









CVPR-2018,Pytroch code
文章目录
1 Background and Motivation
作者发现 information propagation in state-of-the-art Mask R-CNN can be further improved
在 Mask R-CNN 基础上改进,进一步提升目标检测和实例分割的效果
2 Advantages / Contributions
提出 Path Aggregation Network(PANet) aiming at boosting information flow in proposal-based instance segmentation framework
- 1st place in the COCO 2017 Challenge Instance Segmentation task
- 2nd place in the COCO 2017 Challenge Object Detection task
- SOTA on MVD and Cityscapes
3 Method

三个改进模块
3.1 Bottom-up Path Augmentation
现有 FPN 结构的缺陷:
there is a long path from low-level structure to topmost features, increasing difficulty to access accurate localization information【图 1 (a)中红色虚箭头,前向传播时底层信息得经过整个 backbone 才能到达顶层,eg 到达 P5 层】
作者改进:
A bottom-up path is augmented to make low-layer information easier to propagate.【图 1 (a)中绿色虚箭头 】
PANet 在 FPN 基础上创建了自下而上的路径增强。用于缩短信息路径,利用 low-level 特征中存储的精确定位信号,提升特征金字塔架构。 ——目标检测算法综述之FPN优化篇
细节如下:

Bottom-up Path 搭建方式是图 2 中的逆 FPN(自顶向下) 形式
注意 N 2 N_2 N2 is simply P 2 P_2 P2, without any processing
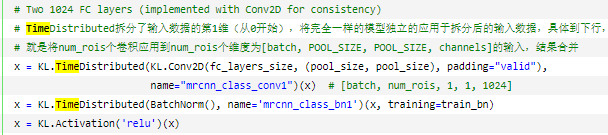
Keras 代码如下,来自 双向融合:PANet
N3 = KL.Add(name="panet_p3add")([P3, KL.Conv2D(256, (3, 3), strides=2, padding="SAME", name="panet_n2downsampled")(N2)])
N3 = KL.Conv2D(256, (3, 3), padding="SAME", name="panet_n3")(N3)
N3 = KL.Activation('relu')(N3)
3.2 Adaptive Feature Pooling
缺陷:
熟悉 FPN 的小伙伴应该知道,proposals are assigned to different feature levels according to the size of proposals(不同尺度的ROI,使用不同特征层作为ROI pooling 层的输入),像 “八爪鱼”,多条“腿”,一个 head,
two pro-posals with 10-pixel difference can be assigned to different levels,具体映射关系可以参考 Mask RCNN without Mask

information discarded in other levels may be helpful for final prediction
作者改进(每条腿上都接个头):

We use max operation to fuse features from different levels
聚合每个特征层次上的每个候选区域 ——目标检测算法综述之FPN优化篇
把同一 proposal 所有 level 的信息融合起来,而不是根据 proposal 的大小来决定采用 FPN 哪层 level 的特征
下面这个图就可以很直观的感受到利用多 level feature 的必要

横坐标是原 FPN 的 level,折线是采用 Adaptive Feature Pooling 之后的 level
以蓝色的 level1 折线为例,采用 Adaptive Feature Pooling 之后发现,属于 level1 范围大小的 proposal 仅用了 ~30% 的 level 1 特征,其余特征为 ~30% level 2, ~20% level3, ~20% level4(原 FPN 属于 level1 范围大小的 proposal 采用 100% level 1 特征)
可以看到 Adaptive Feature Pooling 使每个 proposal 的特征更加完整与丰富!
Keras 代码如下,来自 双向融合:PANet
class AdaptiveFeaturePooling(KE.Layer):
def __init__(self, **kwargs):
super(AdaptiveFeaturePooling, self).__init__(**kwargs)
def call(self, inputs):
x2, x3, x4, x5 = inputs
x = tf.maximum(tf.maximum(x2, x3), tf.maximum(x4, x5))
# x = tf.add_n([x2, x3, x4, x5])
return x
def conpute_output_shpae(self, input_shape):
return input_shape[0]
x2 = ROIAlign([pool_size, pool_size], name="bbox_roi_align_n2")([rois, feature_maps[0]])
x2 = KL.TimeDistributed(KL.Conv2D(1024, (pool_size, pool_size), padding="valid"),name="mrcnn_class_conv1_n2")(x2)
x2 = KL.TimeDistributed(BatchNorm(), name='mrcnn_class_bn1_n2')(x2, training=train_bn)
x2 = KL.Activation('relu')(x2)
...
x = AdaptiveFeaturePooling(name="bbox_adaptive_feature_pooling")([x2, x3, x4, x5])
3.3 Fully-connected Fusion
缺陷:
Mask R-CNN 方法中,mask prediction is made on a single view(卷积),losing the chance to gather more diverse information
作者的改进:

A complementary branch capturing different views——引入了平行的 FC 分支,最后与 conv 分支融合来预测 mask
作者认为 FC 的优势在于
-
FC layers are location sensitive since predictions at different spatial locations are achieved by varying sets of parameters. So they have the ability to adapt to different spatial locations.
-
Also prediction at each spatial location is made with global information of the entire proposal.
Keras 代码如下,来自 双向融合:PANet
conv 分支
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"), name="mrcnn_mask_conv1")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_mask_bn1')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"), name="mrcnn_mask_conv2")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_mask_bn2')(x, training=train_bn)
x = KL.Activation('relu')(x)
x = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"), name="mrcnn_mask_conv3")(x)
x = KL.TimeDistributed(BatchNorm(), name='mrcnn_mask_bn3')(x, training=train_bn)
x = KL.Activation('relu')(x)
x_fcn = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"), name="mrcnn_mask_conv4")(x)
x_fcn = KL.TimeDistributed(BatchNorm(), name='mrcnn_mask_bn4')(x_fcn, training=train_bn)
x_fcn = KL.Activation('relu')(x_fcn)
x_fcn = KL.TimeDistributed(KL.Conv2DTranspose(256, (2, 2), strides=2, activation="relu"), name="mrcnn_mask_deconv")(x_fcn)
x_fcn = KL.TimeDistributed(KL.Conv2D(num_classes, (1, 1), strides=1), ame="mrcnn_mask")(x_fcn)
FC 分支
x_fc = KL.TimeDistributed(KL.Conv2D(256, (3, 3), padding="same"), name="mrcnn_mask_conv4_fc")(x)
x_fc = KL.Activation('relu')(x_fc)
x_fc = KL.TimeDistributed(KL.Conv2D(128, (3, 3), padding="same"), name="mrcnn_mask_conv5_fc")(x_fc)
x_fc = KL.Activation('relu')(x_fc) # b, num_rois, h, w, c
t_shape = x_fc.shape
x_fc = KL.Reshape([t_shape[1].value, t_shape[2].value * t_shape[3].value * t_shape[4].value])(x_fc) # b, num_rois, h*w*c
x_fc = KL.TimeDistributed(KL.Dense(mask_shape[0] * mask_shape[1]), name="mrcnn_mask_fc")(x_fc) # b, num_rois, mask_size * mask_size
x_fc = KL.Reshape([t_shape[1].value, mask_shape[0], mask_shape[1], 1])(x_fc) # b, num_rois, mask_size, mask_size, 1
conv 分支和 FC 分支融合在一起
x = KL.Add()([x_fc, x_fcn]) # (b, num_rois, mask_size, mask_size, 1) + (b, num_rois, mask_size, mask_size, num_class)
x = KL.TimeDistributed(KL.Activation('sigmoid'))(x)
4 Experiments
4.1 Datasets
- COCO
- Cityscapes
- MVD
4.2 Experiments on COCO
1)Instance Segmentation Results

2)Object Detection Results

3)Component Ablation Studies

A
P
AP
AP 是分割任务的结果,
A
P
b
b
AP^{bb}
APbb 是单独训练目标检测的结果,
A
P
b
b
M
AP^{bbM}
APbbM 是联合训练目标检测和分割的结果
tricks 的效果提升占了 50%
Half of the improvement is from multi-scale training and multi-GPU sync. BN
4)Ablation Studies on Adaptive Feature Pooling

5)Ablation Studies on Fully-connected Fusion

6)COCO 2017 Challenge
引入更多的 trick

1st,DCN 是 Deformable convolutional networks

2nd
4.3 Experiments on Cityscapes


4.4 Experiments on MVD


















 1785
1785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









