






在上一章中,我们为了解决拟合混合高斯模型的拟合问题已经接触了EM算法。这一章里,我们会进一步扩展EM算法的应用,你会发现它可以用于解决一大类包含隐参数的估计问题。让我们从Jensen不等式开始我们的讨论。
1 Jensen 不等式
设
f
是一个定义域为实数的函数,回忆前面的内容,当
定理. 设
不仅如此,若
f
为严格凸时,那么
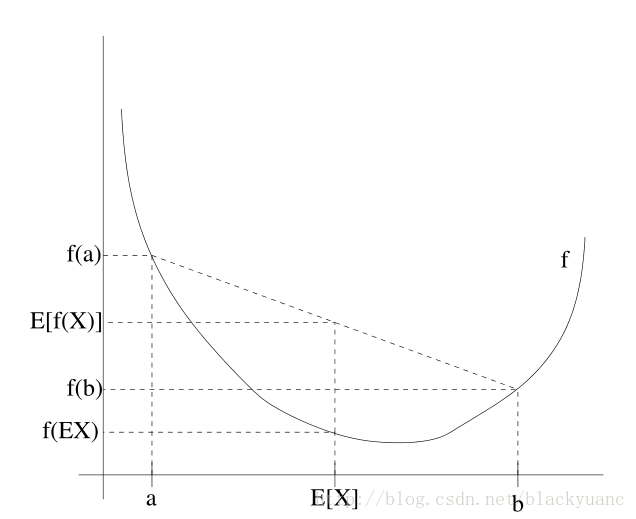
图中凸函数f是实线绘制的曲线,随机变量
X
有50%的概率是a,50%的概率是b,所以
2 EM算法
设某估计问题中有m个独立的样本 {x(1),…,x(m)} 。我们希望使模型 p(x,z) 的参数和数据拟合,则对数似然函数写成如下形式:
由于无法直接求解参数 θ 的极大似然估计,引入隐参数 z(i) ,如果假设隐参数的值已知,那么求解极大似然估计就会变得很容易。
这时求最大似然估计,EM算法是一个行之有效的方法。直接最大化
ℓ(θ)
很困难,但我们的策略是先构造
ℓ
的下界(E步骤),再最优化其下界(M步骤)。过程如下图所示

对每一个
i
,设
因为 f′′(x)=−1/x2<0 , f(x)=log x 是一个凹函数。第四步可以根据Jensen不等式求得。
对于任意的分布
Qi
,方程(3)给出了对数似然函数
ℓ(θ)
的下界。这时
Qi
分布有很多可能的选择,我们应该如何决定呢?如果我们现在有关于参数
θ
的假设值,那么很自然下界的选择要和
θ
相关。
要使下界的选择与
θ
相关,我们需要推导中使用Jensen不等式的地方变为相等。为此期望值需要是一个常数变量。则有:
为使常数c不依赖 z(i) 的取值。我们需要 Qi(z(i)) 与 p(x(i),z(i);θ) 成比例。
实际上因为 ∑zQi(z(i))=1 ,这进一步告诉我们:
我们令 Qi 为给定 x(i) 与参数 θ 关于 z(i) 的后验概率。
通过选择 Qi ,我们求对数似然函数的最大下界,这是E阶段。通过改变参数 θ ,我们求方程(3)中的最大值。重复执行一上两个步骤就是EM算法:
循环至收敛 {
(E步骤)对每个i,令:
(M步骤) 令:
}
EM算法是一个一致收敛的算法。我们在算法描述时说循环至收敛。实际情况下判断收敛的方式一般为,当对数函数的增长小于某一设定值时,我们认为EM算法继续改善的能力已经很小了,即认为其收敛。















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









