







前言
一直觉得PCA还是比较简单容易理解的,但是到了Probabilistic PCA(PPCA)就开始觉得复杂起来。PCA出来已经有100年时间,而PPCA到了1999年才出来。这段时间看了这方面的资料,以下将自己的理解记录一下
介绍
假设有数据
X
,
X
∈
R
m
×
n
\LARGE X,X\in \mathbb{R}^{m\times n}
X,X∈Rm×n,且各列已经以0作为均值中心化,且相互独立。第i行表示为第i个观察样本
x
i
\LARGE x_i
xi,不是变量。未加说明,所有向量为列向量
X
=
[
x
1
,
⋯
,
x
m
]
T
\LARGE X = [x_1,\cdots,x_m]^T
X=[x1,⋯,xm]T
一个潜在变量模型可以表述为下述形式:
x
=
W
z
+
μ
+
ϵ
\LARGE x = Wz+\mu+\epsilon
x=Wz+μ+ϵ
z是潜在变量,W属于潜在因子,和权值矩阵不一样。由于X已经中心化,这里的均值
μ
\mu
μ可以忽略。给定不同的
ϵ
\epsilon
ϵ,这个模型可以衍生出PCA,PPCA,Factor Analysis(FA)。
PCA
最熟悉的PCA目标是如下的形式
a
r
g
m
a
x
w
∣
∣
X
w
∣
∣
2
2
\LARGE arg \ \underset{w}{max} \ ||Xw||_2^2
arg wmax ∣∣Xw∣∣22
这个假定有一些粗暴的认定方差最大的方向w,代表了数据X中的大多数信息,在计算上,跟概率没有什么直接的联系。
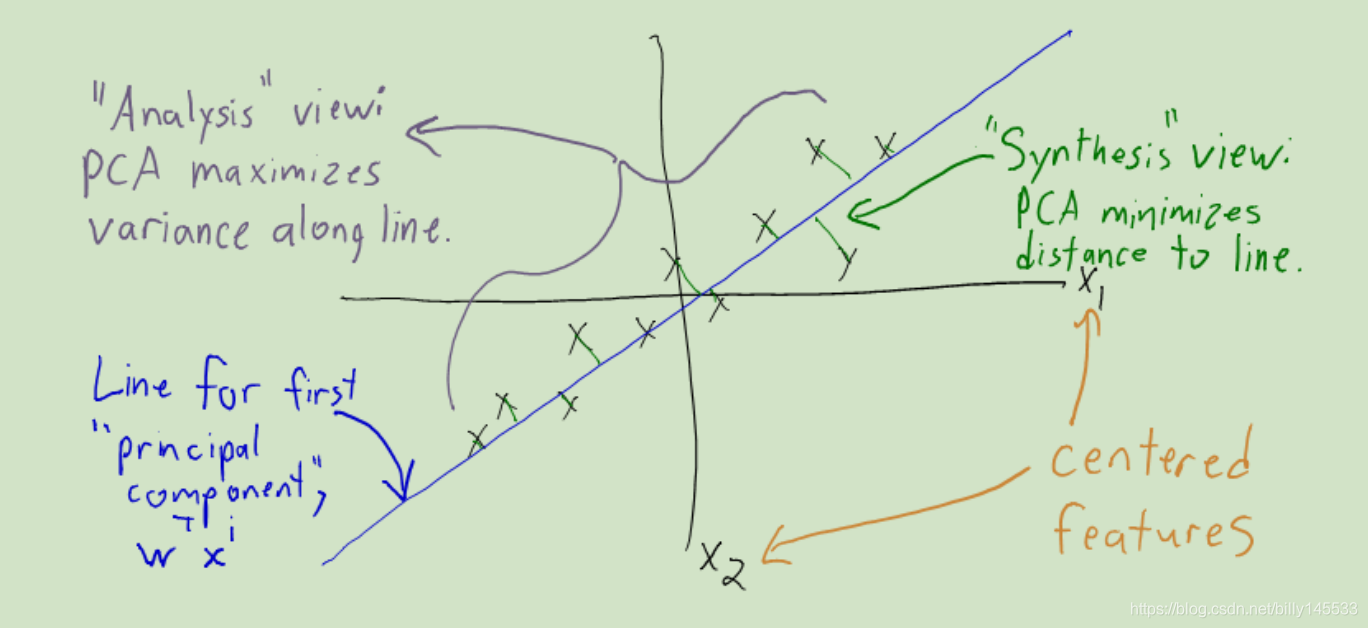
令
ϵ
→
0
\epsilon \rightarrow 0
ϵ→0
⇒
x
=
W
z
X
=
[
x
1
,
⋯
,
x
m
]
T
=
[
W
z
1
,
⋯
,
W
z
m
]
T
=
[
z
1
,
⋯
,
z
m
]
T
W
T
=
Z
W
T
a
r
g
m
a
x
W
∑
i
=
1
m
∣
∣
z
i
−
μ
z
∣
∣
2
2
=
∑
i
=
1
m
∣
∣
W
T
x
i
∣
∣
2
2
=
t
r
(
W
T
X
T
X
W
)
\Rightarrow x = Wz\\ X = [x_1,\cdots,x_m]^T=[Wz_1,\cdots,Wz_m]^T=[z_1,\cdots,z_m]^TW^T=Z W^T\\ \underset{W}{argmax} \ \sum_{i=1}^{m}||z_i-\mu_z||_2^2=\sum_{i=1}^{m}||W^Tx_i||_2^2 =tr(W^TX^TXW)
⇒x=WzX=[x1,⋯,xm]T=[Wz1,⋯,Wzm]T=[z1,⋯,zm]TWT=ZWTWargmax i=1∑m∣∣zi−μz∣∣22=i=1∑m∣∣WTxi∣∣22=tr(WTXTXW)
PPCA
x
∼
N
(
W
z
,
σ
2
I
)
,
z
∼
N
(
0
,
I
)
x \sim N(Wz,\sigma^2I),z \sim N(0,I)
x∼N(Wz,σ2I),z∼N(0,I)
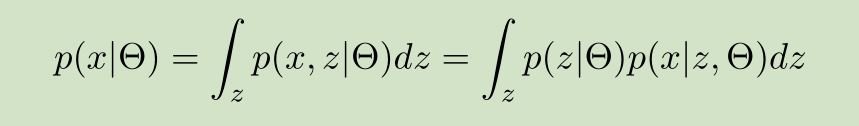
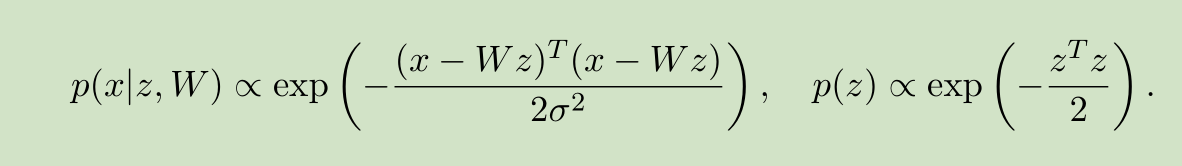
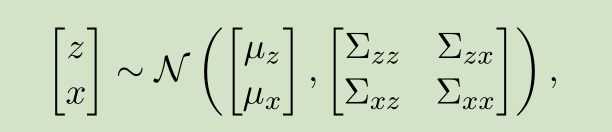
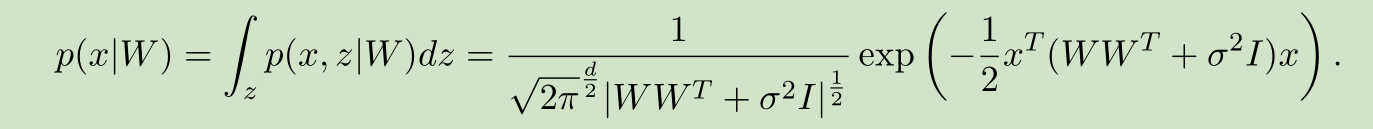
PPCA允许数据中带有的白噪声,一定程度上,能更好的反应真实的数据。但在实际应用中,PPCA似乎并没有比PCA好多少。
Factor Analysis
x ∼ N ( W z , D ) , z ∼ N ( 0 , I ) x \sim N(Wz,D),z \sim N(0,I) x∼N(Wz,D),z∼N(0,I) D是对角阵。FA是没有解析解的,它的因子解析也很随意,带有很大的主观性。
总结
PCA是PPCA的特殊形式,而PPCA又是FA的特殊形式
参考文献
- Michael E. Tipping, Christopher M. Bishop. Probabilistic Principal Component Analysis[J]. Journal of the Royal Statistical Society, 1999, 61(3):611-622.
- https://www.cs.ubc.ca/~schmidtm/Courses/540-W16/L12.pdf
这个课程感觉相当棒,推荐一下

















 374
374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









