






回顾一下三种参数高效微调方法-Prefix Tuning、Adapter Tuning、LoRA
Prefix Tuning

在prefix-tuning之前的工作主要是人工设计离散的template或者自动化搜索离散template,问题在于最终的性能对人工设计的template的特别敏感:加一个词或者少一个词,或者变动位置,都会造成很大的变化,所以这种离散化的token的搜索出来的结果可能并不是最优的。Prefix Tuning方法使用连续的virtual token embedding来代替离散的token,且与Full-finetuning更新所有参数的方式不同。简而言之就是Prefix Tuning在原始文本进行词嵌入之后,在前面拼接上一个前缀矩阵,或者将前缀矩阵拼在模型每一层的输入前。

Prefix Tuning的两种示例
Prefix Tuning相关设置:
-
前缀初始化时,[前缀长度, 嵌入维度],其中嵌入维度与模型词嵌入的维度相同。前缀长度可以根据任务需求进行调整。
-
更长的前缀意味着更多的可微调参数,效果也变好,不过长度还是有阈值限制的(table-to-text是10,summarization是200)
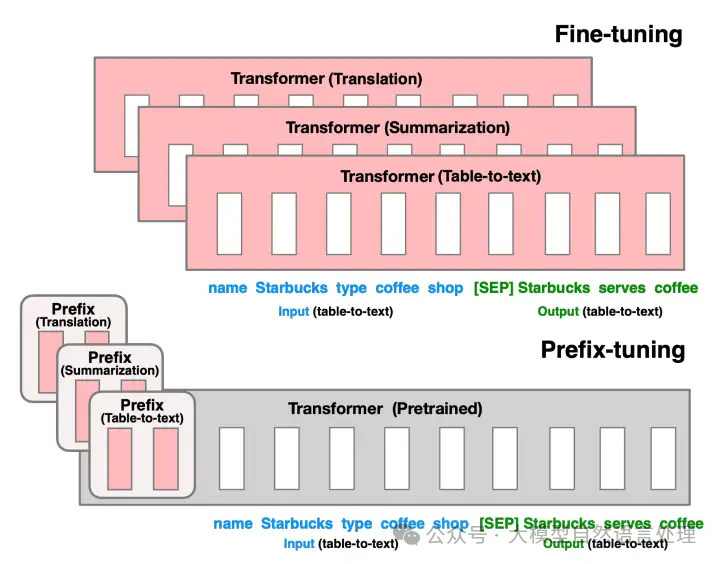
(上):针对表格描述(Table-to-text)、文章总结(Summarization)、翻译(Translation)三种任务,Fine-Tuning需微调三个LM,且需保存每个特定任务的LM参数,臃肿和低效;(下):然而,Prefix Tuning要清爽得多,针对三类任务,只需训练三个Prefix生成器,原LM参数可直接复用。
推理阶段,只需要将任务相关的输入序列与训练好的前缀嵌入进行拼接,然后输入到模型中即可得到预测结果。
代码过程,下面这个类旨在将输入的前缀有效地编码为适合后续处理的向量形式。
import torch
class PrefixEncoder(torch.nn.Module):
r'''
The torch.nn model to encode the prefix
Input shape: (batch-size, prefix-length)
Output shape: (batch-size, prefix-length, 2*layers*hidden)
'''
def __init__(self, config):
super().__init__()
self.prefix_projection = config.prefix_projection
if self.prefix_projection:
# Use a two-layer MLP to encode the prefix
self.embedding = torch.nn.Embedding(config.pre_seq_len, config.hidden_size)
self.trans = torch.nn.Sequential(
torch.nn.Linear(config.hidden_size, config.prefix_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(config.prefix_hidden_size, config.num_hidden_layers * 2 * config.hidden_size)
)
else:
self.embedding = torch.nn.Embedding(config.pre_seq_len, config.num_hidden_layers * 2 * config.hidden_size)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.trans(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values
Adapter Tuning
通过引入少量可训练参数(适配器模块)来进行特定任务的优化。适配器模块是一组轻量级的参数,被添加到模型的中间层,以保护原有预训练模型的参数。这种方法的目标是在不改变整体模型结构的情况下,通过调整适配器模块的参数来适应新任务。

Adapter Tuning针对Transformer的添加方式。左:针对每个Transformer层,Adapter参数在两个残差前插入。在Tuning中,图中的绿色模块是可训练的,其他模块的参数固定。
Adapter Tuning的核心思想是在预训练模型的中间层中插入小的可训练层或“适配器”。这些适配器通常包括一些全连接层、非线性激活函数等,它们被设计用来捕获特定任务的知识,而不需要对整个预训练模型进行大规模的微调。
下面举个例子看下Adapter Tuning过程:
Adapters还可以和HuggingFace的Transformer包无缝整合,可以直接加载HuggingFace上的模型进行Adapter微调。
以文本分类为例,BERT预训练模型加载:
from transformers import AutoTokenizer, AutoConfig
from adapters import AutoAdapterModel
model_path = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_path)
config = AutoConfig.from_pretrained(model_path, num_labels=3)
model = AutoAdapterModel.from_pretrained(model_path, config=config)

然后为预训练模型设置适配器。这里需要注意,在Adapters包里,本节所介绍的适配器结构被称为瓶颈适配器(Bottleneck adapters)(如上图1),使用BnConfig类来配置。这里需要为适配器取一个名字,之后可以通过这个名字来激活或者禁用这个适配器。
from adapters import BnConfig
adapter_name = "trouble_shooting"
# 添加一个新的adapter,类型为Bn adapter,即bottleneck adapter
config = BnConfig(mh_adapter=True, output_adapter=True, reduction_factor=16, non_linearity="relu")
model.add_adapter(adapter_name, config=config)
# 添加一个分类头
model.add_classification_head(adapter_name,num_labels=3, activation_function="relu")
# 激活这个adapter
model.train_adapter(adapter_name)
主要参数:
-
mh_adapter:设置是否要在多头注意力模块之后添加适配器。
-
output_adapter:设置是否要在Transformer模块的输出层添加适配器。
-
reduction_factor:模型参数量与需调整的适配器参数量的比值。
-
non_linearity:设置非线性部分使用的激活函数。
trainer训练模型:
from transformers import TrainingArguments
from adapters import AdapterTrainer
training_args = TrainingArguments(
num_train_epochs=5,
per_device_train_batch_size = 16,
logging_steps=2,
save_steps = 10,
gradient_accumulation_steps = 4,
output_dir="bert-adapter",
)
trainer = AdapterTrainer (
model=model, tokenizer=tokenizer
args=training_args, train_dataset=train_dataset,
optimizers=(optimizer, None)
)
trainer.train() # 开始训练
trainer.save_model() # 保存训练好的模型
LoRA
矩阵的秩(Rank):衡量了矩阵中行或列向量的线性无关性。
低秩:秩远小于矩阵的行数或列数。
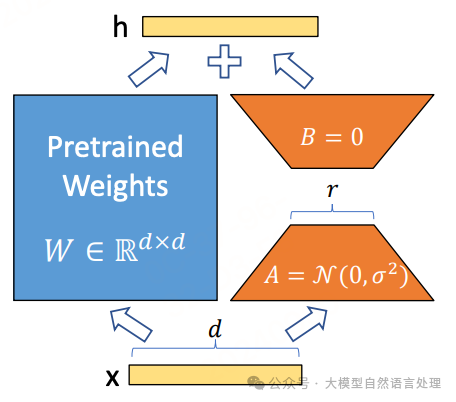 LoRA(Low-Rank Adaptation)假设模型在任务适配过程中权重的改变量可以是低秩的。 LoRA通过在预训练模型中引入一个额外的线性层(由低秩矩阵A和B组成),并使用特定任务的训练数据来微调这个线性层,从而实现对模型的高效微调。
LoRA(Low-Rank Adaptation)假设模型在任务适配过程中权重的改变量可以是低秩的。 LoRA通过在预训练模型中引入一个额外的线性层(由低秩矩阵A和B组成),并使用特定任务的训练数据来微调这个线性层,从而实现对模型的高效微调。
假设预训练参数为,那么全量微调时的更新量自然也 是一个矩阵,LoRA将更新量约束为低秩矩阵来降低训练时的参数量,即设,其中以及,用新的替换模型原参数,并固定不变,只训练,如下图所示:

为了使得LoRA的初始状态跟预训练模型一致,通常会将A,B之一全零初始化,这样可以得到A_0B_0=0,那么初始的W就是W_0。但这并不是必须的,如果A,B都是非全零初始化,那么我们只需要将W设置为

也就是说将固定不变的权重从W_0换为W_0—A_0B_0,同样可以满足初始W等于W_0这一条件。
影响LoRA微调的相关参数如下:
-
秩(Rank)
参数:lora_rank
描述:秩是LoRA中最重要的参数之一,它决定了低秩矩阵的维度。秩的大小直接影响模型的性能和训练时间。
常用值:对于小型数据集或简单任务,秩可以设置为1或2;对于更复杂的任务,秩可能需要设置为4、8或更高。
-
缩放系数(Alpha)
参数:lora_alpha
描述:缩放系数用于在训练开始时对低秩矩阵的更新进行缩放,以确保训练过程的稳定性。
常用值:缩放系数的具体值取决于秩的大小和任务的复杂度。
-
Dropout系数
参数:lora_dropout
描述:Dropout是一种正则化技术,用于防止模型过拟合。在LoRA Fine-tuning中,Dropout系数决定了在训练过程中随机丢弃低秩矩阵中元素的概率。
常用值:Dropout系数的常用值范围在0到1之间,具体值取决于模型的复杂度和数据的规模。
-
学习率
参数:learning_rate
描述:学习率决定了模型在训练过程中权重更新的步长。适当的学习率可以帮助模型在训练过程中更快地收敛到最优解。
常用值:学习率的具体值取决于多个因素,包括模型的复杂度、数据的规模以及训练过程中的其他超参数设置。
LoRA微调如今是高效微调LLM的重要手段,PEFT库也集成了相关方法: PEFT库:https://github.com/huggingface/peft
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 3903
3903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









