







DeepSeek大模型高性能核心技术与多模态融合开发 - 商品搜索 - 京东
DeepSeek在文本生成、信息检索和智能问答等多个领域都展现出了令人瞩目的性能,这得益于其精心设计的初始训练过程。然而,不容忽视的是,尽管DeepSeek的架构设计能够在一定程度上减少训练成本,但要从零开始训练一个特定模型,仍然需要巨大的计算资源和庞大的数据集,这对于普通人来说无疑是一个沉重的负担。这种情况也使得一些研究人员难以复现和验证之前的研究成果,从而影响了科研的进展和可信度。
为了有效应对这一问题,研究人员提出了一种新的训练方法:在已有的大型预训练模型基础上进行进一步的训练,即所谓的“微调(fine-tuning)”。这种方法允许我们根据特定任务的需求,对原始大模型进行针对性的训练,以提升其在新任务上的表现。通过这种方式,我们不仅可以节省大量的计算资源和时间,还可以降低对海量数据集的依赖。微调的流程如图8-2所示。
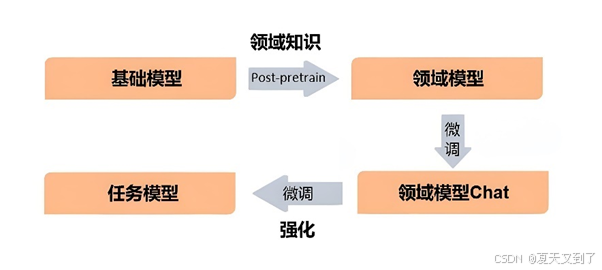
图8-2 微调流程
微调技术的引入,显著减轻了大型预训练模型的训练成本,使得更多的研究人员和开发人员能够利用这些强大的模型,而无需承担过高的计算和数据成本。这无疑为自然语言处理和人工智能领域的研究与应用开辟了新的道路,促进了技术的普及与进步。
本章我们将完成基于DeepSeek-VL2本地化的微调方法,并演示如何由关键词生成对应的文案。
8.2.1 微调的目的:让生成的结果更聚焦于任务目标
本小节将采用DeepSeek-VL2来完成广告文案生成。首先看一下我们所提供的数据和本次要求的目标,任务数据如图8-3所示。

图8-3 文本生成提供的数据集
这里我们提供了一套完整的文案数据,instruction部分是文案关键词提示,也就是相应的Prompt,而output部分是根据关键词提示生成的对应讲解文案。在进入下一步之前,我们首先看一下未经微调生成的结果,代码如下所示:
import torch
from transformers import AutoModelForCausalLM
from deepseek_vl2.models import DeepseekVLV2Processor, DeepseekVLV2ForCausalLM
from deepseek_vl2.utils.io import load_pil_images
# specify the path to the model
model_path = "deepseek-ai/deepseek-vl2-tiny"
model_path = "C:/Users/xiaohua/.cache/huggingface/hub/ models--deepseek-ai--deepseek-vl2-tiny/snapshots/66c54660eae7e90c9ba259bfdf92d07d6e3ce8aa"
vl_chat_processor = DeepseekVLV2Processor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)
model = model.to(torch.bfloat16).cuda().eval()
conversation1 = [
{"role": "<|User|>", "content": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤"}, {"role": "<|Assistant|>", "content": ""}
]
conversation = conversation1
# load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation,
images=pil_images,
force_batchify=True,
system_prompt=""
).to(model.device)
# run image encoder to get the image embeddings
inputs_embeds = model.prepare_inputs_embeds(**prepare_inputs)
# run the model to get the response
outputs = model.generate(
inputs_embeds=inputs_embeds,
input_ids=prepare_inputs.input_ids,
images=prepare_inputs.images,
images_seq_mask=prepare_inputs.images_seq_mask,
images_spatial_crop=prepare_inputs.images_spatial_crop,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs[0][len(prepare_inputs. input_ids[0]):].cpu().tolist(), skip_special_tokens=False)
print(f"{prepare_inputs['sft_format'][0]}", answer)
在这里我们首先建立了DeepSeek-VL2模型,之后将对应的文本内容输入到模型中,生成的结果如下所示:
<|User|>: 类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤
<|Assistant|>: 阔腿裤是一种非常经典且时尚的裤子类型,其设计特点包括宽松的版型、性感的风格以及大胆的图案和线条。以下是关于阔腿裤的详细描述:
1. **版型**:阔腿裤通常采用宽松的设计,使得穿着者能够自由活动,同时保持舒适感。这种版型适合各种体型,尤其是腿部较粗的人。
2. **风格**:阔腿裤通常具有一种休闲和时尚的风格,适合日常穿着。它既可以搭配休闲装,也可以搭配正式服装,展现出不同的风格。
3. **性感**:阔腿裤的线条设计通常比较修长,能够突显腿部线条,给人一种性感的感觉。这种设计风格在时尚界非常受欢迎。
4. **图案**:阔腿裤的图案设计非常多样化,可以包括几何图案、花卉图案、动物图案等。图案的多样性和设计感使得阔腿裤成为时尚界的宠儿。
5. **线条**:阔腿裤的线条设计通常比较简洁,但能够通过不同的剪裁和搭配展现出不同的视觉效果。线条的流畅性使得阔腿裤看起来更加优雅和时尚。
6. **裤型**:阔腿裤的裤型设计非常多样,包括直筒、喇叭、A字、九分等。不同的裤型设计能够满足不同的穿着需求,无论是休闲还是正式场合,阔腿裤都能胜任。
总的来说,阔腿裤是一种非常经典且时尚的裤子类型,其设计特点使得它能够适应各种场合和穿着需求。<|end▁of▁sentence|>
可以看到,虽然模型输出的结果得到了对应的答案,并且贴合我们输入的内容,但是在任务目标上可以很明显地看到,此时生成的结果并没有很好地切合任务目标,生成的结果有些松散而不符合要求。因此,为了使得模型生成在结果上更加贴合,我们可以使用微调方法对模型进行“重训练”,从而得到一个符合我们要求的输出结果模型。
8.2.2 微调经典方法LoRA详解
大模型微调LoRA(Low-Rank Adaptation,低秩自适应)是一种高效的模型调整技术,它通过引入低秩矩阵对大型预训练模型进行微调。具体而言,LoRA不直接修改模型的原始权重,而是在模型的特定层注入可训练的低秩矩阵。这些低秩矩阵与原始权重相结合,使模型能够快速适应新任务,以高效且轻量级的方式对大型语言模型进行定制化调整,从而使其更好地适应特定任务或领域的需求,同时保持模型原有的泛化能力,但又显著降低了训练所需的计算资源和时间。这种方法特别适用于资源有限或对微调效率有较高要求的场景。
LoRA方法的核心思想是将大模型的参数分解为低维的核心参数和高维的残差参数。在微调过程中,我们只更新LoRA参数,而核心参数保持不变。这种参数分解的方式降低了模型的复杂度,减少了过拟合的风险,并提高了模型的泛化能力。
此外,基于LoRA的微调方法只对大模型的特定层(如Embedding层)进行微调。这种方法不会影响大模型的整体交互能力。同时,通过冻结模型的所有参数并学习插入token,我们可以避免因调整大量参数而导致的模型不稳定问题。这种方法的效果通常比其他方法更稳定、更可靠。
另外,基于LoRA的微调方法还具有很高的灵活性和通用性。由于它只需要添加特定的参数矩阵以适应下游任务,因此可以方便地在不同场景之间进行切换。这种灵活性使得基于LoRA的方法在实际应用中具有更大的潜力。
基于LoRA的大模型微调方法是一种高效、低成本,且具有高度灵活性和通用性的解决方案。在实际应用中,我们可以根据具体场景和训练模式选择最恰当的微调方法。对于需要快速部署和高度灵活性的应用场景,基于LoRA的微调方法无疑是一个理想的选择。
具体来看,LoRA可以认为是大模型的低秩适配器,或者就简单地理解为特定任务适配器。通过在原模型特定位置上增加一个低秩分解(先降维再升维)的旁路来模拟参数的更新量。这样,使得训练时原模型固定,只训练降维矩阵A和升维矩阵B。而推理时,可将BA加到原参数上,不引入额外的推理延迟。如图8-5所示。
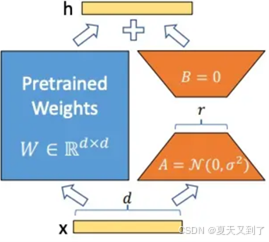
图8-5 LoRA适配器

8.2.3 适配DeepSeek微调的辅助库PEFT详解
在前面的章节中,我们已经详尽介绍了DeepSeek-VL2模型的基本使用,使读者对该模型有了初步的认识。接下来,我们将进一步探索与其紧密相关的专用微调辅助库PEFT。
PEFT(Parameter-Efficient Fine-tuning,参数高效的微调方法)作为专为DeepSeek量身打造的微调辅助库,在深度学习的广阔天地中,犹如一把锐利的宝剑,助力模型性能更上一层楼。众所周知,微调是提升模型在特定任务上表现的关键技术,然而,其高昂的数据和计算资源需求常令众多中小型研究机构和企业望而却步。正是在这样的背景下,PEFT应运而生,它以高效且低成本的微调解决方案为使命,致力于打破资源壁垒,让深度学习技术的魅力惠及更广泛的群体。
PEFT的核心竞争力在于其精妙的优化技术,这些技术能够实现对模型参数的高效、精准更新。通过融入自适应学习率调整、动态权重裁剪等创新性算法,PEFT在有限的计算资源和数据规模下,仍能驱动模型性能的显著提升。更为出色的是,它还配备了一系列实用的辅助工具,从数据预处理到模型评估,无一不体现出其便捷性和实用性,极大地减轻了开发者在微调过程中的负担。
值得大书特书的是,PEFT所具备的卓越通用性。得益于其灵活的设计和强大的功能模块,它能够轻松与各类型语言模型实现无缝对接,从而满足多样化的微调需求。这种强大的适应性,使得PEFT在各种复杂场景下都能游刃有余地发挥作用。更为难能可贵的是,它在保证模型性能的同时,还能显著降低微调过程中的计算成本,这种高效能、低成本的特性,无疑为PEFT赢得了广泛的赞誉和青睐。
在具体使用上,读者需要首先安装PEFT辅助库包,如下所示:
pip install peft下面我们提供了一个结合LoRA的DeepSeek-VL2微调范式,代码如下所示:
import torch
from transformers import AutoModelForCausalLM
from deepseek_vl2.models import DeepseekVLV2Processor, DeepseekVLV2ForCausalLM
from deepseek_vl2.models import DeepseekVLV2Processor, DeepseekVLV2ForCausalLM
from deepseek_vl2.utils.io import load_pil_images
model_path = "deepseek-ai/deepseek-vl2-tiny"
vl_chat_processor: DeepseekVLV2Processor = DeepseekVLV2Processor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
from peft import LoraConfig,TaskType,get_peft_model
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # # 模型类型需要训练的模型层的名字,主要就是attention部分的层,不同的模型对应的层的名字不同,可以传入数组,也可以字符串,也可以正则表达式。
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode = False, # False:训练模式 True:推理模式
r = 8, # LoRA 秩
lora_alpha = 32, # LoRA alaph,具体作用参见 LoRA 原理
lora_dropout = 0.1 # Dropout 比例
)
with torch.no_grad():
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)
model = model.to(torch.bfloat16).cuda()
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
在上面代码中,我们使用PEFT在模型中注入训练参数。特别之处是,我们通过选择的方式根据DeepSeek-VL2中层的名称对进行LoRA处理的目标进行选择。最终打印的训练参数如下所示:
trainable params: 38,754,816 || all params: 3,409,256,256 || trainable%: 1.1368可以看到,我们打印出待训练的参数总数,并且打印出总参数量之后,计算出待训练参数占总参数量的比重。
在上面代码中,我们看到target_modules是目标类,其定义我们将会对哪些类进行LoRA注入,我们可以通过打印模型的方式获取类的名称,即如下代码:
print(model)
结果如下:
DeepseekForCausalLM(
(model): DeepseekModel(
(embed_tokens): Embedding(102400, 5120)
(layers): ModuleList(
(0): DeepseekDecoderLayer(
(self_attn): DeepseekAttention(
(q_a_proj): Linear(in_features=5120, out_features=1536, bias=False)
(q_a_layernorm): DeepseekRMSNorm()
(q_b_proj): Linear(in_features=1536, out_features=24576, bias=False)
(kv_a_proj_with_mqa): Linear(in_features=5120, out_features=576, bias=False)
(kv_a_layernorm): DeepseekRMSNorm()
(kv_b_proj): Linear(in_features=512, out_features=32768, bias=False)
(o_proj): Linear(in_features=16384, out_features=5120, bias=False)
(rotary_emb): DeepseekYarnRotaryEmbedding()
)
(mlp): DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=12288, bias=False)
(up_proj): Linear(in_features=5120, out_features=12288, bias=False)
(down_proj): Linear(in_features=12288, out_features=5120, bias=False)
(act_fn): SiLU()
)
(input_layernorm): DeepseekRMSNorm()
(post_attention_layernorm): DeepseekRMSNorm()
)
(1-59): 59 x DeepseekDecoderLayer(
(self_attn): DeepseekAttention(
(q_a_proj): Linear(in_features=5120, out_features=1536, bias=False)
(q_a_layernorm): DeepseekRMSNorm()
(q_b_proj): Linear(in_features=1536, out_features=24576, bias=False)
(kv_a_proj_with_mqa): Linear(in_features=5120, out_features=576, bias=False)
(kv_a_layernorm): DeepseekRMSNorm()
(kv_b_proj): Linear(in_features=512, out_features=32768, bias=False)
(o_proj): Linear(in_features=16384, out_features=5120, bias=False)
(rotary_emb): DeepseekYarnRotaryEmbedding()
)
(mlp): DeepseekMoE(
(experts): ModuleList(
(0-159): 160 x DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=1536, bias=False)
(up_proj): Linear(in_features=5120, out_features=1536, bias=False)
(down_proj): Linear(in_features=1536, out_features=5120, bias=False)
(act_fn): SiLU()
)
)
(gate): MoEGate()
(shared_experts): DeepseekMLP(
(gate_proj): Linear(in_features=5120, out_features=3072, bias=False)
(up_proj): Linear(in_features=5120, out_features=3072, bias=False)
(down_proj): Linear(in_features=3072, out_features=5120, bias=False)
(act_fn): SiLU()
)
)
(input_layernorm): DeepseekRMSNorm()
(post_attention_layernorm): DeepseekRMSNorm()
)
)
(norm): DeepseekRMSNorm()
)
(lm_head): Linear(in_features=5120, out_features=102400, bias=False)
)
我们可以根据名称,选择对应的层和类名。在接下来的实战案例中,我们将使用["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]作为微调LORA注入的目标。


















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









