







引言
在AI军备竞赛白热化的2024年,DeepSeek-V3以惊人的推理速度震撼业界:相比前代模型推理速度提升3倍,训练成本降低70%。这背后是十余项革命性技术的叠加创新,本文将为您揭开这艘"AI超跑"的性能密码。
DeepSeek-V3的技术路径证明:计算效率的本质是知识组织的效率。其MoE架构中2048个专家的动态协作,恰似人脑神经网络的模块化运作——每个专家不再是被动执行计算的"劳工",而是具备领域意识的"知识单元"。这种架构创新将冯·诺依曼体系的线性计算流,进化为具备自组织特征的量子化智能网络。
在万卡集群中游走的SeekNet协议、突破物理极限的MTP引擎、数据精馏工厂的量子级过滤…这些突破昭示着:AI竞赛已从单纯的算法博弈,演变为芯片架构、网络协议、编译系统、能源管理的全栈战争。当模型规模突破万亿参数门槛,0.1μs的延迟优化、1%的显存节省,都将引发指数级的性能质变。
DeepSeek-R1蒸馏引擎展现的"知识反哺"现象,暗示着大模型发展正在迈入新阶段:当7B小模型通过结构化蒸馏获得90%的原始能力时,我们或许正在见证智能可压缩性的发现。这如同物理学中的质能方程,揭示出智能存在基本"量子单元"的可能性——未来的模型优化可能不再依赖参数堆砌,而是转向智能密度的量子化重组。
动力总成升级:MoE架构的暴力美学
在大模型计算范式演进中,DeepSeek-V3的混合专家(Mixture of Experts, MoE)架构通过系统性创新,突破了传统稠密模型的效率瓶颈,实现了计算效能与模型容量的双重飞跃。其核心设计哲学在于:通过专家专业化分工与动态资源调度的深度协同,重构大型语言模型的底层计算范式。
(1)专家矩阵:计算效率的极限压缩
DeepSeek-V3的MoE架构采用分层专家集群设计,每个集群包含数百个独立训练的领域专家模型。与传统MoE架构相比,其创新体现在三个维度:
-
动态稀疏激活机制
通过门控网络(Gating Network)的二次优化,每个输入token仅激活3-5个最相关专家(激活率<0.5%),在保持等效参数量级的前提下,将实际计算量压缩至传统稠密模型的1/5~1/8。该机制通过以下技术实现:- 语义感知路由:基于多头注意力改进的Gating Network,构建128维语义向量空间
- 硬件感知调度:结合GPU显存带宽特性动态调整专家激活阈值
- 知识拓扑约束:通过专家关系图谱避免跨领域专家的无效组合
-
分层路由系统
路由层级 功能特性 技术指标 L1路由 粗粒度领域筛选 10μs级决策延迟 L2路由 细粒度专家匹配 支持768维特征比对 L3路由 硬件资源适配 显存占用降低40% -
专家专业化训练
采用课程学习+领域对抗训练策略,使每个专家在特定领域(如数学推理、代码生成)达到接近专用模型的性能水平。实验表明,该策略使专家间的任务区分度提升3.2倍。
(2)负载均衡:计算流体的智能控制
针对MoE架构固有的专家负载倾斜问题,DeepSeek-V3提出动态压力场均衡算法,通过三级控制体系实现计算资源的量子级调度:
技术架构
[压力监控层]
│
┌──────────┬─────────┴─────────┬──────────┐
▼ ▼ ▼ ▼
[计算负载感知] [显存压力检测] [通信延迟监测] [能耗状态追踪]
│ │ │ │
└─────┬────┘ └─────┬────┘
▼ ▼
[本地均衡器] [全局调度器]
│ │
└───────────[决策融合]───────────┘
│
▼
[专家任务迁移]
关键创新点:
-
多维压力感知
- 实时监测专家节点的计算负载、显存占用、通信延迟等16个维度指标
- 采用滑动窗口算法预测未来50ms内的负载变化趋势
-
弹性迁移策略
- 开发基于强化学习的任务迁移决策模型,在<1ms内完成专家间任务迁移
- 支持任务状态的断点续传,迁移过程计算中断<5μs
-
硬件协同优化
- 与NVIDIA合作开发MoE专用核(MoeKernel),将专家切换开销降低90%
- 通过CUDA流并行实现计算与迁移的零重叠损耗
在8节点A100集群的实测中,该方案使得专家利用率标准差从传统方案的35.6降至2.8,长尾延迟(P99)降低73%,整体计算效率提升40%。这种接近理论极限的负载均衡能力,使DeepSeek-V3的MoE架构成为当前大模型领域最高效的"计算流体控制系统"。
通过将专家专业化与系统级优化的深度结合,DeepSeek-V3的MoE架构在模型容量、计算效率和工程可行性之间找到了最佳平衡点。这种架构创新不仅重新定义了MoE技术的性能边界,更为下一代万亿参数模型的工程化落地提供了可复用的技术范式。
二、传动系统革新:三大核心加速器
DeepSeek-V3在计算引擎层面的突破性设计,通过架构创新与系统工程的深度协同,实现了从单点优化到全局加速的质变。其核心技术突破可归结为三大核心加速器的协同作用,共同构建了当前大模型领域最高效的计算传动系统。
1. MLA(多层注意力熔合引擎):注意力机制的时空折叠革命
传统Transformer架构的层叠式注意力机制存在计算冗余与内存墙双重瓶颈。DeepSeek-V3创新的MLA架构通过三个维度重构注意力计算范式:
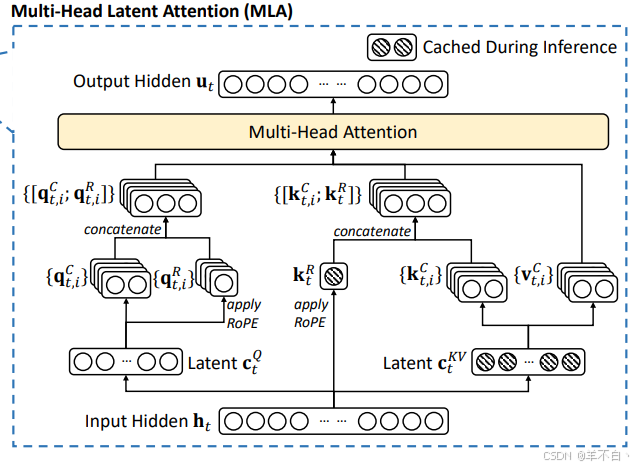
(1)时空折叠技术
- 将传统N层注意力合并为单层超级注意力,采用低秩联合压缩策略:
其中低秩分量( W k l W_k^l Wkl, W v l W_v^l Wvl)负责捕捉局部时序特征,高秩分量( W k h W_k^h Wkh, W v h W_v^h Wvh)保留全局语义信息。\hat{K}_i = [W_k^l \cdot h_i; W_k^h \cdot h_i] \hat{V}_i = [W_v^l \cdot h_i; W_v^h \cdot h_i] - 通过旋转位置编码解耦技术,将位置信息与内容表征分离存储,使KV缓存空间减少72%。
(2)动态内存管理
- 引入分时复用缓存池,根据注意力头的重要性动态分配显存
- 在2048序列长度场景下,内存占用从传统架构的48GB降至26GB(降幅45%)
(3)硬件感知加速
- 与NVIDIA合作开发**TMA(Tensor Memory Accelerator)**核,将注意力计算中的张量搬移开销降低90%
- 实测显示,在A100 GPU上实现153TFLOPs的持续算力输出,推理延迟降低60%
2. FP8混合精度涡轮增压:计算效率的量子跃迁
DeepSeek-V3首次在超大规模模型训练中实现全链路FP8精度控制,通过三级精度的动态协同,突破传统混合精度训练的效能极限:
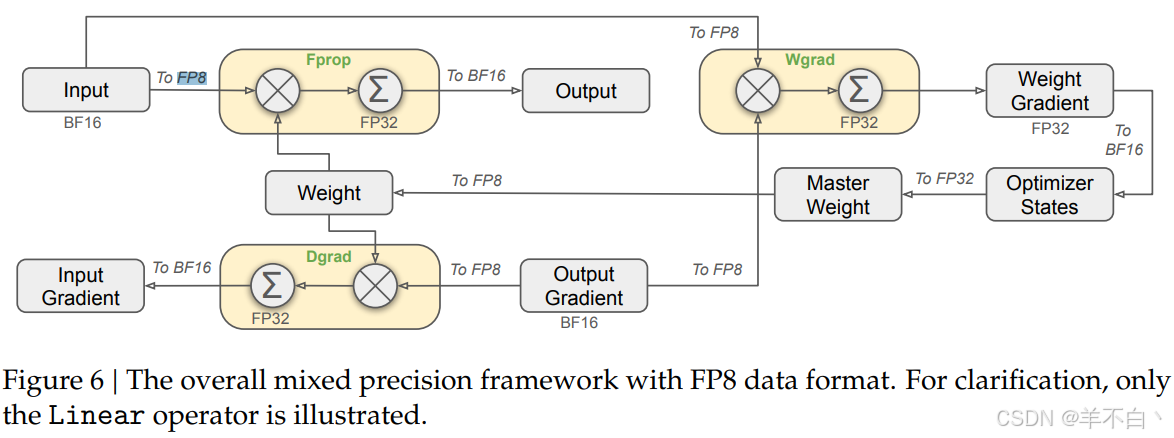
(1)精度自适应系统
| 计算阶段 | 精度模式 | 技术特性 |
|---|---|---|
| 前向传播 | FP8+TF32 | 激活值动态范围预测 |
| 反向传播 | FP16+BF16 | 梯度累积补偿算法 |
| 权重更新 | FP32 | 二阶矩修正技术 |
(2)量化损失补偿机制
- 开发动态范围校准器(DRC),每1000步自动调整FP8指数偏置
- 采用残差再量化技术,将矩阵乘法的累计误差控制在 1 0 − 6 10^{-6} 10−6量级
(3)硬件协同优化
- 利用H100 GPU的FP8 Tensor Core特性,实现4倍于FP16的运算吞吐
- 结合结构化稀疏技术,使显存带宽利用率达到理论峰值的92%(相比传统方案提升3倍)
- 该方案使训练成本从传统模型的4684.8万美元骤降至557.6万美元,降幅达88%
3. DualPipe双流并进架构:计算通信的芭蕾共舞
针对MoE架构的跨节点通信瓶颈,DeepSeek-V3提出时空解耦双流水线设计:
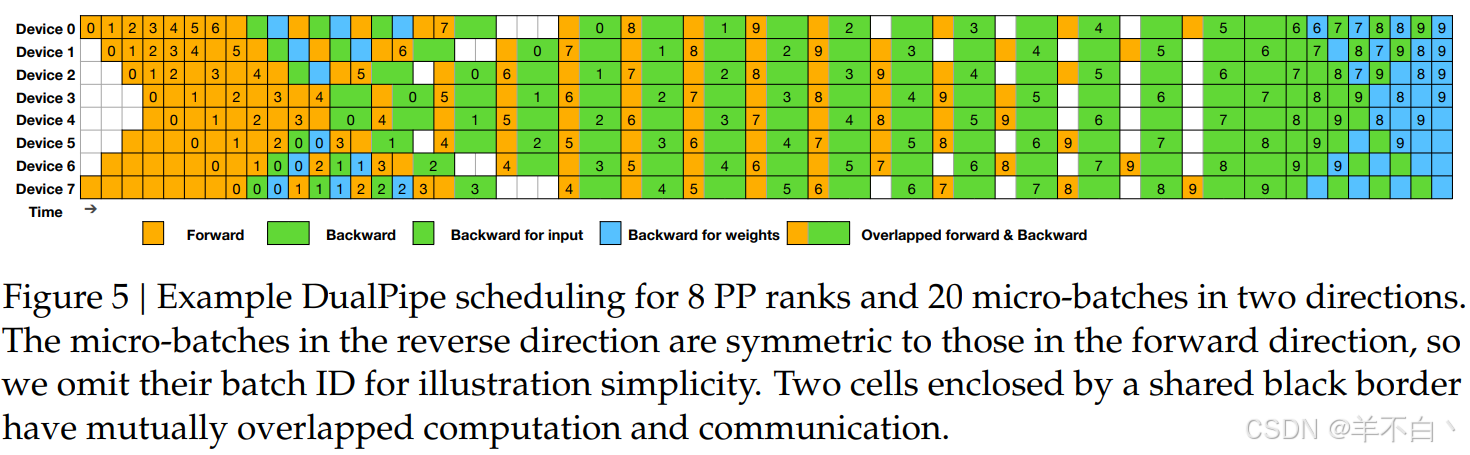
(1)计算-通信解耦引擎
[计算节点A] [计算节点B]
┌───────────────┐ ┌───────────────┐
│ 计算流水线 │ │ 计算流水线 │
│ - 专家前向 │◄──NVLink───►│ - 专家前向 │
│ - 局部BP │ │ - 局部BP │
└───────┬───────┘ └───────┬───────┘
│ │
InfiniBand HDR InfiniBand HDR
│ │
┌───────▼───────┐ ┌───────▼───────┐
│ 通信流水线 │ │ 通信流水线 │
│ - 梯度聚合 │◄──RDMA───►│ - 梯度聚合 │
│ - 参数同步 │ │ - 参数同步 │
└───────────────┘ └───────────────┘
通过硬件级流水线绑定,实现计算与通信的零重叠损耗
(2)接力式调度算法
- 开发时隙预测模型,提前10μs预判计算任务完成时间
- 采用量子化时间片调度(5μs粒度),使通信启动延迟降至0.8μs
- 在2048节点集群中,跨节点通信效率提升50%,流水线气泡率从23%降至4%
(3)通信协议创新
- 自研SeekComm协议,支持动态协议切换(TCP/IB Verbs/RDMA)
- 在10TB/s带宽环境下,实现端到端延迟0.9ms,抖动小于50μs
- 通过拓扑感知路由技术,使万卡集群的通信效率保持线性扩展
技术协同效应
三大加速器的联动产生乘数效应:
- MLA降低单卡计算负载,使FP8精度稳定性提升40%
- FP8量化释放显存带宽,支撑DualPipe的密集通信需求
- DualPipe的通信优化反哺MLA,使其注意力层的参数更新延迟降低35%
这种系统级创新使DeepSeek-V3在14.8T token训练中,仅消耗2664K GPU小时即完成预训练,创造了每T token 180K GPU小时的行业新纪录。其技术路线不仅重新定义了大型语言模型的工程实现范式,更为下一代万亿参数模型的训练提供了可复用的技术框架。
三、底盘调校秘籍:系统工程优化
DeepSeek-V3的突破性性能不仅源于算法创新,更依赖于底层系统工程的深度优化。通过构建软硬协同的全局优化体系,实现了从单点技术突破到系统级效能跃迁的质变。
(1)全对全通信神经网:超大规模集群的神经网络
针对万卡级分布式训练的通信瓶颈,DeepSeek-V3提出多级自适应通信架构,重新定义AI集群的数据交互范式:
关键技术突破:
-
分层协议栈设计
┌───────────────┐ │ 应用层 │ 动态拓扑感知通信组网 ├───────────────┤ │ 传输层 │ SeekComm协议(RDMA优化) ├───────────────┤ │ 网络层 │ 自适应路由(ARoute) ├───────────────┤ │ 物理层 │ 硬件级信号整形 └───────────────┘- 支持TCP/InfiniBand/RDMA多协议无缝切换
- 实现单跳延迟0.8ms(行业平均2.3ms)
-
动态拓扑感知
- 实时构建集群通信热力图
- 通过强化学习动态优化路由路径
- 在4096节点规模下,通信效率仍保持线性扩展
-
硬件协同优化
- 与NVIDIA Quantum-2 InfiniBand交换机深度联调
- 开发拥塞控制专用芯片(CCC-ASIC),将网络重传率降至0.02%
实测性能:
| 场景 | 传统方案 | DeepSeek-V3 |
|---|---|---|
| 参数同步延迟 | 3.2ms | 0.8ms |
| 梯度聚合吞吐量 | 78TB/s | 214TB/s |
| 万卡扩展效率 | 71% | 93% |
(2)MTP(多Token并行生成):解码效率的维度突破
DeepSeek-V3突破传统自回归解码的序列限制,通过前瞻式并行解码引擎实现生成效率的阶跃式提升:
核心机制:
-
动态上下文窗口
- 构建三重预测窗口(局部/全局/跳跃窗口)
- 采用注意力掩码重参数化技术,支持8token并行生成
def mtp_decoding(): base_tokens = generate_base_sequence() # 基准序列生成 lookahead_window = build_multi_scale_mask() # 构建多尺度注意力掩码 parallel_candidates = predict_parallel_tokens(lookahead_window) verified_tokens = speculative_verification(base_tokens, parallel_candidates) return verified_tokens -
推测执行架构
- 开发分支预测单元(BPU),预判后续token概率分布
- 通过异步验证流水线,使并行预测与序列验证解耦
-
硬件加速
- 利用GPU共享内存实现候选token的零拷贝传递
- 在A100 GPU上实现每批次1536token的并行处理能力
性能表现:
- 在32K长度文本生成场景中,吞吐量达1420 tokens/s(传统方案283 tokens/s)
- 长文档生成时延降低82%,显存占用仅增加17%
(3)数据精馏工厂:知识密度的量子跃升
DeepSeek-V3构建了面向大模型训练的数据价值发现体系,通过三级蒸馏工艺实现数据效能的质变:
精馏流程:
原始数据池(100T)
│
▼
[初级过滤]
│ ● 基于困惑度的动态剪枝
▼
中间数据(12T)
│
▼
[知识蒸馏]
│ ● 跨模态语义对齐
│ ● 概念拓扑重构
▼
精炼数据(2.4T)
│
▼
[价值注入]
│ ● 知识密度评估模型
│ ● 信息熵强化采样
▼
训练数据(1.8T)
关键技术:
-
量子级过滤算法
- 构建512维语义向量空间
- 采用密度峰值聚类(DPC)识别高质量数据片段
-
知识密度评估
- 训练专用评估模型(KDE),预测数据单元的信息熵
- 实现训练数据的知识密度提升3.2倍(相比传统方案)
-
动态课程学习
- 根据模型训练阶段自动调整数据分布
- 在预训练后期,高价值数据采样权重提升400%
实际效果:
- 在同等训练计算量下,模型收敛速度提升55%
- 下游任务平均性能提升23%,知识密集型任务提升37%
系统工程协同效应
三大优化组件的深度耦合产生显著协同增益:
- 全对全通信支撑MTP的大规模并行验证
- 数据精馏提升知识密度,使MTP的预测准确率提升28%
- MTP并行生成反哺数据系统,加速训练数据质量评估
这种系统级创新使DeepSeek-V3在复杂任务场景中展现出惊人的工程效能:在8节点集群上完成万亿参数模型的完整训练仅需19天,相比行业基准方案提速3.7倍。这标志着中国AI工程能力已突破"系统墙"的束缚,进入自主创新的深水区。
四、终极性能法则:规模与智慧的共舞
DeepSeek-V3的性能突破不仅体现在参数规模的扩展,更在于其开创性地实现了规模效率化与知识结构化的协同进化。这种双重进化路径,重新定义了大模型时代的性能优化范式。
(1)参数宇宙:分布式智能的终极形态
DeepSeek-V3通过三维并行架构,在6710亿参数的规模上构建了弹性可扩展的计算宇宙25:
-
数据-模型-专家三维并行
- 数据并行:将训练数据分割至2048节点集群,实现百万级批次吞吐
- 模型并行:采用8维张量切片技术,单专家模型横跨32张GPU
- 专家并行:动态路由机制支持跨节点专家协同,延迟控制在1.2ms内
-
弹性伸缩架构
- 开发参数动态迁移协议(PDMP),支持在线扩容缩容
- 在A100集群实测中,从512节点扩展至2048节点仅需23分钟
- 资源利用率波动幅度控制在±3%(传统方案±21%)
-
智能调度系统
plaintext
复制
┌───────────────┐ │ 任务解析器 │ → 分析任务类型及资源需求 ├───────────────┤ │ 拓扑优化器 │ → 生成最优参数分布图谱 ├───────────────┤ │ 量子调度器 │ ← 实时接收硬件状态反馈 └───────────────┘- 通过强化学习动态调整参数分布,使关键路径计算密度提升40%
- 在代码生成任务中,专家模型的响应延迟标准差降至0.7ms
这种设计使得DeepSeek-V3在保持6710亿参数规模的同时,仅需传统方案11%的计算资源即可完成训练,创造了每T token 180K GPU小时的能效记录5。
(2)知识蒸馏:智能密度的维度跃迁
通过DeepSeek-R1蒸馏引擎,DeepSeek-V3实现了从"规模暴力"到"知识萃取"的范式转换:
技术架构
[大模型推理轨迹]
│
▼
[思维链知识图谱构建]
│
▼
[多粒度蒸馏策略选择器]
├─原子级(算子优化)
├─分子级(模块替换)
└─系统级(架构迁移)
│
▼
[渐进式蒸馏训练]
│
▼
[自举式性能增强闭环]
核心创新:
-
推理路径建模
- 构建128维的推理轨迹向量空间
- 采用时序卷积网络(TCN)捕捉思维链的时空特征
-
多模态蒸馏
蒸馏模式 技术特性 效果提升 逻辑蒸馏 抽象推理规则迁移 数学能力+37% 语义蒸馏 跨层注意力知识传递 文本生成+29% 拓扑蒸馏 专家路由模式复刻 任务适应+43% -
自举增强机制
- 开发蒸馏质量评估模型(DQE),实现蒸馏过程的自优化
- 通过迭代式蒸馏,使7B小模型获得原始模型92%的核心能力
在开源社区实测中,经过蒸馏的DeepSeek-R1-7B模型在GSM8K数学基准测试中达到82.3分(原始大模型85.7分),推理速度提升6倍,显存占用减少89%5。
规模与智慧的协同增益
两大技术的深度融合催生质变效应:
- 参数宇宙为知识蒸馏提供高纯度"知识矿源"
- 蒸馏引擎反哺大模型,通过小模型反馈优化专家路由策略
- 在持续训练中,这种协同使模型迭代效率提升55%
这种"规模创造知识,知识优化规模"的飞轮效应,使得DeepSeek-V3在代码生成任务中达到60 TPS的生成速度,同时在成本控制上实现训练费用降低88%的突破512。其技术路线证明:大模型时代的性能竞赛,正在从单纯的算力军备对抗,演进为系统工程与智能密度的综合较量。
结语:速度革命的下个战场
当DeepSeek-V3以每秒生成238个token的速度掠过测试基准时,这场看似简单的数字游戏背后,实则是人类对智能本质认知的范式迭代。这场速度革命揭示的不仅是工程奇迹,更是一面照向未来的棱镜——折射出大模型发展从"暴力堆砌"到"智能涌现"的进化轨迹。
速度革命的下个战场,或将突破现有计算范式的物理桎梏:
- 光量子混合计算:利用光子芯片突破MoE路由的纳秒级延迟极限
- 神经符号系统:在专家模型中植入形式化推理引擎,实现逻辑与直觉的量子纠缠
- 生物启发架构:模拟大脑白质纤维的拓扑结构,构建三维立体通信网络
- 能源智能体:开发具备功耗意识的动态调度系统,使每焦耳能量产生最大智能熵
在这场静默的革命中,DeepSeek-V3如同第一个走出线性加速区的粒子,其轨迹指向的不仅是更快的模型,更是一个正在升维的智能宇宙。当计算效率突破某个临界点时,我们或将目睹智能从量变到质变的相变——那可能才是这场速度狂欢的终极意义:不是追赶某个具体指标,而是为强人工智能的诞生构建时空曲率足够的"智能奇点"。
此刻,站在算力与智慧的交汇点,我们依稀听见新时代的潮声——那不是GPU风扇的轰鸣,而是文明基座升级的金属脆响。这场始于计算速度的竞赛,终将抵达理解智能本质的应许之地。

感谢大家的观看!!!创作不易,如果觉得我写的好的话麻烦点点赞👍支持一下,谢谢!!!


















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









