






本文参考:https://blog.csdn.net/jteng/article/details/54344766
可能理解有偏差,欢迎批评指正
在python中,采集随机样本其实很简单,有很多函数可以直接实现。比如
#抽取一个标准正态分布随机样本,并画出密度曲线
import numpy as np
import seaborn as sns
x=np.random.normal(0,1,100000)
sns.kdeplot(x)在这里不是因为要产生完全随机数而产生的这种方法,因为若密度函数较为复杂,没有直接的程序进行采样。这里选用Rejection Sample进行采样。
蒙特卡洛
蒙特卡洛是一种计算机模拟方法。我暂时理解的为用大量点对各种值进行估计。比如计算面积,那概率对面积进行估计。计算积分,用面积计算定积分等等。在Rejection Sample采样中,运用概率筛选采样值。具体不说,百度一下就能找到。
算法
算法流程大致如下:对于想采样的密度函数p(x)
1. 选取一个易于采样的分布q(x)。比如说均匀分布或者正态分布等等, 反正就是计算机能够自己采样的即可。
2. 选择一个常数k,使得能够使 k*q(x)总是大于p(x)的。这样是为了能够产生一个均匀分布。
3. 将第一步产生的样本 带入到密度函数p(x)中,产生一个概率
。与第二步均匀分布产生的概率
进行比较。若
,那么这个样本就是想采样的一个样本。
4. 重复上述步骤。对每一个样本都进行比较。
然后撰写python代码:
import numpy as np
import seaborn as sns
import math
#对于该方法,我选取标准正态分布作为中间分布
class Rejection_Sample:
def __init__(self,n,k,model):
self.n=n
self.model=model
self.k=k
self.sample=self.rejection()
def q(self,n):
miu=1.4
sigma=1.2
L=np.random.normal(miu,sigma,n)
L_gauss=1/(math.sqrt(2*math.pi)*sigma)*np.exp(-np.power((L-miu),2)/(2*sigma**2))
u=np.random.uniform(0,self.k*L_gauss)
return L,u
def rejection(self):
L,u=self.q(self.n)
sample=[]
count=0
for i in range(self.n):
a=self.model(L[i])
if a>u[i]:
sample.append(L[i])
count +=1
print(count)
return sample
def get_sample(self):
return self.sample
if __name__=="__main__":
#这里的模型必须是密度函数,不能是分布函数
def model(x):
return 0.3*np.exp(-(x-0.3)**2) + 0.7* np.exp(-(x-2.)**2/0.3)
q=model
sample=Rejection_Sample(1000000,3,q).get_sample()
sns.kdeplot(sample)运行结果如下:
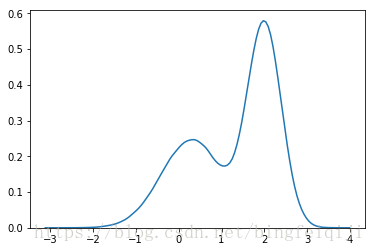
与参考的博主图像吻合,其中编程遇到的错误如下:
1. 先开始编写程序的时候,总是出现结果与实事不一致的情况,后来排查问题,我发现原算法讲的是q(x)与k想结合,而不是x。意思就是运用np.random.normal()函数采样完,需要加上一个该采样的密度函数,求取密度,比如这个函数是根据抽样分布采样的,就必须加上一个期望和方差相同的正态密度函数求取概率。
2. 加上之后,我发现还是出现错误。于是排查问题,最后发现正态分布的密度函数我记错了。导致结果与实事有很大的偏差。
3. 最后从均匀分布采取的样本,需要和k*p(x)进行对比。注意这里是均匀分布采取的样本,而不是在对均匀分布求概率密度了。因为均匀分布的概率密度是固定的。突然觉得想出这个办法的人真是天才。
方法解释
其实我在想,为什么这样就能采样了?如果仅仅是画出函数图像,可以借助
import numpoy as np
np.random.linspace(-3,3,int(1e6))这个函数就能够画出函数图像,但是目标是求出样本,这就是一个不知道如何下手的问题。
由于计算机只能对均匀分布进行采样,所以任何其他分布都是由均匀分布采得的样本变换而来的。
我看比如说常见的分布函数,正态分布,指数分布等等连续性或者离散型分布,已经有方法去进行采样。比如说正态分布我看的有两种方式采样:第一种是Box-Muller方法进行采样,这种方法我本来以为是对二维数据进行采样的,但是看到有博主写到一维采样也可以用这个。第二种是利用中心极限定理,对多个均匀分布进行叠加获得的。其他分布暂时不说了。由于我不是计算机模拟方向的,做了这么多工作就是为了搞懂多重插补法。所以暂时不进行深入研究。
也就是说可以根据数学推导,利用均匀分布就能对已有的不同分布进行采样。但是对于那些比较复杂的分布。或者说你自己定义的一个密度函数。就没有一种方法进行采样。这样就需要一种方法能够实现目标。
按照https://blog.csdn.net/Eric2016_Lv/article/details/56674841 这位博主的博客上写的,突然有种顿悟的感觉。我一直在思考,为什么从另一个分布中采取的样本点,就能够用于目标函数的采样中去了呢。。
答案就是“从哪个位置抽出的点比较容易接受”。也就是说当某个密度函数的密度值比较高了。那么对这个样本点就容易接受,比较低的就不行。因此我认为自然而然的就必须有这样的一个条件在里面:
1. 从q(x) 中选取的样本点必须能够整个的包含p(x) 的所有可能值。要么就是能够包含很大一部分的可能值。
因此自然而然样本点就是那些样本点。但是这些样本点的分布就是自己定义的那个密度一样,哪些样本点的概率大就容易接受样本点。所以理解到这里。我就认为辅助函数q(x)的选取用均匀分布u(a,b)选取最好了。
以下就是我改进的python代码:
# -*- coding: utf-8 -*-
"""
Created on Sat Aug 18 09:32:52 2018
@author: denglihui
"""
import numpy as np
import seaborn as sns
import math
#对于该方法,我选取标准正态分布作为中间分布
class Rejection_Sample:
def __init__(self,n,k,model,method="normal"):
self.n=n
self.model=model
self.k=k
self.method=method
self.sample=self.rejection()
def q(self,n):
miu=1.4
sigma=1.2
a=-5
b=5
if self.method=="normal":
L=np.random.normal(miu,sigma,n)
L_distri=1/(math.sqrt(2*math.pi)*sigma)*np.exp(-np.power((L-miu),2)/(2*sigma**2))
if self.method=="uniform":
L=np.random.uniform(a,b,n)
L_distri=np.array([1/(b-a) for _ in L])
u=np.random.uniform(0,self.k*L_distri)
return L,u
def rejection(self):
L,u=self.q(self.n)
sample=[]
count=0
for i in range(self.n):
a=self.model(L[i])
if a>u[i]:
sample.append(L[i])
count +=1
print(count)
return sample
def get_sample(self):
return self.sample
if __name__=="__main__":
#这里的模型必须是密度函数,不能是分布函数
def model(x):
return 0.3*np.exp(-(x-0.3)**2) + 0.7* np.exp(-(x-2.)**2/0.3)
q=model
sample=Rejection_Sample(1000000,0.025,q,method="uniform").get_sample()
sns.kdeplot(sample)但是我先在发现不同的q(x)最后得到的样本点不同,想当然认为的均匀分布最好的,也并不是这样。所以我觉得这个方法并不是特别好。
黑箱
在这里,我有以下问题没有搞懂:
1. 怎么选取辅助函数q(x)
2. 常数k值怎么确定
3. 为什么辅助函数相差一点,最终采样结果相差很大

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









