







知识图谱初步学习(二)——关系+属性+推理 学习
前言
上节内容是介绍如何构建一个简单的本体,只有类和其子类,这一节将继续构建本体,本次我们需要在之前构建的问本体基础上给类和实例加上属性,以及他们之间的关系,然后通过推理机进行推理。使用版本:protege5.5。提示:以下是本篇文章正文内容,下面案例可供参考。
零、如何导入系统自带本体?
如果不想自己创建,可以先看看这个例子。
从Web打开Pizza本体。从File菜单中选择Open from URL… 打开一个对话框,询问您是否要在当前窗口中打开本体,选择No。在下一个对话框中,在URI下输入http://protege.stanford.edu/ontologies/pizza/pizza.owl ,点击OK。
一、本体构建的步骤
- 定义实体分类。
- 定义实体分类的分类关系(即子类父类的分类树)。
- 定义槽位以及槽位取值的限制。
- 设定槽位取值的缺省值。
二、本体迭代的步骤
本体开发是一个迭代过程。共分为七步,也可以说是本体构建的七步法。
- 确定本体的领域和范围;
- 考虑重新使用现有的本体;是否可以改进和扩展现有的资源来支持目标领域和任务。如果要和其他应用程序交互,则必须重用现有本体。
- 列举本体中的重要术语;
- 定义类和类的层次结构(自上而下,自下而上,混合法) ;
- 定义类的属性-槽位;
- 定义槽位的刻面(facet,槽位取值特征);
- 创建实例。(选择-个类-类的个体实例填充槽值)。
三、添加关系
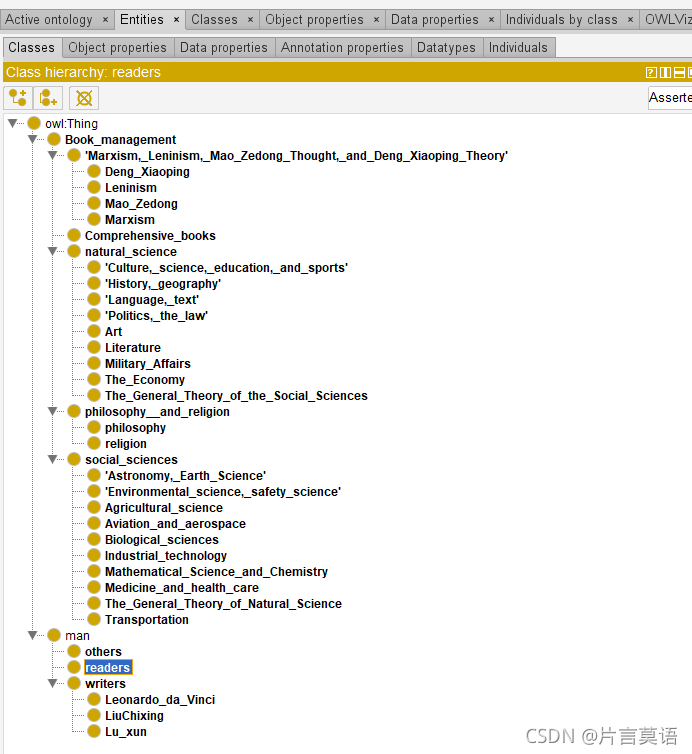
本次构建的是按照中国图书馆馆分类法来进行构建的,之后关系构建的是图书分类和人(读者,作者,其他人)的关系。

先根据上一篇定义实体的分类,确定领域和其范围。如图所示:
1.添加对象属性
命名规则:
和Thing-样,topObiectProperty是 所有属性的根节点。对属性的操作也是主要由三个button来完成。和类-样,对象属性的名字是不能重复的。同时在《官方手册》中也建议,在命名时为了方便管理,最好能够一目了然地反应对象属性所描述的关系。如果是用英文命名,建议是第一个词用小写字母,每个词之间不用空格! (因为空格可能会在编程的时候带来麻烦),从第二个词开始首字母大写(便于区分不同的词,能够更快地理解对象属性的含义) ;此外,《手册》 还建议第一个小写单词尽量用is和has,因为这是最常见的对象属性。如果是用中文命名,我感觉就是避免歧义就好了。例子:比如"isParentOf"和"isChildOf"就是一 对互逆的对象属性。互逆关系的定义是对本体关系的补充,也是推理过程的优化。
is_part_of:和构建类的步骤类似。什么是什么的一部分。点开对象属性(Object Properties),记得选中Transitive 可传递性。
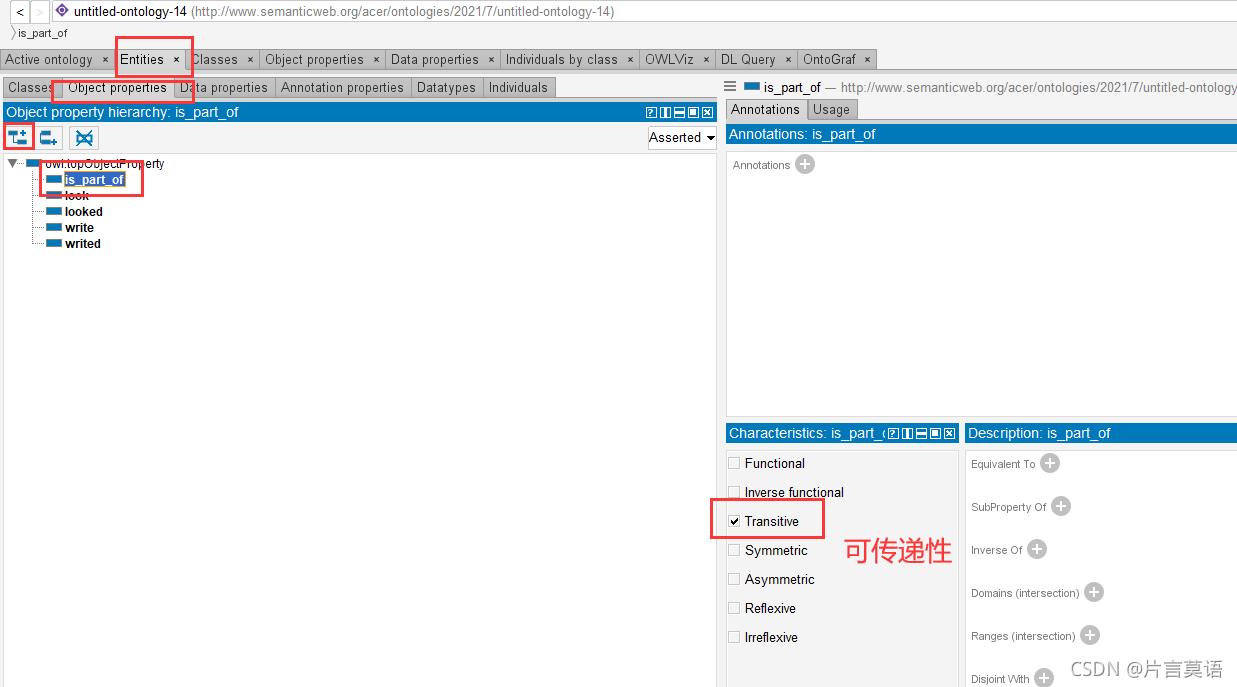
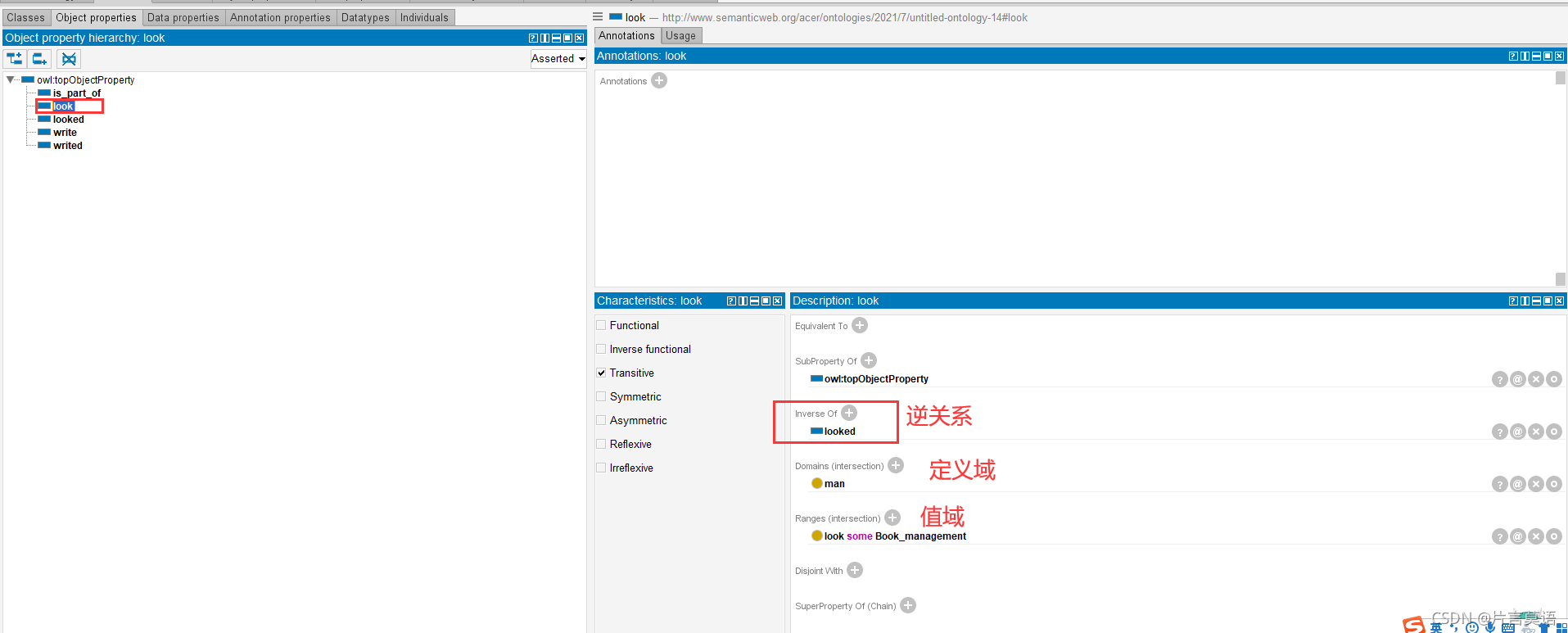
同理,建立look,人有这个属性,建立looked,同时将其标记成look逆关系,定义值域和定义域。write这个对象属性也是同样的创建。因为人看书,书被人看,作者写书,书被作者写。
附:对象属性特性的定义中英文对照:来自:Protégé基本教程【Protégé5.5.0版本】喵木木 台部落。

- Functional
如果⼀个对象属性的特性是Functional(单值的),那么对于某个实例来说,通过这个对象属性进⾏关联的实例有且仅有⼀个。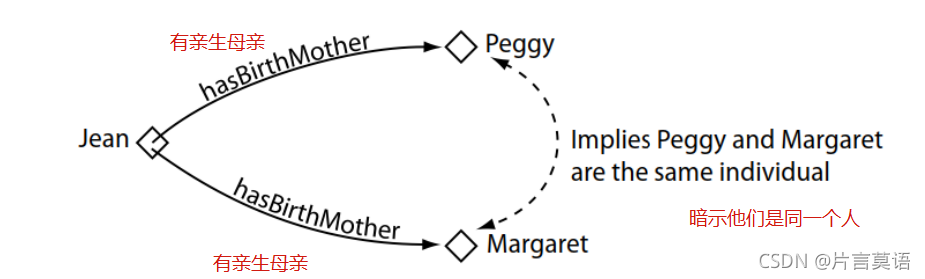
- Inverse functional
Inverse Functional特性最重要的还是体现在Functional上,它的涵义是“该对象属性的逆属性是单值属性
(single value property)”。
- Transitive
Transitive定义了对象属性的传递性。
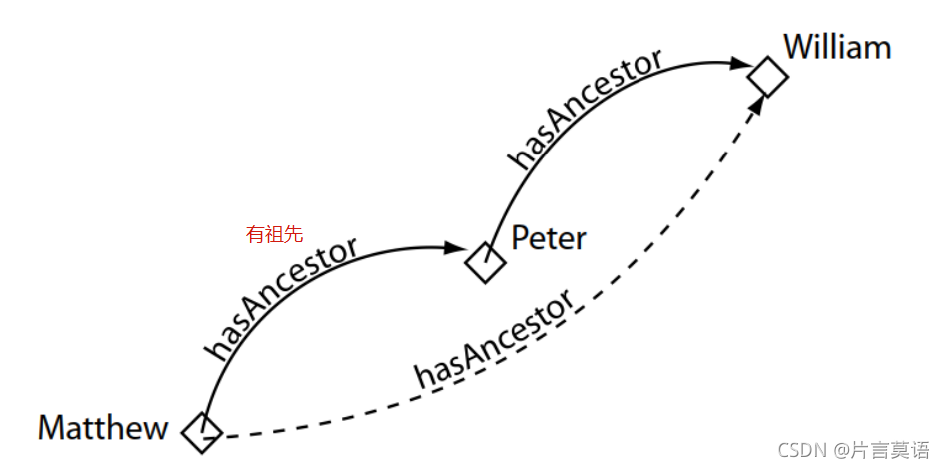
- Symmetric

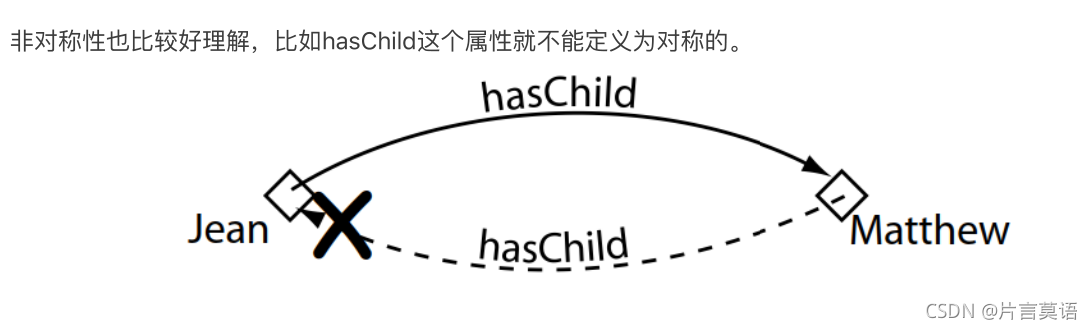
- Asymmetric
- Reflexive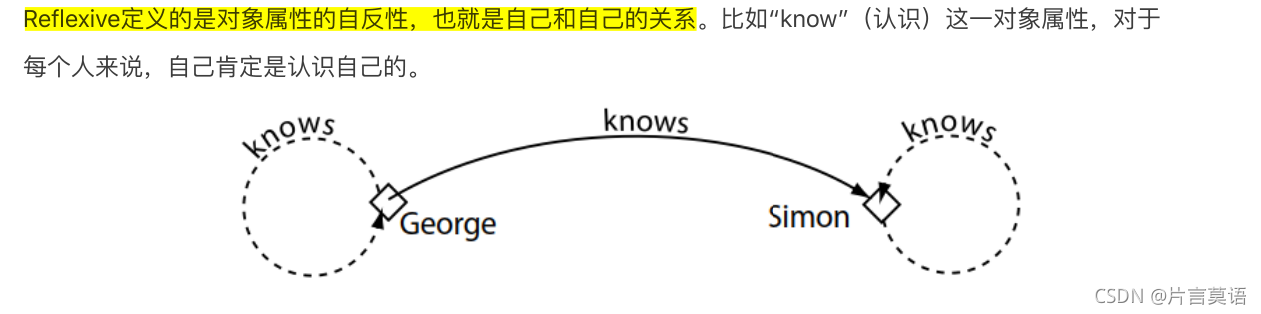
- Irreflexive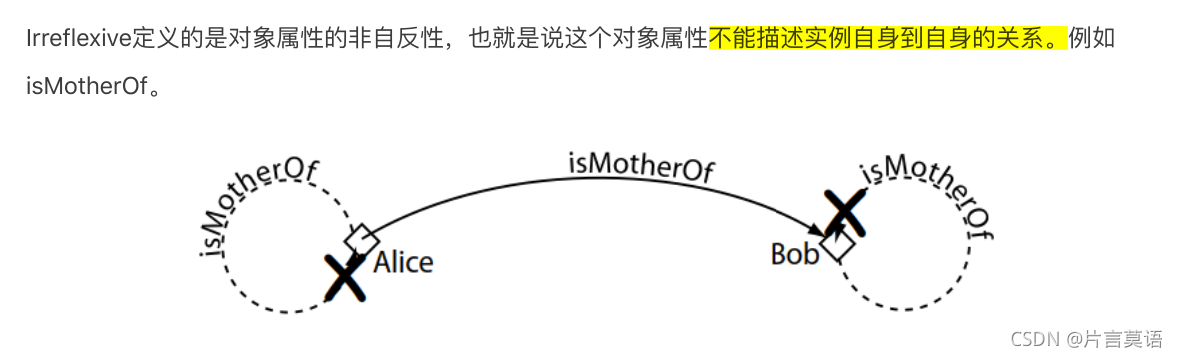
2.限制属性类
又回到Classes面板下,添加图书分类和人的关系,图书是被人看的和被人写的。这里创建的就是图书被读者读,被作者写,被动关系。步骤如下:
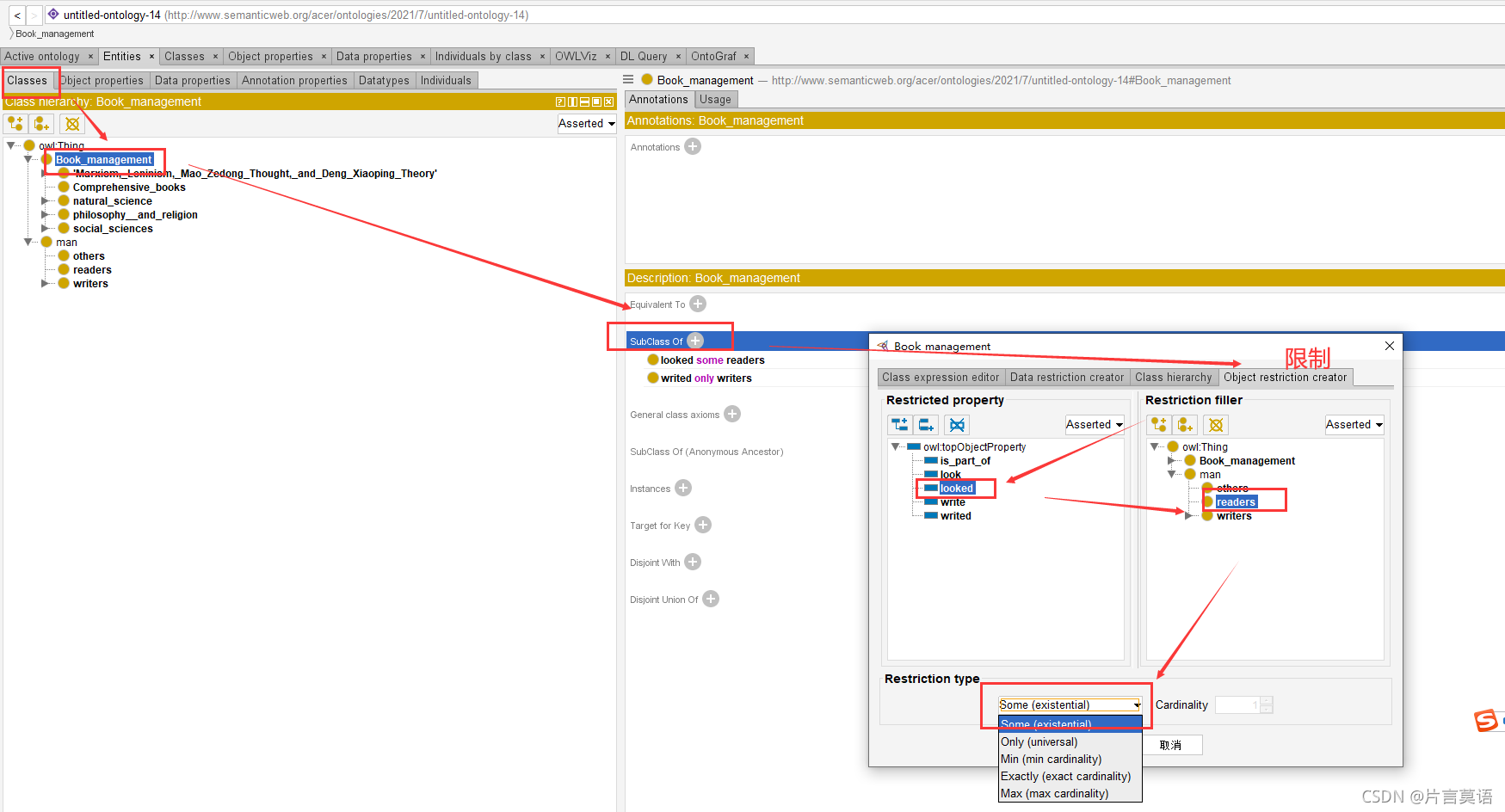
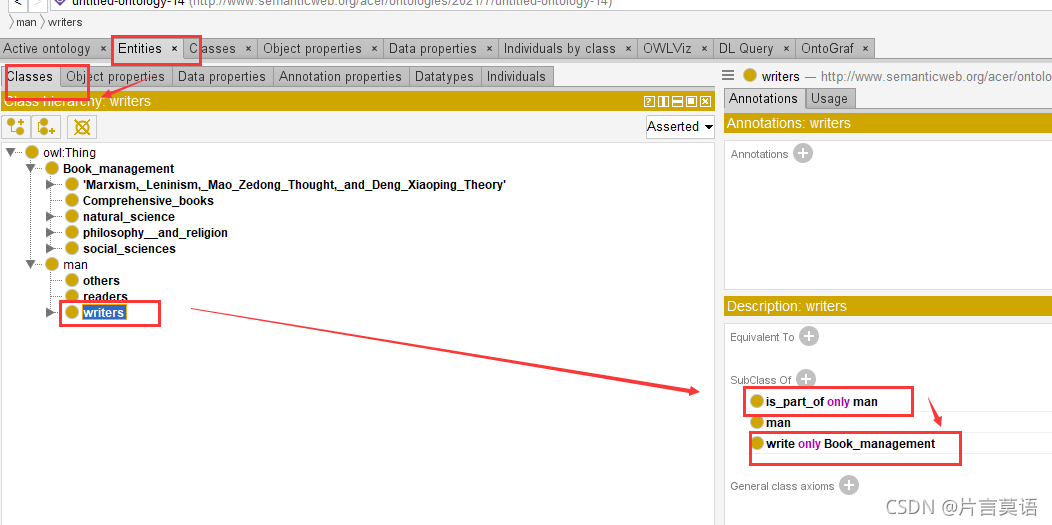
道理同上,这里就是读者读书,作者写书,是主动关系,别忘记了读者和作者都是人的一部分,所以用的only,is—part—only。
限制类型:
- Some (existential) 一些(存在)
- Only (universal) 仅(普遍基数)
- Min (mincardinality) 最小基数
- Exactly (exact cardinality)精确基数
- Max (max cardinality)最大基数
建立好各自的对象属性和属性的限制之后,就可以看到不同颜色的线条,表示他们之间的关系。
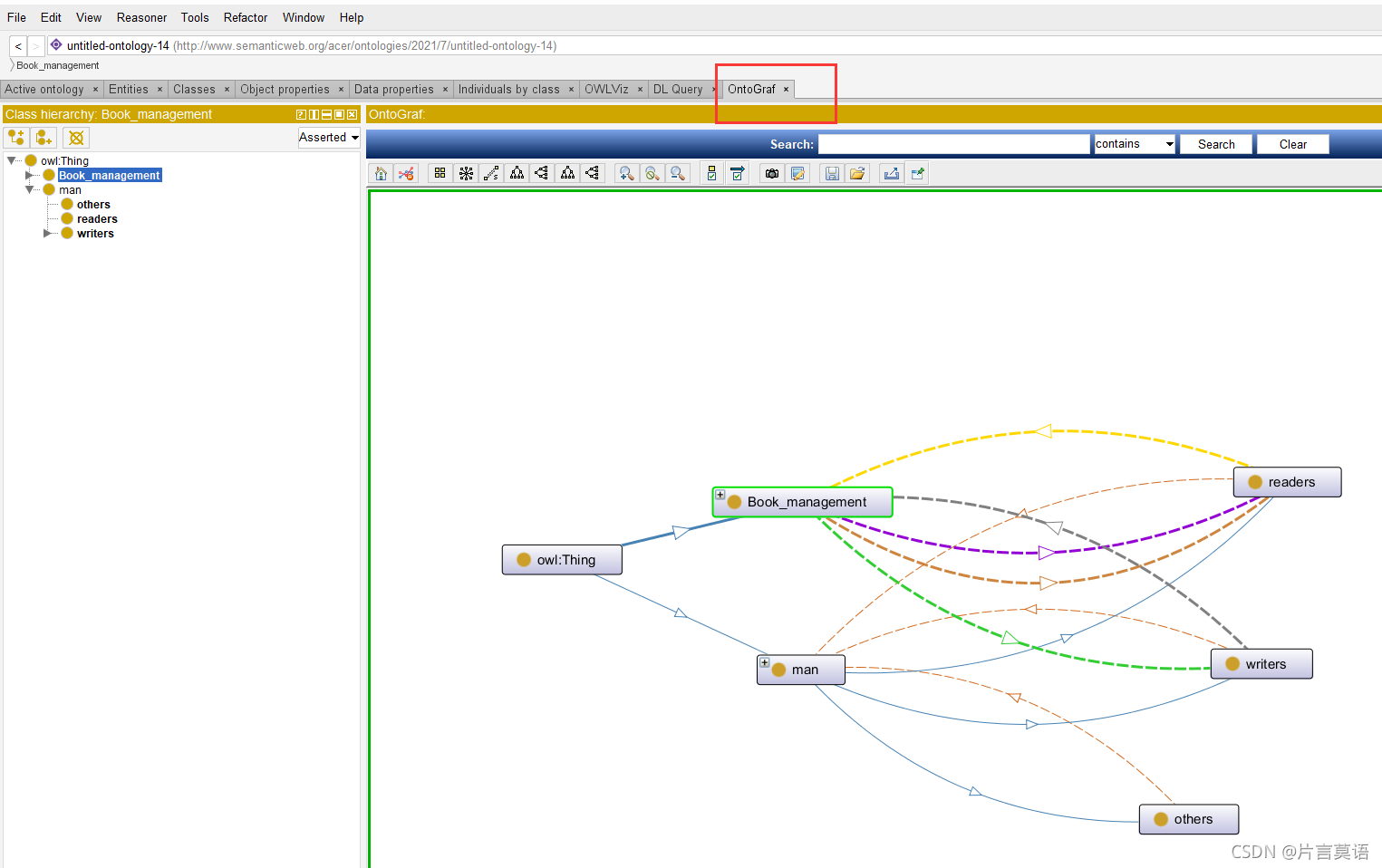
鼠标悬停即可显示他们之间的关系。
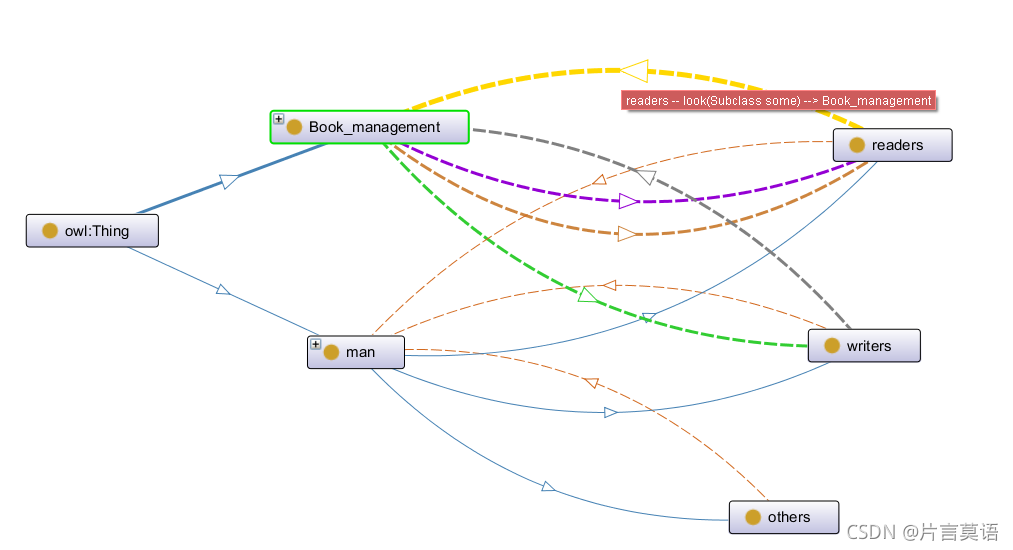
做完记得保存!!!


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











