







关于GMM模型的资料和 EM 参数估算的资料,网上已经有很多了,今天想谈的是GMM的协方差矩阵的分析、GMM的参数更新方法
1、GMM协方差矩阵的物理含义


用中文来描述就是:

注意后面的那个除以(样本数-1),就是大括号外面的E求期望 (这叫无偏估计)
上面公式也提到了,协方差本质上是就是很多向量之间的内积,内积的定义如下:

用个具体例子说明, 比如一组数二维数据(二维的数据好说明,比较直观),它的所有X值、Y值看成一对儿数据,我们得到它们的协方差如下: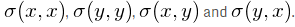
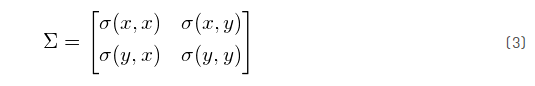
很显然,对角线上的数值肯定是大于零的(平方和),其他非对角线上的值是关于主对角线对称的,这种矩阵叫 正定矩阵 (Positive Definite)
根据向量内积的物理意义和协方差矩阵的几何意义,我们可以知道:
协方差矩阵实际上形容的就是这些数据之间的协同分布情况,比如偏向性、数据聚集程度等。
比如用matlab生成一组二维的数据:
mu = [2 3];
SIGMA = [ 3 1; 1 1];
data(1:100,:) = mvnrnd(mu,SIGMA,100);
画出来它是这样:

根据协方差矩阵的几何意义,它的两个特征值的开方,即使从单位矩阵(1,0;0,1)圆 变成 椭圆 的两个轴的放大倍数,seta角就是旋转角度

对矩阵进行特征分解:
[V,l] = eig(cov);
S = sqrt(l); %开方,求的放大倍数
R = V; %旋转矩阵
Tm = R*S; %旋转+尺度,就是由圆变成有一定倾斜角的椭圆的过程
V = 0.3827 -0.9239 ; -0.9239 -0.3827
l = 0.5858 0 ; 0 3.4142
一般的旋转矩阵是这样:

但我们这里用的旋转矩阵是从Y轴开始算旋转角的,并且X轴要做负对称,所以旋转矩阵的结果如下:



2、GMM参数更新方法
一般的,GMM的参数更新方法都是EM的方法,这里说的是梯度下降的方法。
梯度下降也是求一个函数最小值的方法,相比EM的算法,更新速度比较快,缺点是比较容易陷入局部收敛点。

比如给定了一组数(dataset 有一定维度),让求一个概率最大下的混合高斯函数的参数(目标:每个GMM的 权重系数、均值,协方差)
我们定义了概率函数,
由于给定了一组数据(dataset),我们采用 batch gradient descent 的方法,实际上还有随机梯度的方法,就是随机用一个点去更新,基本思路相同。
实际情况下,求上面那个表达式的最大值比较困难的,我们增加一个负号,就可以使用梯度下降法(下降法只能求最小值,最大值一般不用这个方法,对于一般的函数求最大值,需要先判断是否收敛再求最大值,或者给定参数范围,这里不讨论),再用log方便表达式求导数,最后还要知道各个待定参数的导数。即我们要计算下面表达式在最小值的情况下,它的参数是什么

回顾一下梯度下降法:梯度下降法就是沿着 梯度,不断的去更新参数值,最后达到一定的收敛条件,得到我们要的参数
这里面η 是学习率 ,后面的重点就是求梯度了(▽为对矢量做偏导,它是一个矢量, ▽U表示为矢量U的梯度)
幸好在matrix code book里面已经给出了三个重要参数的导数: 地址是:【https://www.math.uwaterloo.ca/~hwolkowi/matrixcookbook.pdf】

注意上面的 协方差矩阵需要保证正定,否则没有办法求似然概率。
把梯度下降法的求GMM混合参数的方法写成如下流程:
给定一组dataset,在这个dataset下进行参数估计
初始化一组GMM的初始值,混合权重,均值,协方差矩阵 Xk(注意Xk不是dataset,是混合参数)
while (比较Yk+1和Yk之间的差值,或者循环次数,如果满足,跳出)
计算在这个初始值下的似然概率值(注意用log表达,注意我们为了求最小值给了负号,注意各个dataset中的点的似然概率是乘积关系)
计算各个偏导数,使用梯度下降的方法更新新的Xk+1 = Xk - η*∇(Xk)
比较Xk+1和Xk下面下,这一组dataset的总体似然概率值之差,Yk+1和Yk
Xk+1=Xk ,继续循环
3、GMM参数更新方法EM和梯度下降法遇到的问题
用EM算法来拟合分类:

使用梯度下降法拟合:

梯度下降法的拟合结果比较依赖于初始值
下面谈一下,遇到非正定协方差矩阵的问题;
我们的参数更新方法:
可能出问题的就是(在某些情况下)协方差矩阵是非正定(非正定没法Cholesky,没法求概率),因为是两个正定矩阵的相差,它们的差不一定能保证正定,这时候有几种方法;
1、修改更新之后的协方差矩阵,使得特征值为负数的变成 eps (matlab最小正数),结果椭圆塌陷,收敛到两个直线上:


可以认为塌陷到直线的两类是多余的。
2、修改更新之后的协方差矩阵,使得特征值为负数的变成 1它会重新从圆开始计算开始收敛:

3、保持协方差矩阵,若更新之后的协方差矩阵特征值为负数,则保持协方差矩阵不变:

结果最终收敛。
另外多提一句
python中的scipy.stats是可以容许奇异的。是不是对计算logpdf有帮助。。。















 2593
2593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









