁剪第4个滤波器。
2.3 CenterNet的MobileNetv3中落地情况
落地代码见:MobileNetV3基于NNI剪枝操作_benben044的博客-CSDN博客_mobilenet 剪枝
NNI操作的核心代码如下:
# nni start
config_list = [{
'sparsity_per_layer': 0.2,
'op_types': ['Conv2d']
}]
pruner = L1NormPruner(model, config_list)
_, masks = pruner.compress()
for name, mask in masks.items():
print(name, ' sparsity: ', '{:.2f}'.format(mask['weight'].sum() / mask['weight'].numel()))
pruner._unwrap_model()
ModelSpeedup(model, torch.rand(2, 3, 512, 512).to(device), masks).speedup_model()
param_num2 = sum(x.numel() for x in model.parameters())
print('after nni model parameters num:', param_num2)
# nni end2.4 落地状况
(1)BackBone与业务之间的channel无法静态指定
在CenterNet的整体框架中,BackBone的分辨率从512*512到128*128,而原先的BackBone为DLASeg采用先下采样后上采样的方式,使得最后可以输出128*128的分辨率。采用MobileNet之后,是通过view的方式直接将分辨率变为128*128,这种方式就导致channel是动态计算出来的,无法事先指定。我们是在forward中得到了channel之后,再在init中指定hm、wh、reg的input channel值。

(2)网络层的定义不能放在forward中
因为上一个问题的存在,我们想是否能把hm、wh、reg的卷积定义到forward中,但是这种做法是错误的。
一方面,在cuda上运行时,会提示输入数据type和weight type不一致,pytorch issue中说是需要网络层的定义需要放在__init__()中。
另一方面,在cpu上运行时,loss无法收敛。因为是在forward上进行初始化,所以每次运行时都创建一组新的卷积(参数为初始化的),运行完毕后也只更新了一次参数。
三、Slimming剪枝原理
参考:https://blog.csdn.net/QNMTS/article/details/119875300
3.1 BN层的函数
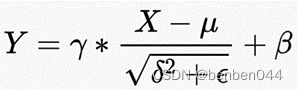
![]() 为gamma系数,也就是BN的weight值;
为gamma系数,也就是BN的weight值;
![]() 为beta项,也就是BN的bias值;
为beta项,也就是BN的bias值;
![]() 为均值参数,也就是BN的moving_mean值;
为均值参数,也就是BN的moving_mean值;
![]() 为方差参数,也就是BN的moving_var值;
为方差参数,也就是BN的moving_var值;
![]() 为epsilong,为了防止分母为0,可以取1e-16。
为epsilong,为了防止分母为0,可以取1e-16。
3.2 剪枝的基本流程
稀疏训练 -> 剪枝 -> 微调。
3.3 稀疏化
对BN层的gamma系数进行稀疏化(L1正则化),然后用稀疏化后的gamma系数来评价通道的重要性。在”卷积层->BN层->激活函数”中,某个通道的gamma系数为0则无论卷积层输出的值为何,到了BN层之后,它的输出值都变成了beta,说明这个卷积层该通道的输出已经对后续模块的前向计算不产生影响了。
稀疏化的操作为:
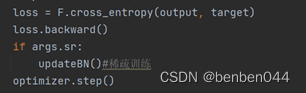

(1)稀疏化训练指的是在损失函数中添加关于BN层的gamma系数的L1正则化项,然后反向传递的时候gamma系数会相应的进行梯度更新;
(2)损失函数并没有修改,而是那些能够被剪枝的通道对应的gamma系数的梯度添加上了L1正则化惩罚项,然后在反向传播时,gamma系数会剪掉 lr乘上梯度;
(3)Gamma系数的梯度包含了损失函数对其求导项也包含了L1正则化惩罚项;
(4)Gamma系数的梯度更新会使得大量gamma系数的值趋于0,而那些趋于0的gamma系数对应的通道都是不重要的,可以剪枝掉。
3.4 剪枝过程
(1)对文件的所有权重值的绝对值排序
(2)找到需要裁剪的最大值(阈值)和索引(所有的权重值个数*裁剪率)
(3)对权重 >= 阈值,掩码操作,保留,减去小于阈值
(4)测试此时模型的精度
(5)将剩下weight和bias重新写入模型
3.5 微调
对剪枝后的模型微调,加载剪枝后的模型训练,提升剪枝精度,此时的模型大小不会改变,但模型精度大大提升。
比如:
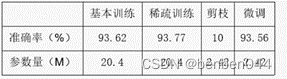
四、Slimming剪枝实战
本次采用半自动剪枝的方式,并且是针对MobileNetV3进行高度定制。
4.1 将MobileNetv3改造为可配置参数
原先的MobileNetv3内部参数是写死的,比如下面:
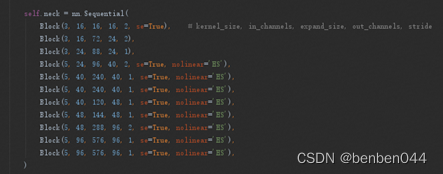
一旦实施了剪枝,那么这些数字将会发生变化。
所以需要这些参数都是可配置的,每次从配置列表中读取这些值,即可创建模型。
MobileNetv3源码见:
import torch
from torch import nn
import torch.nn.functional as F
class hswish(nn.Module):
def __init__(self):
super(hswish, self).__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = x * self.relu6(x + 3) / 6
return out
class hsigmoid(nn.Module):
def __init__(self):
super(hsigmoid, self).__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = self.relu6(x + 3) / 6
return out
# 注意力机制
class SE(nn.Module):
def __init__(self, in_channels, reduce=4):
super(SE, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels, in_channels // reduce, 1, bias=False),
nn.BatchNorm2d(in_channels // reduce),
nn.ReLU6(inplace=True),
nn.Conv2d(in_channels // reduce, in_channels, 1, bias=False),
nn.BatchNorm2d(in_channels),
hsigmoid()
)
def forward(self, x):
out = self.se(x)
out = x * out
return out
class Block(nn.Module):
def __init__(self, kernel_size, in_channels, expand_size, out_channels, stride, se=False, nolinear='RE'):
super(Block, self).__init__()
self.se = nn.Sequential()
if se:
self.se = SE(expand_size)
if nolinear == 'RE':
self.nolinear = nn.ReLU6(inplace=True)
elif nolinear == 'HS':
self.nolinear = hswish()
self.block = nn.Sequential(
nn.Conv2d(in_channels, expand_size, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(expand_size),
self.nolinear,
nn.Conv2d(expand_size, expand_size, kernel_size, stride=stride, padding=kernel_size // 2, groups=expand_size, bias=False),
nn.BatchNorm2d(expand_size),
self.se,
self.nolinear,
nn.Conv2d(expand_size, out_channels, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels)
)
self.shortcut = nn.Sequential()
if stride == 1 and in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.stride = stride
def forward(self, x):
out = self.block(x)
if self.stride == 1:
out += self.shortcut(x)
return out
class MobileNetV3(nn.Module):
def __init__(self, heads):
super().__init__()
class_num = heads['hm']
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(16),
hswish()
)
self.neck = nn.Sequential(
Block(3, 16, 16, 16, 2, se=True), # kernel_size, in_channels, expand_size, out_channels, stride
Block(3, 16, 72, 24, 2),
Block(3, 24, 88, 24, 1),
Block(5, 24, 96, 40, 2, se=True, nolinear='HS'),
Block(5, 40, 240, 40, 1, se=True, nolinear='HS'),
Block(5, 40, 240, 40, 1, se=True, nolinear='HS'),
Block(5, 40, 120, 48, 1, se=True, nolinear='HS'),
Block(5, 48, 144, 48, 1, se=True, nolinear='HS'),
Block(5, 48, 288, 96, 2, se=True, nolinear='HS'),
Block(5, 96, 576, 96, 1, se=True, nolinear='HS'),
Block(5, 96, 576, 96, 1, se=True, nolinear='HS'),
)
self.conv2 = nn.Sequential(
nn.Conv2d(96, 576, 1, bias=False),
nn.BatchNorm2d(576),
hswish()
)
self.conv3 = nn.Sequential(
nn.Conv2d(576, 1280, 1, 1, bias=False),
nn.BatchNorm2d(1280),
hswish()
)
self.hm = nn.Conv2d(20, class_num, kernel_size=1)
self.wh = nn.Conv2d(20, 2, kernel_size=1)
self.reg = nn.Conv2d(20, 2, kernel_size=1)
def forward(self, x):
x = self.conv1(x)
x = self.neck(x)
x = self.conv2(x)
x = self.conv3(x)
y = x.view(x.shape[0], -1, 128, 128)
z = {}
z['hm'] = self.hm(y)
z['wh'] = self.wh(y)
z['reg'] = self.reg(y)
return [z]
if __name__ == '__main__':
heads = {'hm': 2, 'wh': 2, 'reg': 2}
model = MobileNetV3(heads)
print(model)
input = torch.randn(2, 3, 512, 512) # batch_size =1 会报错
out = model(input)
print(out[0]['hm'].shape)改造后的代码见:
import torch
from torch import nn
BLOCK_IN_CHANNEL = [] # 只存放一个值,Block之间传递out_channels临时使用
class hswish(nn.Module):
def __init__(self):
super(hswish, self).__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = x * self.relu6(x + 3) / 6
return out
class hsigmoid(nn.Module):
def __init__(self):
super(hsigmoid, self).__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = self.relu6(x + 3) / 6
return out
# 注意力机制
class SE(nn.Module):
def __init__(self, se_in_channels, se_mid_size, se_out_channels):
super(SE, self).__init__()
self.se = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(se_in_channels, se_mid_size, 1, bias=False),
nn.BatchNorm2d(se_mid_size),
nn.ReLU6(inplace=True),
nn.Conv2d(se_mid_size, se_out_channels, 1, bias=False),
nn.BatchNorm2d(se_out_channels),
hsigmoid()
)
def forward(self, x):
out = self.se(x)
out = x * out
return out
class Block(nn.Module):
def __init__(self, channel_queue, in_channels, kernel_size, stride, se=False, nolinear='RE'):
super(Block, self).__init__()
if se:
se_mid_size = channel_queue.pop(0)
se_out_channels = channel_queue.pop(0)
expand_size2 = channel_queue.pop(0)
expand_size1 = channel_queue.pop(0)
out_channels = channel_queue.pop(0)
else:
expand_size1 = channel_queue.pop(0)
expand_size2 = channel_queue.pop(0)
out_channels = channel_queue.pop(0)
self.se = nn.Sequential()
if se:
self.se = SE(expand_size2, se_mid_size, se_out_channels)
if nolinear == 'RE':
self.nolinear = nn.ReLU6(inplace=True)
elif nolinear == 'HS':
self.nolinear = hswish()
self.block = nn.Sequential(
nn.Conv2d(in_channels, expand_size1, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(expand_size1),
self.nolinear,
nn.Conv2d(expand_size1, expand_size2, kernel_size, stride=stride, padding=kernel_size // 2, groups=expand_size1, bias=False),
nn.BatchNorm2d(expand_size2),
self.se,
self.nolinear,
nn.Conv2d(expand_size2, out_channels, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels)
)
self.shortcut = nn.Sequential()
if stride == 1 and in_channels != out_channels:
shortcut_out_channles = channel_queue.pop(0)
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, shortcut_out_channles, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.stride = stride
BLOCK_IN_CHANNEL.append(out_channels)
def forward(self, x):
out = self.block(x)
if self.stride == 1:
out += self.shortcut(x)
return out
class MobileNetV3(nn.Module):
def __init__(self, heads, channel_queue):
super().__init__()
class_num = heads['hm']
in_channels = channel_queue.pop(0)
self.conv1 = nn.Sequential(
nn.Conv2d(3, in_channels, 3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(in_channels),
hswish()
)
BLOCK_IN_CHANNEL.append(in_channels)
self.neck = nn.Sequential(
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 3, 2, se=True), # channel_queue, in_channels, kernel_size, stride 3, 16, 16, 16, 2
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 3, 2), # 3, 16, 72, 24, 2
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 3, 1), # 3, 24, 88, 24, 1
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 5, 2, se=True, nolinear='HS'), # 5, 24, 96, 40, 2
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 5, 1, se=True, nolinear='HS'), # 5, 40, 240, 40, 1
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 5, 1, se=True, nolinear='HS'), # 5, 40, 240, 40, 1
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 5, 1, se=True, nolinear='HS'), # 5, 40, 120, 48, 1
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 5, 1, se=True, nolinear='HS'), # 5, 48, 144, 48, 1
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 5, 2, se=True, nolinear='HS'), # 5, 48, 288, 96, 2
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 5, 1, se=True, nolinear='HS'), # 5, 96, 576, 96, 1
Block(channel_queue, BLOCK_IN_CHANNEL.pop(), 5, 1, se=True, nolinear='HS'), # 5, 96, 576, 96, 1
)
conv2_in_channels = BLOCK_IN_CHANNEL.pop()
conv2_out_channels = channel_queue.pop(0)
self.conv2 = nn.Sequential(
nn.Conv2d(conv2_in_channels, conv2_out_channels, 1, bias=False),
nn.BatchNorm2d(conv2_out_channels),
hswish()
)
conv3_in_channels = conv2_out_channels
conv3_out_channels = channel_queue.pop(0)
self.conv3 = nn.Sequential(
nn.Conv2d(conv3_in_channels, conv3_out_channels, 1, 1, bias=False),
nn.BatchNorm2d(conv3_out_channels),
hswish()
)
self.hm = nn.Conv2d(20, class_num, kernel_size=1)
self.wh = nn.Conv2d(20, 2, kernel_size=1)
self.reg = nn.Conv2d(20, 2, kernel_size=1)
def forward(self, x):
x = self.conv1(x)
x = self.neck(x)
x = self.conv2(x)
x = self.conv3(x)
y = x.view(x.shape[0], -1, 128, 128)
z = {}
z['hm'] = self.hm(y)
z['wh'] = self.wh(y)
z['reg'] = self.reg(y)
return [z]
if __name__ == '__main__':
heads = {'hm': 10, 'wh': 2, 'reg': 2}
# channel_queue = [16, 4, 16, 16, 16, 16, 72, 72, 24, 88, 88, 24, 24, 96, 96, 96, 40, 60, 240, 240, 240, 40, 60, 240,
# 240, 240, 40, 30, 120, 120, 120, 48, 48, 36, 144, 144, 144, 48, 72, 288, 288, 288, 96, 144, 576, 576,
# 576, 96, 144, 576, 576, 576, 96, 576, 1280]
channel_queue = [16, 4, 16, 16, 16, 16, 69, 69, 24, 73, 73, 24, 23, 90, 90, 90, 40, 43, 210, 210, 210, 40, 46, 192,
192, 192, 40, 28, 108, 108, 108, 48, 48, 33, 122, 122, 122, 48, 69, 233, 233, 233, 96, 116, 433,
433, 433, 96, 144, 504, 504, 504, 96, 552, 1280]
model = MobileNetV3(heads, channel_queue)
print(model)
input = torch.randn(2, 3, 512, 512) # batch_size =1 会报错
out = model(input)
print(out[0]['hm'].shape)Channel_queue中的数字取自batchnorm中的值,因为在代码中,backbone主干部分代码每个con之后都是有batchnorm的,而hm、wh、reg的卷积是不接batchnorm的。
改造中最难的部分是Block的修改。
模型构建是按照__init__()中的顺序进行初始化的,后续forward的运行只是更新这些参数。
Block的核心部分逻辑如下:
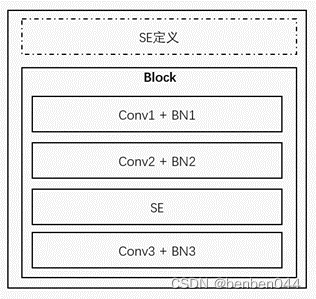
可以发现SE的定义先于Block的定义,所以仔细观察BN的值与block初始化的关系,找到参数正确的取数方式。
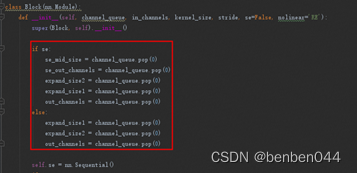
4.2 剪枝过程
(1)训练代码中增加BN的gamma系数的L1正则化
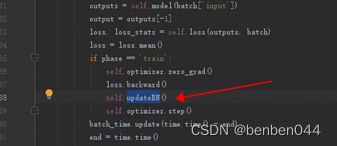

通过L1正则化,使得BN中部分没用的权重趋近于0。
以便于后续剪枝时提出这部分的权重对应的通道。
(2)读取训练好的原始模型,计算剪枝阈值
根据可配置的参数创建模型,并且加载训练好的pth模型文件的state_dict的参数
计算所有BN的权重总个数为total
将BN的权重取绝对值后排序,按照total * percent得到阈值的index,从而得到阈值
(3)找到每一个BN的剪枝个数
首先是BN的每个weight和阈值进行比较,如果大于等于阈值则mask置为1,否则mask置为0。把mask中1相加即为本BN的保留个数,把保留信息保存在cfg中。
针对分组卷积和SE(注意力机制)需要再单独处理下。
Mobilenetv3的分组卷积,in_channel、out_channel和groups值一样,如下图所示:
![]()
此时需要上一步的BN输出、这一步的BN输出一样,我取了两者的较大值。
对于SE模块,如果分组卷积存在,那么它的下游SE模块的输入、输出BN也需要和上值一致。
所以,一旦出现分组卷积,则分组卷积上下游的BN值都需要保持一致,这一步是难点。
(4)算出每个BN的剪枝mask
如果没有分组卷积,则在第(3)步即可同时计算出mask。
因为分组卷积的存在,使得被裁剪的channel数有所下降,预期20%被裁剪比例,实际可能只有10%左右。
因为在第(3)步中已经保存了BN的保留个数信息,所以每一个BN的weight取绝对值后排序,较大的weight对应mask置为1,其余置为0。
同时BN的gamma系数(weight)和beta值(bias)乘以mask进行修正。
(5)被修正的原始模型在验证集上求指标数据
(6)剪枝后的新模型构建及参数赋值
Cfg中保留了剪枝后的信息,通过Cfg可以直接构建新的模型。
参数赋值时最难的是start_mask和end_mask的值。
如果没有SE模块、shortcut模块、分组卷积,则会相当简单一点,一般处理方式如下:
针对nn.Conv2d,
w = m0.weight.data[:, idx0, :, :].clone() # 输入通道
w = w[idx1, :, :, :].clone() # 输出通道
idx0为start_mask的信息,idx1为end_mask的信息。
针对nn.BatchNorm2d,
m1.weight.data = m0.weight.data[idx1].clone()
m1.bias.data = m0.bias.data[idx1].clone()
m1.running_mean = m0.running_mean[idx1].clone()
m1.running_var = m0.running_var[idx1].clone()
idx1为end_mask的信息。
我们通过在module的属性里面找到‘se’和’shortcut‘的名称,来判断接下来模块中是否存在se和shortcut。
针对SE模块,它的定义早于block的定义,所以start_mask_id的顺序比较混乱,但是因为本次剪枝是mobilenetv3定制版本,所以可以根据规律直接指定start_mask_id的顺序,比如:
se_pattern_list = [4, 1, 0, 3, 2] # 有注意力时候的start_mask_id顺序, 0为end_mask的位置(需要特别注意)
针对shortcut模块,它的start_mask_id为下一个Block的最后一个BN的值。
针对分组卷积,而构建cfg时碰到同样的问题,需要分组卷积的前后的mask信息保持一致,这个根因是深度可分离卷积(groups=in_channels=out_channels)和普通卷积的机制不一样。
Conv和batchnorm的相关参数赋值完成之后,重新在验证集上计算数据指标,和第(5)步的值是完全一样的。并将新模型进行持久化。
(7)上一步的模型,重新进行训练,即微调,从而得到最后的模型。
- 模型准确度

- 模型参数量:
DLASeg为2000W个左右
MobileNetV1为320W个左右
MobileNetV2为430W个左右,总模型大小为17M
MobileNetV3为166W个左右,总模型大小为7M
剪枝后的MobileNetV3为143W个左右,总模型大小为6.5M
- CPU运行时间
DLASeg为1.2s
MobileNetV1为250ms
MobileNetV2为600ms
MobileNetV3为120ms
剪枝后的MobileNetV3为115ms
4.3 剪枝问题定位
剪枝后出现第一次验证集数据指标和第二次验证集数据指标不一致的情况,如果直接在原场景中定位非常困难。所以需要把不一致的地方单独拉出来进行定位。
(1)构造简化版的mobilenet
import torch
from torch import nn
class hswish(nn.Module):
def __init__(self):
super(hswish, self).__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = x * self.relu6(x + 3) / 6
return out
class hsigmoid(nn.Module):
def __init__(self):
super(hsigmoid, self).__init__()
self.relu6 = nn.ReLU6(inplace=True)
def forward(self, x):
out = self.relu6(x + 3) / 6
return out
class MobileNet(nn.Module):
def __init__(self, channel_queue, in_channels=16, kernel_size=3, stride=2, nolinear='RE'):
super(MobileNet, self).__init__()
expand_size1 = channel_queue.pop(0)
expand_size2 = channel_queue.pop(0)
out_channels = channel_queue.pop(0)
if nolinear == 'RE':
self.nolinear = nn.ReLU6(inplace=True)
elif nolinear == 'HS':
self.nolinear = hswish()
self.conv1 = nn.Conv2d(in_channels, expand_size1, 1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(expand_size1)
self.conv2 = nn.Conv2d(expand_size1, expand_size2, kernel_size, stride=stride, padding=kernel_size // 2, groups=expand_size1, bias=False)
self.bn2 = nn.BatchNorm2d(expand_size2)
self.conv3 = nn.Conv2d(expand_size2, out_channels, 1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride == 1 and in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels)
)
self.stride = stride
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data = torch.randn(m.weight.shape[0])
def forward(self, x):
out = self.conv1(x) # [1] [2]
out = self.bn1(out) # [1] [2]
out = self.nolinear(out) # [1] [2]
out = self.conv2(out) # [1] [2] 问题出在这里
out = self.bn2(out) # [1] [2]
out = self.nolinear(out) # [1] [2]
out = self.conv3(out) # [1] [2]
out = self.bn3(out) # [1] [2]
if self.stride == 1:
out += self.shortcut(x)
return out # [1]1.4033e-01
if __name__ == '__main__':
channel_queue = [72, 72, 24]
model = MobileNet(channel_queue)
print(model)
input = torch.randn(2, 16, 256, 256)
out = model(input)
print(out)这里只主要的区别是模型weight初始化时乱序赋值。
因为我们不打算进行训练,只对初始化之后的weigh进行剪枝。
如果不设定weight的方式,默认初始化weight全部为1,就没法进行排序剪枝了。
(2)模型保存
from MobileNet import MobileNet
import torch
if __name__ == '__main__':
channel_queue = [72, 72, 24]
model = MobileNet(channel_queue)
model.init_params()
data = {}
data['epoch'] = -1
data['state_dict'] = model.state_dict()
torch.save(data, 'mobile_test.pth')
(3)模型剪枝
from MobileNet import MobileNet
import torch
import torch.nn as nn
import os
import numpy as np
channel_queue = [72, 72, 24]
model = MobileNet(channel_queue)
raw_model_path = "mobile_test.pth"
if os.path.isfile(raw_model_path):
print("==> loading checkpoint '{}'".format(raw_model_path))
checkpoint = torch.load(raw_model_path)
start_epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['state_dict'])
print("==> loaded checkpoint '{}'(epoch {})".format(raw_model_path, start_epoch))
# print(model)
cfg = [69, 69, 24]
total = 69 + 69 + 24
pruned = 0
# 算出每个BN的裁剪mask
i = 0
cfg_mask = []
for k, m in enumerate(model.modules()):
if isinstance(m, nn.BatchNorm2d):
weight_copy = m.weight.data.abs().clone()
remain_channel_num = cfg[i]
total_channel = weight_copy.shape[0]
y, _ = torch.sort(weight_copy)
pruned += total_channel - remain_channel_num
thre = y[total_channel - remain_channel_num]
mask = weight_copy.ge(thre).float()
m.weight.data.mul_(mask)
m.bias.data.mul_(mask)
cfg_mask.append(mask.clone())
i += 1
pruned_ratio = pruned / total
print('pruned_ratio: {},Pre-processing Successful!'.format(pruned_ratio))
# test1
torch.manual_seed(10)
input = torch.randn(2, 16, 1, 1)
output1 = model(input)
print('---------output1-----------')
print(output1) # 2, 24, 128, 128
# make real prune
new_model = MobileNet(cfg)
# output2 = new_model(input)
# print('---------output2-----------')
# print(output2)
layer_id_in_cfg = 0 # cfg中的层数索引
start_mask = torch.ones(16)
end_mask = cfg_mask[layer_id_in_cfg]
start_mask_id = 0
is_groups_flag = 0
j = 0
for [m0, m1] in zip(model.modules(), new_model.modules()):
if isinstance(m0, nn.Conv2d):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
print('In shape: {:d} Out shape:{:d}'.format(idx0.shape[0], idx1.shape[0]))
if m0.groups == 1:
w = m0.weight.data[:, idx0, :, :].clone() # 输入通道
w = w[idx1, :, :, :].clone() # 输出通道
else: # 针对分组卷积需要特殊处理
w = m0.weight.data[:, :, :, :].clone() # 输入通道
w = w[idx0, :, :, :].clone() # 输出通道
is_groups_flag = 1
m1.weight.data = w.clone()
print('here')
elif isinstance(m0, nn.BatchNorm2d):
if is_groups_flag == 1:
idx1 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
else:
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
m1.weight.data = m0.weight.data[idx1].clone()
m1.bias.data = m0.bias.data[idx1].clone()
m1.running_mean = m0.running_mean[idx1].clone()
m1.running_var = m0.running_var[idx1].clone()
start_mask_id = layer_id_in_cfg
if is_groups_flag == 1:
is_groups_flag = 0
else:
start_mask = end_mask.clone()
layer_id_in_cfg += 1
if layer_id_in_cfg < len(cfg_mask):
end_mask = cfg_mask[layer_id_in_cfg]
else:
break
print('new_model after pruned................')
# print(new_model)
output3 = new_model(input)
print('---------output3-----------')
print(output3)
input = torch.randn(2, 16, 1, 1)
设置height=width=1
如果height=width=512,则pycharm中大部分值将无法显示,不方便定位。
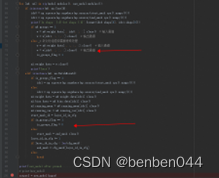
以上两个地方是导致两次验证集数据指标不一致的原因。

















 1972
1972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









