









同步于Buracag的博客;音尘杂记
在微积分1中已经附上了一个常见函数形式的导数,下文主要是关于向量函数及其导数,以及在机器学习和神经网络中常见的Logistic函数、Softmax函数的导数形式。
1. 向量函数及其导数
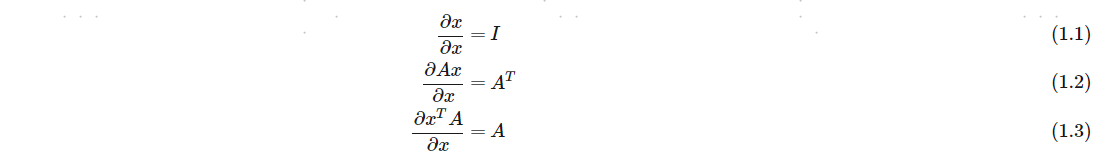
2. 按位计算的向量函数及其导数
假设一个函数
f
(
x
)
f(x)
f(x)的输入是标量
x
x
x。对于一组
K
K
K个标量
x
1
,
.
.
.
,
x
K
x_1, ... , x_K
x1,...,xK,我们可以通过
f
(
x
)
f(x)
f(x)得到另外一组
K
K
K个标量
z
1
,
.
.
.
,
z
K
z_1, ... , z_K
z1,...,zK,
(1.4)
z
k
=
f
(
x
k
)
,
∀
k
=
1
,
.
.
.
,
K
z_k = f(x_k), ∀k = 1, ... ,K \tag{1.4}
zk=f(xk),∀k=1,...,K(1.4)
为了简便起见,我们定义
x
=
[
x
1
,
.
.
.
,
x
K
]
T
,
z
=
[
z
1
,
.
.
.
,
z
K
]
T
x = [x_1, ... , x_K]^T,z = [z_1, ... , z_K]^T
x=[x1,...,xK]T,z=[z1,...,zK]T,
(1.5)
z
=
f
(
x
)
z = f(x) \tag{1.5}
z=f(x)(1.5)
其中
f
(
x
)
f(x)
f(x)是按位运算的,即
[
f
(
x
)
]
i
=
f
(
x
i
)
[f(x)]_i = f(x_i)
[f(x)]i=f(xi)。
当
x
x
x为标量时,
f
(
x
)
f(x)
f(x)的导数记为
f
′
(
x
)
f′(x)
f′(x)。当输入为
K
K
K维向量
x
=
[
x
1
,
.
.
.
,
x
K
]
T
x = [x_1, ... , x_K]^T
x=[x1,...,xK]T时,其导数为一个对角矩阵。
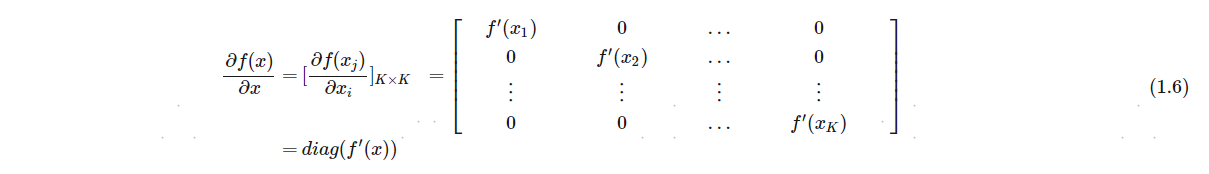
3. Logistic函数的导数
关于logistic函数其实在博文’Logistic loss函数’中已经有所介绍,接下来要说是更广义的logistic函数的定义:
(1.7)
l
o
g
i
s
t
i
c
(
x
)
=
L
1
+
e
x
p
(
−
k
(
x
−
x
0
)
)
logistic(x) = \frac{L}{1 + exp(−k(x − x_0))} \tag{1.7}
logistic(x)=1+exp(−k(x−x0))L(1.7)
其中,
x
0
x_0
x0是中心点,
L
L
L是最大值,
k
k
k是曲线的倾斜度。下图给出了几种不同参数的Logistic函数曲线。当
x
x
x趋向于
−
∞
−\infty
−∞时,logistic(x)接近于0;当
x
x
x趋向于
+
∞
+\infty
+∞时,logistic(x) 接近于
L
L
L。

当参数为(
k
=
1
,
x
0
=
0
,
L
=
1
k = 1, x_0 = 0, L = 1
k=1,x0=0,L=1) 时,Logistic 函数称为标准Logistic 函数,记为f(x)。
(1.8)
f
(
x
)
=
1
1
+
e
x
p
(
−
x
)
f(x) = \frac{1}{1 + exp(−x)} \tag{1.8}
f(x)=1+exp(−x)1(1.8)
标准logistic函数有两个重要的性质如下:

当输入为
K
K
K维向量
x
=
[
x
1
,
.
.
.
,
x
K
]
T
x=[x_1, ..., x_K]^T
x=[x1,...,xK]T时,其导数为:
(1.11)
f
′
(
x
)
=
d
i
a
g
(
f
(
x
)
⊙
(
1
−
f
(
x
)
)
)
f'(x) = diag(f(x) \odot (1 − f(x))) \tag{1.11}
f′(x)=diag(f(x)⊙(1−f(x)))(1.11)
4. Softmax函数的导数
Softmax函数是将多个标量映射为一个概率分布。对于
K
K
K个标量
x
1
,
.
.
.
,
x
K
x_1, ... , x_K
x1,...,xK,softmax 函数定义为
(1.12)
z
k
=
s
o
f
t
m
a
x
(
x
k
)
=
e
x
p
(
x
k
)
∑
i
=
1
K
e
x
p
(
x
i
)
z_k = softmax(x_k) = \frac{exp(x_k)}{\sum_{i=1}^{K}exp(x_i)} \tag{1.12}
zk=softmax(xk)=∑i=1Kexp(xi)exp(xk)(1.12)
这样,我们可以将
K
K
K个变量
x
1
,
.
.
.
,
x
K
x_1, ... , x_K
x1,...,xK转换为一个分布:
z
1
,
.
.
.
,
z
K
z_1, ... , z_K
z1,...,zK,满足
(1.13)
z
k
∈
[
0
,
1
]
,
∀
k
,
∑
k
=
1
K
z
k
=
1
z_k \in [0, 1], ∀k, \quad \sum_{k=1}^{K}z_k = 1 \tag{1.13}
zk∈[0,1],∀k,k=1∑Kzk=1(1.13)
当Softmax函数的输入为
K
K
K维向量
x
x
x时,

其中
1
K
=
[
1
,
.
.
.
,
1
]
K
×
1
1_K = [1, ... , 1]_{K×1}
1K=[1,...,1]K×1是
K
K
K维的全1向量。
Softmax函数的导数为

其中式(1.16)请参考 ‘微积分1-导数’ 式(1.13)。
主要参考https://github.com/nndl/nndl.github.io















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









