







PnPNet: End-to-End Perception and Prediction with Tracking in the Loop

1.为什么要做这个研究(理论走向和目前缺陷) ?
之前的工作,perception,tracking和prediction(motion forecasting)这三个模块,不管是each component is developed separately(效率低),还是solve the detection and prediction tasks jointly with a
single neural network(提高了计算效率,但由于prediction时不包括tracking,所以只包含短暂的历史信息),都有各自的缺点。 
2.他们怎么做这个研究 (方法,尤其是与之前不同之处) ?
从大的框架来说,是End-to-end perception & prediction, tracking in the loop。
另外两个主要的贡献:1. 首先,我们提出了一种新的目标轨迹表示,定义在一个目标检测序列上,以充分捕捉行动者的时间特征。2. 其次,我们提出了一种多目标跟踪器。
3.发现了什么(总结结果,补充和理论的关系)?
PnPNet与各个独立模块的算法如detection等和几个模块联合起来的算法相比,精度都有提升,效果还是不错的。
作者说他未来的工作想把更多的下游模块加入到网络中,如multiagent behavior prediction和motion planning。
4.引言。
与1相同。
5.相关研究。
首先讲了现在研究者对三个模块分别所做的研究。
**3D Object Detection:**还是说现在有基于image,基于lidar,和两者fusion这三大类方法。我们的PnPNet 使用了 bird’s eye view representation of LiDAR 和 HD maps 并且 performs single shot detection。
Multi-Object Tracking:
Motion Forecasting: DESIRE、Social-LSTM、Social-GAN。我们的PnPNet中的预测模块直接重用丰富场景上下文的感知特征,并且还从过去的对象轨迹中显式提取对象状态。
Joint Models for Perception and Prediction: FAF、IntentNet、SpAGNN、NeuralMP,这些方法都各自有加入一些新的想法,并且共享用于检测和预测的传感器特征,但他们由于没有在预测前加入跟踪,所以丢失了目标在时间维度的大部分信息。我们的PnPNet addresses this by incorporating online tracking and extracting trajectory-level actor representation to encode long-term history, which in turn improves all tasks.
6、End-to-End Perception and Prediction.

6.1.Object Detection Module
Input: multi-sweep LiDAR point clouds (up to 0.5 second) and an HD map
Output: object detections in bird’s eye view (BEV)
apply a 2D convolutional neural network (CNN) based backbone with multi-scale feature fusion to create our intermediate feature representation:

Xt is our input composed of multiple LiDAR sweeps (up to frame t) and the HD map.
Following the singlestage detector 48 we then use a convolutional detection header to output dense detections.


6.2.Discrete-Continuous Tracking Module
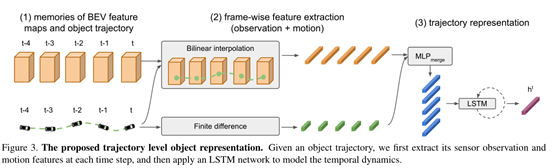
6.2.1 Trajectory level object representation:
For the task at hand,these features should contain both the object’s observation as well as information about its motion.(分别对应上图中的两条输入)

We then combine the two features into a single feature representation.
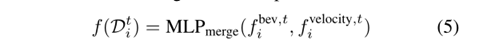
they are fed to an LSTM network to produce the trajectory level representation
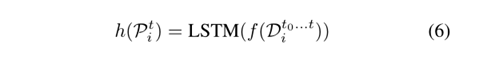
6.2.2 Data association:
下面公式第二行中可以add一些new candidates.


6.2.3 Trajectory estimation:
这一步对之前的结果起一个refine作用

6.3 Motion Forecasting Module
将经过上一步tracking后的结果传到predict模块
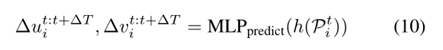
7、损失函数
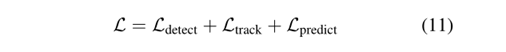
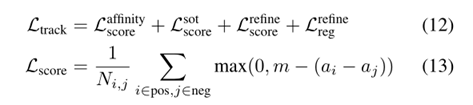















 2044
2044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









