







相关博客:
【自然语言处理】【知识图谱】利用属性、值、结构来实现实体对齐
【自然语言处理】【知识图谱】基于图匹配神经网络的跨语言知识图谱对齐
【自然语言处理】【知识图谱】使用属性嵌入实现知识图谱间的实体对齐
【自然语言处理】【知识图谱】用于实体对齐的多视角知识图谱嵌入
【自然语言处理】【知识图谱】MTransE:用于交叉知识对齐的多语言知识图谱嵌入
【自然语言处理】【知识图谱】SEU:无监督、非神经网络实体对齐超越有监督图神经网络?
一、简介
1. 目标
知识图谱(KG)可以看做是三元组的集合,每个三元组(triples)均是由subject、predicate和object组成。知识图谱中的三元组主要包含两种,一种是relation triples,另一种是attribute triples。其中,relation triples中的subject和object均是实体,而predicate通常被称为关系。attribute triples中的subject是实体,而object则是取值(value),该值通常是一个数值或者文本,其predicate通常称为属性。
Entity Alignment(EA)的目标是从多个图谱中构建出一个统一的图谱。目前基于GNN的方法在EA任务上的不错,但是并没有利用到attribute triples。因此,本文的目标是利用attribute triples来进一步改善实体对齐。本文的核心假设是:相同的实体通常共享相似的属性。
2.挑战
属性合并挑战(Attribute Incorporation Challenge)
将relation triples和attribute triples进行统一建模比单独建模这两种三元组更加的有效,因此这样就能将attribute triples中获得的对齐信号通过relation triples传递到其他实体上。先前的工作是使用独立的网络来分别学习relation triples和attribute triples。
此外,学习实体不同属性(attribute)的重要性对于判断实体等价也非常重要。例如,对于城市实体,属性Time Zone的重要性显然低于属性Name,因此许多城市共享Time Zone。
数据集偏差挑战(Dataset Bias Challenge)
许多EA数据集在属性Name上具有偏差,这导致了许多EA模型的表现被高估了。在数据集DBP15k中约有60%-80%的种子等价实体可以通过属性Name进行对齐。
3.贡献
- 为了解决Attribute Incorporation Challenge问题,我们提出了Attributed Graph Neural Network(AttrGNN)来统一学习attribute triples和relation triples,其能够动态的学习属性和值的重要度。
- 在AttrGNN中,我们提出了一种attributed value encoder来对属性和值进行选择和聚合,并使用一个mean aggregator将属性相似的信号传递给邻居实体。
- 在AttrGNN中,由于不同类型的属性具有不同的相似度度量方式,论文将整个KG划分成4个子图,然后利用GNN分别学习它们的表示。
- 最后,论文提出了2种方法来将4个子图的表示集成在一起。
- 为了缓解Dataset Bias Challenge,我们设置了一个较难的实验。具体来说,我们从测试集中挑选属性name相似度最小的等价实体来构造一个更难的测试集。
二、方法
1.整体框架
1.1 知识图谱(KG)
知识图谱可以表示为6元组有向图 G = ( E , R , A , V , T r , T a ) G=(E,R,A,V,T^r,T^a) G=(E,R,A,V,Tr,Ta),其中 E E E、 R R R、 A A A、 V V V分别指实体(Entity)、关系(Relation)、属性(Attribute)和值(Value)的集合,而 T r = { ( h , r , t ) ∣ h , t ∈ E , r ∈ R } T^r=\{(h,r,t)|h,t\in E, r\in R\} Tr={(h,r,t)∣h,t∈E,r∈R}和 T a = { ( e , a , v ) ∣ e ∈ E , a ∈ A , v ∈ V } T^a=\{(e,a,v)|e\in E,a\in A,v\in V\} Ta={(e,a,v)∣e∈E,a∈A,v∈V}是关系三元组(relation triples)和属性三元组(attribute triples)的集合。
1.2 实体对齐(Entity Alignment,EA)
EA的目标是寻找两个知识图谱 G G G和 G ′ G' G′的一个映射,例如 ψ = { ( e , e ′ ) ∣ e ∈ E , e ′ ∈ E ′ } \psi=\{(e,e')|e\in E,e'\in E'\} ψ={(e,e′)∣e∈E,e′∈E′},其中 e e e和 e ′ e' e′是等价实体。另外,种子等价实体集合 ψ s \psi^s ψs被用作训练数据。
1.3 框架
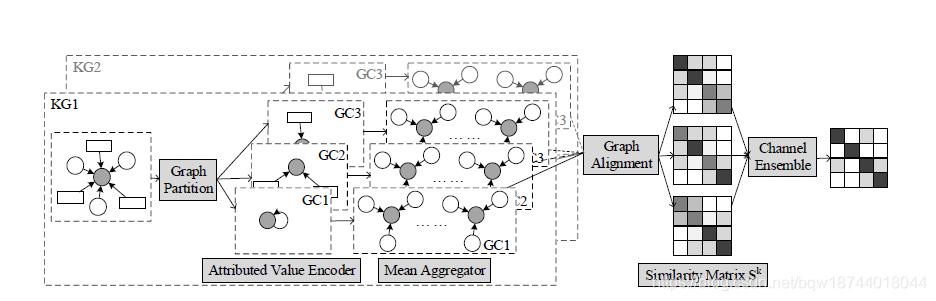
整体的框架如图1所示,其主要由4个部分组成:
(1) 图划分(Graph Partition)
负责将输入的图谱按照属性和值分为4个子图。
(2) 子图编码器(Subgraph Encoder)
利用多通道的GNN分别学习4个子图,其中每个通道是由 L L L层Attributed Value Encoder和Mean Aggregator堆叠而成。其中Attributed Value Encoder用来聚合属性和值,从而产生实体的embedding。而Mean Aggregator负责将属性对齐的特征传递到邻居实体上。
(3) 图对齐(Graph Alignment)
将两个知识图谱中不同通常的实体向量统一到同一个向量空间。
(4) 通道集成(Channel Ensemble)
将不同通道输出的相似度集成在一起,用于最终预测结果。
2.图划分(Graph Partition)
由于属性和取值具有各种各样的类型,例如字符串 S \mathbb{S} S和数字 R \mathbb{R} R。不同类型的属性具有不同的度量方式,例如数字的相似度是数字间的差值,而字符串的相似度则是基于字符串的语义。因此,论文将知识图谱按相似度度量的不同划分成了4个子图,定义为 G k = ( E , R , A k , V k , T r , T a k ) G^k=(E,R,A^k,V^k,T^r,T^{ak}) Gk=(E,R,Ak,Vk,Tr,Tak),其中 k ∈ { 1 , 2 , 3 , 4 } k\in\{1,2,3,4\} k∈{1,2,3,4}。
- G 1 G^1 G1包含了仅有Name的属性三元组,例如 A 1 = { a n a m e } A^1=\{a_{name}\} A1={aname};
- G 2 G^2 G2包含了字符串属性三元组,例如 A 2 = { a ∣ ( e , a , v ) ∈ T a , v ∈ S , a ≠ a n a m e } A^2=\{a|(e,a,v)\in T^a,v\in\mathbb{S},a\neq a_{name}\} A2={a∣(e,a,v)∈Ta,v∈S,a=aname};
- G 3 G^3 G3包含了数字属性三元组,例如 A 3 = { a ∣ ( e , a , v ) ∈ T a , v ∈ V } A^3=\{a|(e,a,v)\in T^a,v\in\mathbb{V}\} A3={a∣(e,a,v)∈Ta,v∈V};
- G 4 G^4 G4没有属性三元组,例如 A 4 = ∅ A^4=\empty A4=∅;
子图之间的属性三元组互斥,但关系三元组共享。
3.子图编码器(Subgraph Encoder)
论文设计了4种GNN通道(GCs)来编码上面的子图,分别是: G 1 G^1 G1的name通道, G 2 G^2 G2的字符串通道, G 3 G^3 G3的数字通道, G 4 G^4 G4的结构通道。这些通道均是由2中类型的GNN层构成的:Attributed Value Encoder和Mean Aggregator。其中,字符串通道和数字通道均会堆叠Attribute Value Encoder和Mean Aggregator。而name通道和结构通道由于没有属性值,则不堆叠Attribute Value Encoder。此外,name通道、数字通道、字符串通道添加了残差链接。所有的通道均使用2层的GNN。
3.1 Attributed Value Encoder
Attributed Value Encoder能够将属性和值上的特征有选择地聚合到中心实体上。这里展示如何获得实体 e e e的第一层隐藏状态 h e 1 h_e^1 he1,相同的方法会应用到所有的实体上。
给定实体
e
e
e的属性三元组
{
(
e
,
a
1
,
v
1
)
,
…
,
(
e
,
a
n
,
v
n
)
}
\{(e,a_1,v_1),\dots,(e,a_n,v_n)\}
{(e,a1,v1),…,(e,an,vn)},然后使用BERT来获取文本和数值的向量表示,最终得到属性特征序列
{
a
1
,
…
,
a
n
}
\{\textbf{a}_1,\dots,\textbf{a}_n\}
{a1,…,an}和值特征序列
{
v
1
,
…
,
v
n
}
\{\text{v}_1,\dots,\text{v}_n\}
{v1,…,vn}。将取值
v
v
v看作是节点,属性
a
a
a看作是边,然后使用类似GAT的注意力机制来将属性和取值的信息聚合至单一向量中
h
e
1
=
σ
(
∑
j
=
1
n
α
j
W
1
[
a
j
;
v
j
]
)
α
j
=
softmax
(
o
j
)
=
e
x
p
(
o
j
)
∑
k
=
1
n
e
x
p
(
o
k
)
o
j
=
LeakyReLU
(
u
T
[
h
e
0
;
a
j
]
)
\textbf{h}_e^1=\sigma(\sum_{j=1}^{n}\alpha_j\textbf{W}_1[\textbf{a}_j;\textbf{v}_j])\\ \alpha_j=\text{softmax}(o_j)=\frac{exp(o_j)}{\sum_{k=1}^{n}exp(o_k)}\\ o_j=\text{LeakyReLU}(\textbf{u}^T[\textbf{h}_e^0;\textbf{a}_j])
he1=σ(j=1∑nαjW1[aj;vj])αj=softmax(oj)=∑k=1nexp(ok)exp(oj)oj=LeakyReLU(uT[he0;aj])
其中,
j
∈
{
1
,
…
,
n
}
j\in\{1,\dots,n\}
j∈{1,…,n},
W
1
∈
R
D
h
1
×
(
D
a
+
D
v
)
W_1\in\mathbb{R}^{D_{h_1}\times(D_a+D_v)}
W1∈RDh1×(Da+Dv)和
u
∈
R
(
D
e
+
D
a
)
×
1
u\in\mathbb{R}^{(D_e+D_a)\times 1}
u∈R(De+Da)×1是可学习的参数,
σ
\sigma
σ是
ELU
(
⋅
)
\text{ELU}(\cdot)
ELU(⋅)函数,
h
e
0
h_e^0
he0是初始的实体特征。直观上来看,权重标量
α
j
\alpha_j
αj表示实体
e
e
e的初始向量表示
h
e
0
\textbf{h}_e^0
he0与属性
a
j
\textbf{a}_j
aj的相似度,而
h
e
1
\textbf{h}_e^1
he1是基于
α
\alpha
α对所有
a
\textbf{a}
a和
v
\textbf{v}
v的加权求和。
3.2 Mean Aggregator
Attributed Value Encoder是用来聚合实体
e
e
e的属性三元组,而Mean Aggregator则是用于聚合关系三元组中相邻实体的信息。基于关系三元组,实体
e
e
e的相邻实体定义为
N
(
e
)
=
{
j
∣
∀
(
j
,
r
,
e
)
∈
T
r
o
r
∀
(
e
,
r
,
j
)
∈
T
r
,
∀
r
∈
R
}
\mathcal{N}(e)=\{j|\forall(j,r,e)\in T^r or \forall(e,r,j)\in T^r,\forall r\in R\}
N(e)={j∣∀(j,r,e)∈Tror∀(e,r,j)∈Tr,∀r∈R}。那么,在给定
l
−
1
l-1
l−1层的隐藏状态
h
e
l
−
1
\textbf{h}_e^{l-1}
hel−1的情况下,Mean Aggregator定义为
h
e
l
=
σ
(
W
l
MEAN
(
{
h
e
l
−
1
}
∪
{
h
j
l
−
1
,
∀
j
∈
N
(
e
)
}
)
)
\textbf{h}_e^l=\sigma(\textbf{W}_l\text{MEAN}(\{\textbf{h}_e^{l-1}\}\cup\{\textbf{h}_j^{l-1},\forall j\in\mathcal{N}(e)\}))
hel=σ(WlMEAN({hel−1}∪{hjl−1,∀j∈N(e)}))
其中,
W
l
∈
R
D
h
l
×
D
h
l
−
1
\textbf{W}_l\in\mathbb{R}^{D_{h_l}\times D_{h_{l-1}}}
Wl∈RDhl×Dhl−1是可学习矩阵,
MEAN
(
⋅
)
\text{MEAN}(\cdot)
MEAN(⋅)向量的均值函数,
σ
\sigma
σ是非线性函数
ReLU
(
⋅
)
\text{ReLU}(\cdot)
ReLU(⋅)。
4. 图对齐(Graph Alignment)
图对齐(Graph Alignment)通过减少种子等价实体间距离的方法,实现了将两个知识图谱(KG)对应通道的向量表示统一的同一个向量空间的效果。具体来说,通过在实体嵌入空间中搜索实体
e
e
e或者
e
′
e'
e′的最近邻来为正样本
(
e
,
e
′
)
∈
ψ
s
(e,e')\in\psi^s
(e,e′)∈ψs生成对应的负样本,然后使用通道
G
C
k
GC^k
GCk的最终输出向量
h
e
L
h_e^L
heL作为实体
e
k
e^k
ek的embedding向量。最后,每个通道按下面的目标函数进行优化:
L
k
=
∑
(
e
,
e
′
)
∈
ψ
s
(
∑
e
∗
∈
NS
(
e
)
[
d
(
e
k
,
e
′
k
)
−
d
(
e
∗
k
,
e
′
k
)
+
γ
]
+
+
∑
e
∗
′
∈
NS
(
e
′
)
[
d
(
e
k
,
e
′
k
)
−
d
(
e
k
,
e
∗
′
k
)
+
γ
]
+
)
\mathcal{L}_k=\sum_{(e,e')\in\psi^s}(\sum_{e_*\in \text{NS}(e)}[d(e^k,e'^k)-d(e_*^k,e'^k)+\gamma]_{+}+\sum_{e'_*\in \text{NS}(e')}[d(e^k,e'^k)-d(e^k,e'^k_*)+\gamma]_+)
Lk=(e,e′)∈ψs∑(e∗∈NS(e)∑[d(ek,e′k)−d(e∗k,e′k)+γ]++e∗′∈NS(e′)∑[d(ek,e′k)−d(ek,e∗′k)+γ]+)
其中,
ψ
k
\psi^k
ψk是种子等价实体,
NS
(
e
)
\text{NS}(e)
NS(e)是实体
e
e
e的负样本,
[
⋅
]
+
=
max
{
⋅
,
0
}
[\cdot]_+=\text{max}\{\cdot,0\}
[⋅]+=max{⋅,0},
d
(
⋅
,
⋅
)
=
1
−
c
o
s
(
⋅
,
⋅
)
d(\cdot,\cdot)=1-cos(\cdot,\cdot)
d(⋅,⋅)=1−cos(⋅,⋅)表示consine相似度,
γ
\gamma
γ是间隔超参数。
直觉上,上面的loss分布为实体 e e e和 e ′ e' e′生成一些负样本,然后减小正样本间距离的同时加大负样本间距离。
5. 通道集成(Channel Ensemble)
基于前面得到的实体embedding,可以为每个通道推断出相似度矩阵 S k ∈ R ∣ E ∣ × ∣ E ′ ∣ , k = { 1 , 2 , 3 , 4 } S^k\in\mathbb{R}^{|E|\times|E'|},k=\{1,2,3,4\} Sk∈R∣E∣×∣E′∣,k={1,2,3,4},其中 S e , e ′ k = c o s ( e k , e ′ k ) S_{e,e'}^{k}=cos(e^k,e'^k) Se,e′k=cos(ek,e′k)是 e ∈ E e\in E e∈E和 e ′ ∈ E ′ e'\in E' e′∈E′的cos相似度。论文基于 S k S^k Sk提出了2种方法将4个通道的相似度矩阵集成为单个相似度矩阵 S ∗ S^* S∗的方法。
Average Pooling
这里假设每个通道均有相同的重要性,令
S
∗
=
1
4
∑
k
=
1
4
S
~
k
S^*=\frac{1}{4}\sum_{k=1}^4\tilde{S}^k
S∗=41∑k=14S~k,其中
S
~
k
\tilde{S}^k
S~k是标准化的
S
k
S^k
Sk,即
S
~
k
=
S
k
−
m
e
a
n
(
S
k
)
s
t
d
(
S
k
)
\tilde{S}^k=\frac{S^k-mean(S^k)}{std(S^k)}
S~k=std(Sk)Sk−mean(Sk)
SVM
利用SVM来学习通道的重要度,然后加权求和
S
∗
=
∑
k
=
1
4
w
k
S
k
\textbf{S}^*=\sum_{k=1}^4w_k\textbf{S}^k
S∗=k=1∑4wkSk
其中,权重
w
=
[
w
1
,
w
2
,
w
3
,
w
4
]
\textbf{w}=[w_1,w_2,w_3,w_4]
w=[w1,w2,w3,w4]通过下面的方式训练获得,
L
s
v
m
=
C
∑
l
=
1
m
[
y
l
⋅
m
a
x
(
0
,
1
−
w
T
x
l
)
+
(
1
−
y
l
)
⋅
(
0
,
1
+
w
T
x
l
)
]
+
1
2
w
T
w
\mathcal{L}_{svm}=C\sum_{l=1}^m[y_l\cdot max(0,1-\textbf{w}^T\textbf{x}_l)+(1-y_l)\cdot(0,1+\textbf{w}^T\textbf{x}_l)]+\frac{1}{2}\textbf{w}^T\textbf{w}
Lsvm=Cl=1∑m[yl⋅max(0,1−wTxl)+(1−yl)⋅(0,1+wTxl)]+21wTw
其中,
x
l
=
[
S
e
,
e
′
1
,
S
e
,
e
′
2
,
S
e
,
e
′
3
,
S
e
,
e
′
4
]
\textbf{x}_l=[S^1_{e,e'},S^2_{e,e'},S^3_{e,e'},S^4_{e,e'}]
xl=[Se,e′1,Se,e′2,Se,e′3,Se,e′4]是相似度分数组成的向量。若
(
e
,
e
′
)
∈
ψ
s
(e,e')\in\psi^s
(e,e′)∈ψs,标签
y
l
=
1
y_l=1
yl=1,否则
y
l
=
0
y_l=0
yl=0。


















 3321
3321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











