







DeepSeek-V3 是由幻方量化推出的一款具有突破性技术的大型语言模型,其在性能、效率和成本控制方面均实现了显著提升。以下是对其技术突破及原理的详细解析:
1. 核心架构与参数规模
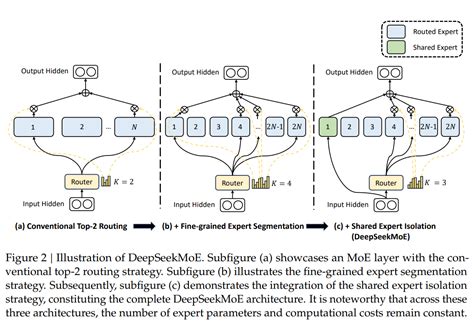
DeepSeek-V3 拥有 6710亿参数,但每个 token 只激活370亿参数,采用了一种智能激活策略,显著降低了计算成本,同时保持了高性能。这种选择性激活的方式被称为 Mixture-of-Experts(MoE)架构,即“专家混合”模型架构,通过动态冗余策略在推理和训练过程中实现高效运行。
2. 多头潜在注意力机制(MLA)
DeepSeek-V3 引入了 多头潜在注意力机制(Multi-head Latent Attention, MLA) ,该机制通过低秩压缩 Key-Value 矩阵,将注意力机制的内存占用大幅减少,同时提升模型的推理效率。此外,MLA 还能够通过稀疏注意力机制进一步优化计算资源的使用,使模型在处理长序列时保持较低的开销。
3. 创新的负载均衡策略
为了克服 MoE 模型中负载不均衡的问题,DeepSeek-V3 提出了 无损辅助负载均衡策略(Auxiliary Loss-Free Load Balancing),这一策略不仅提高了训练稳定性,还使模型能够在多个 GPU 上高效扩展。
4. 多Token预测技术(MTP)
DeepSeek-V3 还引入了 多Token预测技术(Multi-Token Prediction, MTP) ,该技术通过预测多个未来的 token 来增强文本生成能力,从而提升长文本生成任务的表现。
5. 高效推理与训练优化
在推理阶段,DeepSeek-V3 采用了 P/D分离策略和双流推理策略,显著提升了系统吞吐量并减少了解码延时。此外,通过 PTX 技术优化 GPU 性能,进一步提高了硬件效率。
6. 低成本训练与部署
DeepSeek-V3 的训练成本仅为 557.6万美元,远低于其他同类模型(如 GPT-4o 的 3080万美元)。其训练过程仅用了不到 280万个 GPU 小时,而 GPT-4o 则耗时 3080万小时。API
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2442
2442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











