



2025深度学习发论文&模型涨点之——聚类+transformer
聚类和Transformer的结合在多个领域取得了显著的研究进展和应用成果,以下是一些具体的应用和方法:
-
增强特征表示和模型性能:聚类算法能够将数据分组,找出数据中的结构,而Transformer模型具有强大的特征提取能力,二者结合可以进一步提升模型对数据特征的捕捉和表示能力,从而提高模型在各种任务中的性能。
-
优化计算效率:聚类可以对数据进行降维或分组,减少需要处理的数据量,进而降低Transformer模型的计算复杂度,提高模型的运行效率。例如,PaCa-ViT通过将注意力机制从Patch-to-Patch转变为Patch-to-Cluster,将二次复杂度降低为线性复杂度。
- 提高模型的可解释性:聚类过程相对直观,能够为模型的决策提供更清晰的解释。例如,PaCa模块允许通过热图直观地可视化学到的聚类分配,为解释模型提供了一种直接的前向解释器。
小编整理了一些遥感+多模态【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学扫码添加我
回复“聚类+transformer”即可全部领取

论文精选
论文1:
Fast Transformers with Clustered Attention
具有聚类注意力的快速 Transformer
方法
-
聚类注意力:通过将查询聚类到聚类中心,减少了注意力矩阵的计算复杂度。
快速聚类方法:使用局部敏感哈希(LSH)和 K-Means 进行快速聚类。
注意力矩阵近似:通过聚类后的中心点计算注意力矩阵,减少计算量。
顶部-K 关键点选择:识别每个聚类中具有最高注意力的关键点,进一步优化注意力计算。
创新点
-
聚类注意力:将查询聚类到中心点,减少计算复杂度,同时保持注意力分布的准确性。
顶部-K 关键点:通过选择每个聚类中最重要的关键点,进一步减少计算量,同时保持性能。
线性复杂度:对于固定数量的聚类,复杂度与序列长度呈线性关系,显著降低计算成本。
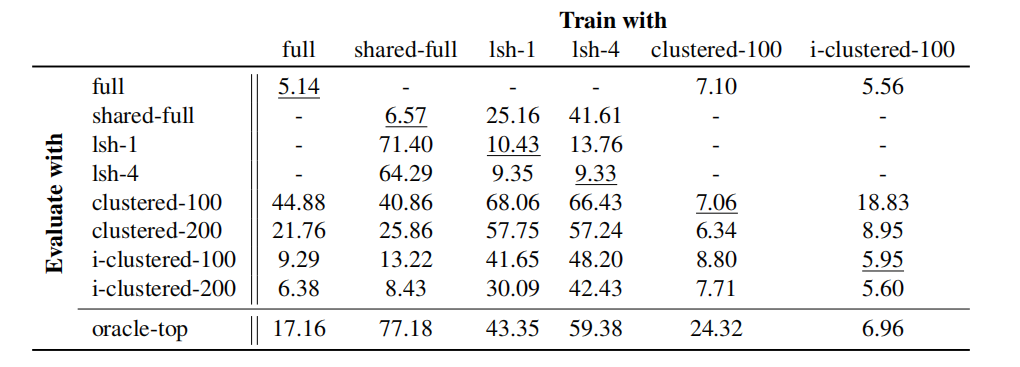
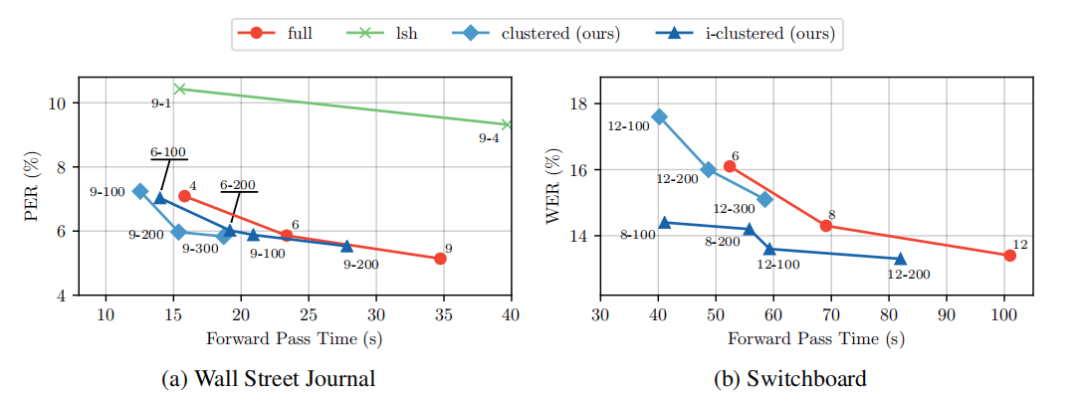
性能提升:在自动语音识别任务上,聚类注意力模型在给定计算预算下优于标准 Transformer 模型,例如在 Wall Street Journal 数据集上,i-clustered 模型在 4 层时的 PER 为 5.14%,而标准 Transformer 在 6 层时的 PER 为 5.56%。
论文2:
TCFormer Visual Recognition via Token Clustering Transformer
基于 Token 聚类 Transformer 的视觉识别
方法
-
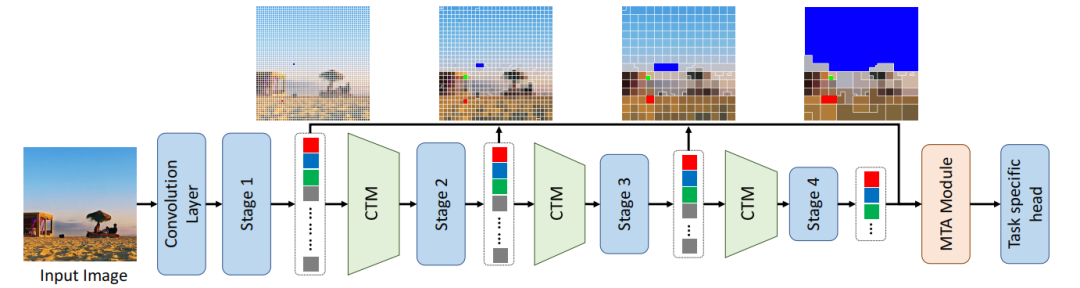
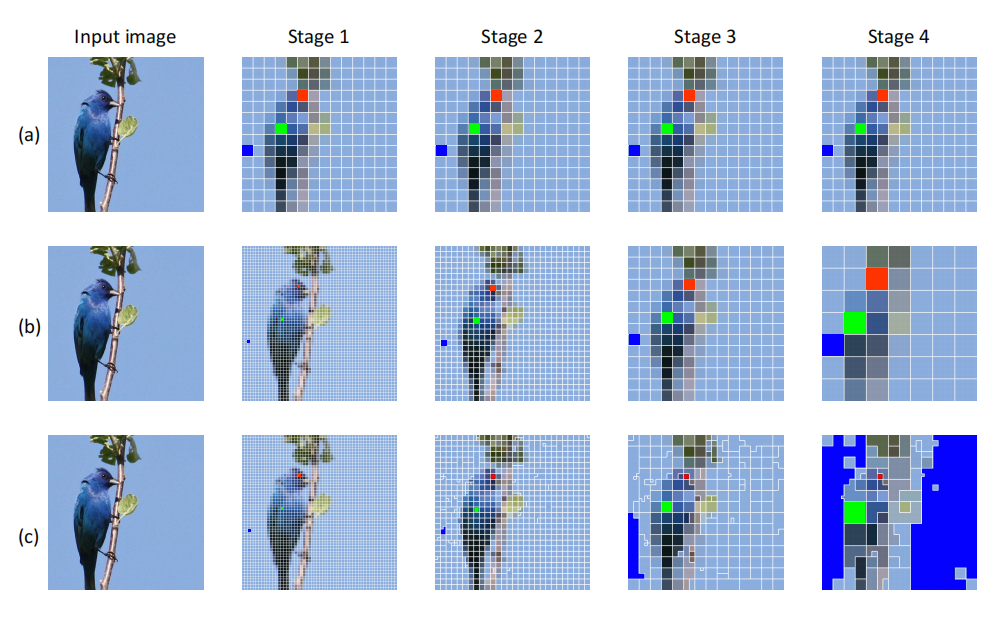
动态视觉 Token 生成:通过聚类生成动态视觉 Token,表示具有相似语义的图像区域。
多尺度特征聚合:通过多阶段 Token 聚类和聚合模块,融合多尺度特征。
聚类引导的注意力机制:在注意力过程中引入聚类结果,提高模型对重要区域的关注。
本地和全局聚类:在早期阶段使用本地聚类,在后期阶段使用全局聚类,平衡计算复杂度和聚类效果。
创新点
-
动态视觉 Token:生成具有灵活形状和大小的动态 Token,更好地表示图像的语义信息。
多尺度特征聚合:通过多阶段聚合模块,有效融合多尺度特征,提升模型性能。
计算效率:本地聚类方法显著降低计算复杂度,例如 TCFormerV2-Small 在 ImageNet-1K 数据集上的 GFLOPs 为 44.4,而 TCFormerV1 的 GFLOPs 为 92.4。
性能提升:在多个视觉任务上优于传统卷积网络和 Transformer 模型,例如在 ADE20K 数据集的语义分割任务上,TCFormerV2-Base 的 mIoU 为 52.8%,而 Swin-S 的 mIoU 为 51.3%。
论文3:
Transformer-Based Hierarchical Clustering for Brain Network Analysis
基于 Transformer 的脑网络分层聚类
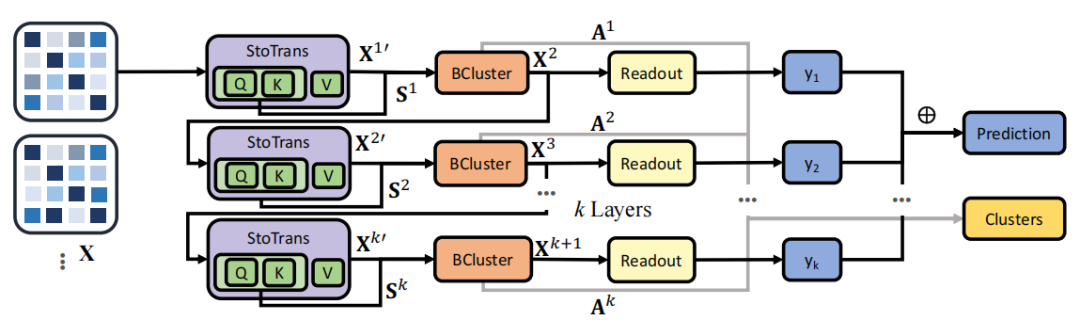
方法
-
变分自编码器:使用变分自编码器进行脑网络的表示学习。
注意力机制:通过注意力机制捕获脑网络中节点之间的全局依赖关系。
分层聚类:通过分层聚类方法,学习脑网络的分层社区结构。
聚类损失函数:设计特定的损失函数,鼓励模型学习具有高内聚性和低耦合性的社区结构。
创新点
-
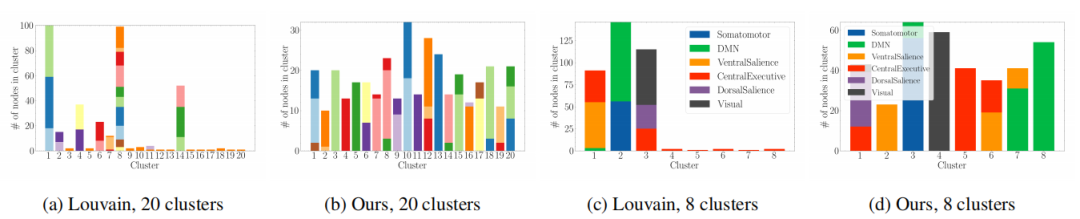
分层社区结构:揭示脑网络的分层社区结构,提供对脑功能模块的深入理解。
注意力机制:通过注意力机制捕获节点之间的全局依赖关系,提高模型的表达能力和预测性能。
计算效率:通过分层聚类和注意力机制,降低模型的计算复杂度,例如 THC 模型在 ABCD 数据集上的运行时间为 27.31 分钟,而 SAN 模型的运行时间为 908.05 分钟。
性能提升:在脑网络分类任务上,THC 模型的 AUROC 为 79.76%,显著高于其他基线模型,例如 SAN 模型的 AUROC 为 71.3%。
论文4:
USP A Unified Sequence Parallelism Approach for Long Context Generative AI
USP:一种用于长上下文生成式 AI 的统一序列并行方法
方法
-
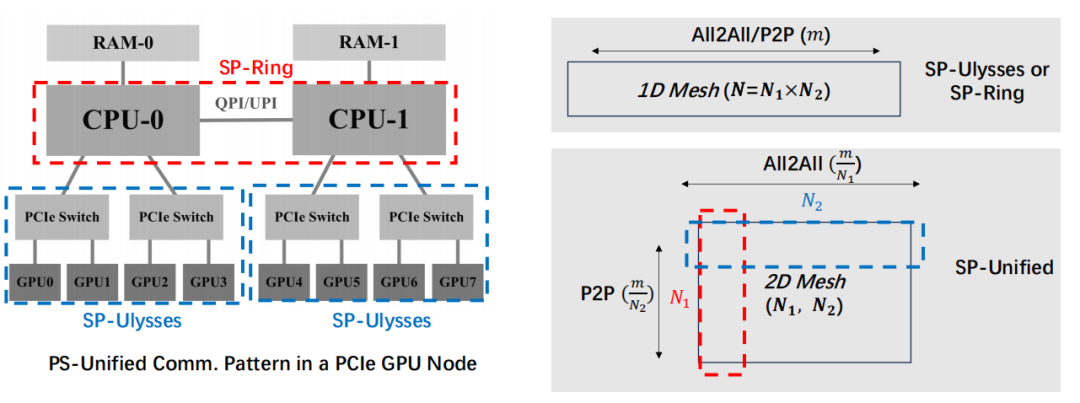
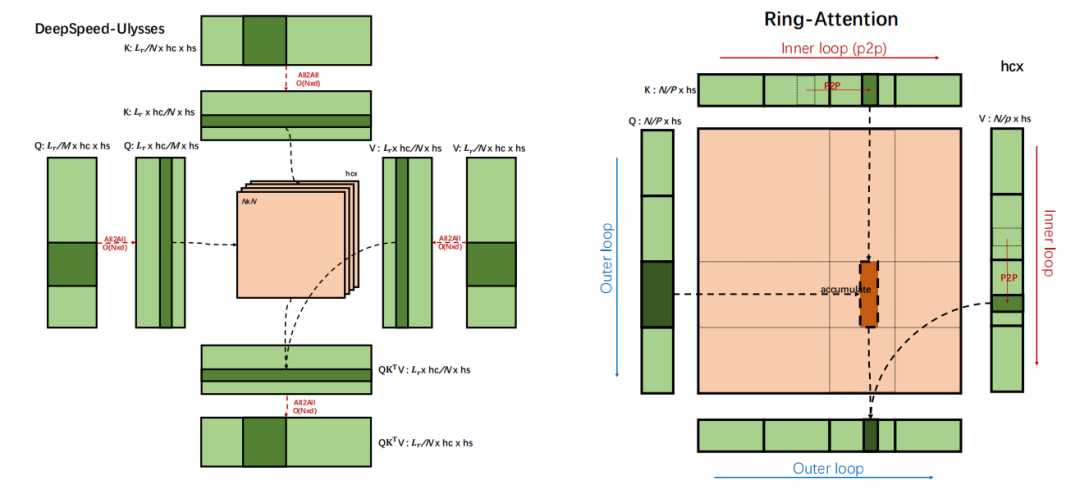
统一序列并行方法:结合 DeepSpeed-Ulysses 和 Ring-Attention 的优点,提出统一的序列并行方法。
混合并行策略:通过混合 Ulysses 和 Ring 并行策略,提高模型的计算效率和通信效率。
负载均衡:通过重新排序输入序列,解决 Ring-Attention 的负载不均衡问题。
4D 混合并行:分析序列并行与其他并行方法的关系,设计 4D 混合并行系统。
创新点
-
统一序列并行:整合 DeepSpeed-Ulysses 和 Ring-Attention,提高模型的鲁棒性和计算效率。
混合并行策略:通过混合 Ulysses 和 Ring 并行策略,提高模型的通信效率,例如在 8xA800 节点上,USP 的 MFU 达到 47%,而 DeepSpeed-Ulysses 的 MFU 为 36.26%。
负载均衡:通过重新排序输入序列,解决 Ring-Attention 的负载不均衡问题,提高模型的计算效率。
4D 混合并行:设计 4D 混合并行系统,提高模型的扩展性和计算效率,例如在两个 8xA800 节点上,USP 的 FLOPS/GPU 达到 158.64 TFLOPS,而 DeepSpeed-Ulysses 的 FLOPS/GPU 为 141.20 TFLOPS。
小编整理了聚类+transformer论文代码合集
需要的同学扫码添加我
回复“ 聚类+transformer”即可全部领取


















 3033
3033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









